Blog
Three Database Performance Problems That In-memory Databases Resolve

Performance woes make cranky users – if they even stick around to use the software. Because if your software is too slow, it doesn’t matter how cool it is. Fortunately, in-memory databases solve a host of these problems.
Everyone expects real-time information and personalized online experiences, especially your customers and end users. The first way someone loses faith? The site is too slow. Or it takes too long to load data. Or any number of other annoyances that urge a user to click away, often to a competitor’s site.
If organizations deliver anything less than optimum performance, they lose customer loyalty. After only two to three bad customer experiences, 86% of consumers will leave a brand to which they were once loyal, reports customer experience vendor Emplifi, based on a global survey of 2,000 consumers.
That makes it an urgent requirement for developers to make online applications perform splendidly at scale. That can be a significant challenge; real-time data may be difficult to deliver when data requirements scale beyond expectations. And tuning the database isn’t always the answer.
There are lots of ways that database performance can suffer. These three top the list – and all of the problems are addressed with an in-memory database.
You have lots of customer data to manipulate
It’s hard to find an application where “meh, it’s okay” database access speed is acceptable. Nearly every application needs to respond instantly to customer requests– whatever “instantly” feels like to that user.
However, customer databases grow steadily in volume and table size, and traditional data management practices cannot keep up. “Big data” used to represent outliers in computer science, the behemoths of data collections, but yesterday’s “huge” database is today’s “ho-hum” collection. And as developers discover, extensive datasets—measured by volume, velocity, and/or variability—require a scalable architecture for efficient storage, manipulation, and analysis.
As customer databases grow, it becomes more difficult to query the database for a single unique identifier. The slow query performance hinders customer service. It also makes it harder to implement customer 360° initiatives that aim to provide an accurate, single customer view to everyone in the company and customers themselves. Slow database queries do not provide enough time for data manipulation in real-time to create insightful aggregate data views.
The Fix: Move customer lookup tables and other customer-related data tables to an in-memory database.
An in-memory database works like other databases, except all data is stored in DRAM rather than on a traditional disk. Data is periodically stored on disk for persistence and data restoration (if and when the need arises).
Performance is dramatically enhanced with in-memory databases because no time is expended writing to disk or retrieving from disk. Memory operations perform many times faster than disk-based drives, even much faster than newer NVMe or SATA solid-state disk drives.
In short: In-memory data queries have low latency, which means the code can scale. That means applications can search through tens of millions of customer records to find information related to a single customer and get the results in real-time.
The performance of search and query can change dramatically depending on the data operations performed. To learn how data operations affect the query performance of Redis vs. others, see this performance comparison blog post.
Queries are too slow for immediate analysis
Database performance extends beyond data retrieval to serve up customer records or to store transactions. Organizations use real-time database queries to support the analysis behind business metrics, such as project dashboards and troubleshooting alerts – any data presentation that enables better choices.
For analytics, the age of the data is directly related to its quality. Older, stale data is less valuable for real-time analysis and decision-making.
Bottlenecks causing query performance issues can occur anywhere along the data operations process flow. Database search and query operations are expensive in computational terms. It takes intensive resources to index and deliver search results.
Simultaneously ingesting data and querying disparate data structures (like Hash and JSON documents) is demanding. This is especially true for disk-based SQL databases such as Oracle and SQL Server. The typical answer is database performance tuning, but that goes just so far due to underlying database architecture and the type of database workloads.
The Fix: Employ a real-time search engine to deliver fast data results for analysis.
A real-time search engine queries and aggregates massive data sets with immediate results, which generates timely data for accurate analytics. Data scientists can then consume and analyze fresh data in dashboards, graphs, charts, or other applications.
I go into more detail about data search algorithms and the cool math and science behind it in my last post on Fuzzy Matching.
A real-time search engine provides:
- Performance to deliver sub-millisecond search and query results for accurate analysis
- Power to scale search and query of massive data sets with instant results
- A small resource footprint that is microservice framework friendly
This graphic depicts the consolidation of data from multiple sources of record into one real-time search engine to provide timely data for analytics and new business insights:
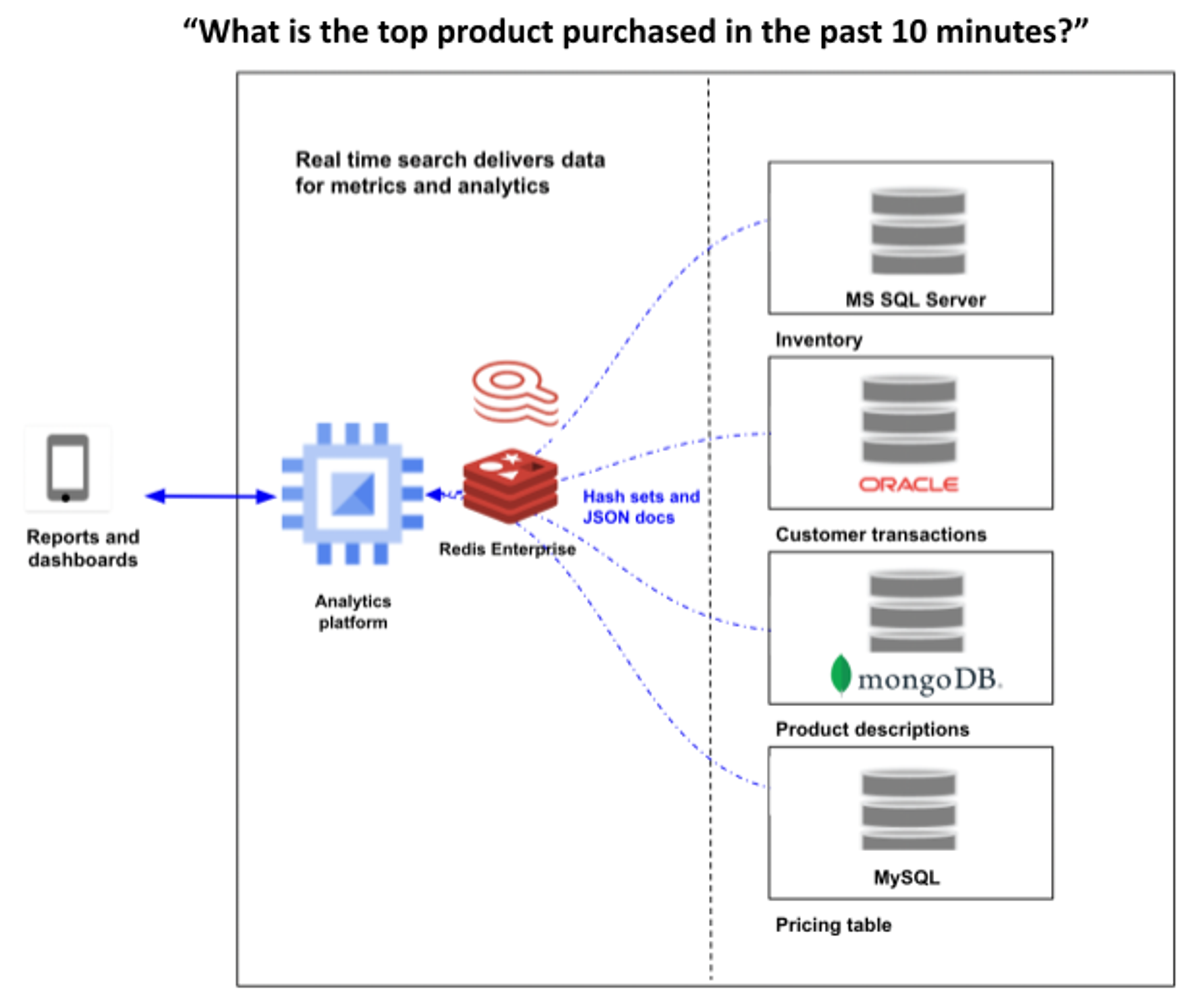
Online search is too slow
Another common database issue is performing repetitive lookups on massive master data tables. Master data tables help define important database entities in the database, usually representing its foundation: product, partners, vendors, and orders. As with any other data management element, these grow as the company grows.
Performance issues arise when databases repetitively perform large master data table lookups when the master data tables reach millions of primary or secondary key values. The common symptom is noticeably slow user search or delayed application page rendering, particularly when searching massive product databases for e-commerce sites.
The Fix: Distribute the data ingest, index, and query loads across database partitions or shards and use secondary indexes.
Geo-distributed database topologies can scale master data tables to tens of millions of primary and secondary keys. This enables powerful search auto-suggestion and flexible category-based (faceted) search capabilities providing instant search results for online customers and business users. Distributing both reads and writes across multiple database partitions or shards enables a massive scale of master data tables and high-performance search results.
Secondary indexes are non-primary key indexes created to provide a rapid lookup of data. Their search results may contain duplicate values, such as finding all the products with a manufacturer listed as “Apple.” Secondary indexing of databases allows for flexible and rapid search of master data tables in any database field. You can create thousands of indexes for a single record or hundreds of thousands across an entire database. And the database provides automatic index management once the index is created.
We provide more depth elsewhere on secondary indexing and sorted sets.
Redis Enterprise can meet your real-time search requirements
Redis Enterprise provides a powerful indexing, querying, and full-text search engine for real-time data, available on-premises and as a managed service in the cloud. The Redis search engine can be used for real-time customer aggregations, as a secondary index for data hosted in Redis, to consolidate data from other data stores for analytics, and act as a fast full-text search or auto-complete engine.
And – this won’t surprise you, given the points above – the Redis Enterprise real-time search engine overcomes common database performance problems:
- You have lots of customer data to manipulate
- Queries are too slow for immediate analysis
- Online search is too slow
Put Redis into action
We hope this piques your interest in learning more and discovering whether Redis Enterprise is a good fit for your needs. Certainly, we have plenty of information available to help you learn more, such as a webinar on data ingestion, a webpage about real-time search, and a video that teaches how to create secondary indexes.
Now is the time to discover the power of real-time search. Speak to a Redis expert or download Redis Enterprise for free. Get started today and deliver valuable fresh data to your customers and business partners with Redis Enterprise’s real-time search capabilities.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.