
Full Colab NoteBook on Github.
Evaluating information retrieval (IR) systems is essential for informed design decisions and understanding system performance. Successful companies like Amazon and Google rely heavily on IR systems, with Amazon attributing over 35% of sales and Google 70% of YouTube views to their recommender systems. Effective evaluation measures are key to building and refining these systems.
Here, we will use Normalized Discounted Cumulative Gain (NDCG@K) to evaluate the performance of both the base model and the fine-tuned model, assessing whether the fine-tuned model outperforms the base model.
Redis vector database will serve as a persistent store for embedding and RedisVL as a python client library.
What is Normalized Discounted Cumulative Gain?
Normalized Discounted Cumulative Gain (NDCG) evaluates retrieval quality by assigning ground truth ranks to database elements based on relevance. For example, highly relevant results might rank 5, partially relevant ones 2–4, and irrelevant ones 1. NDCG sums the ranks of retrieved items but introduces a log-based penalty to account for result order. Irrelevant items ranked higher incur greater penalties, ensuring the system rewards placing relevant items earlier in the results.
NDCG improves upon Cumulative Gain (CG) by accounting for the importance of rank positions, as users prioritize top results. It uses a discount factor to give higher weight to top-ranked items.
To calculate NDCG:
- DCG (Discounted Cumulative Gain): Sum relevance scores with a log-based discount for lower-ranked items.
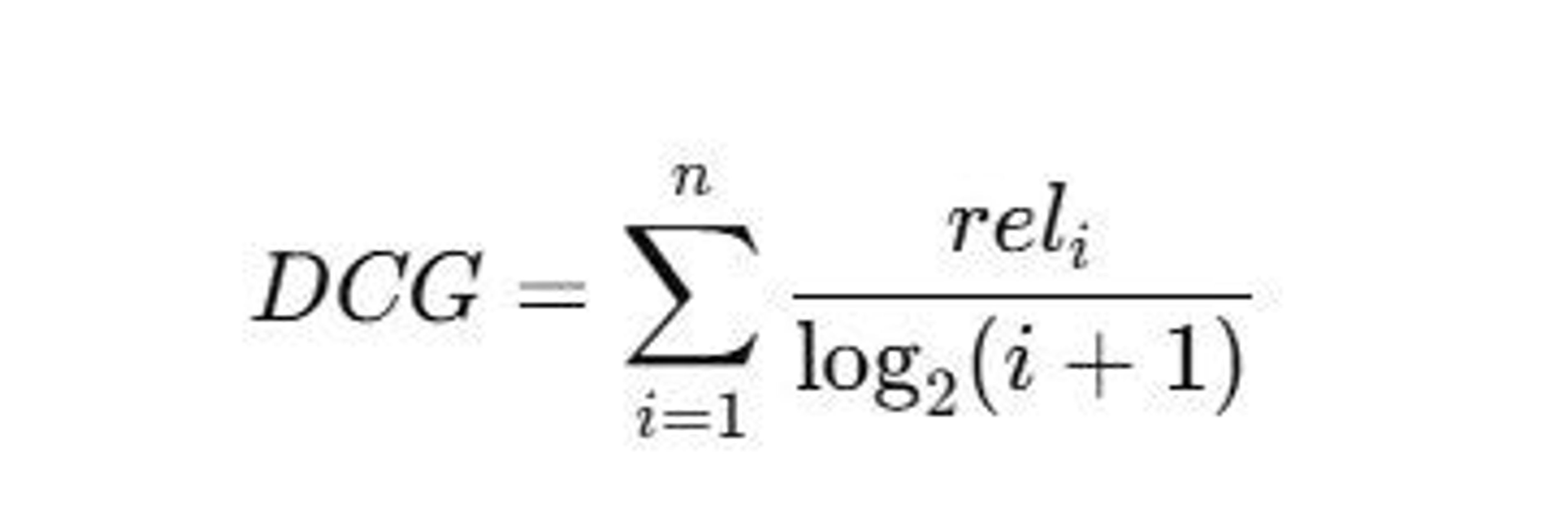
– rel i: Relevance score of the document at position i.
– i: Rank position of the document (1-based index).
– log2(i+1): Discount factor that reduces the impact of lower-ranked items.
- IDCG (Ideal DCG): Compute DCG for the ideal ranking (highest relevance first).
- NDCG: Normalize DCG by dividing it by IDCG, ensuring a score between 0 and 1, where 1 indicates perfect ranking. If IDCG is 0, NDCG is set to 0.
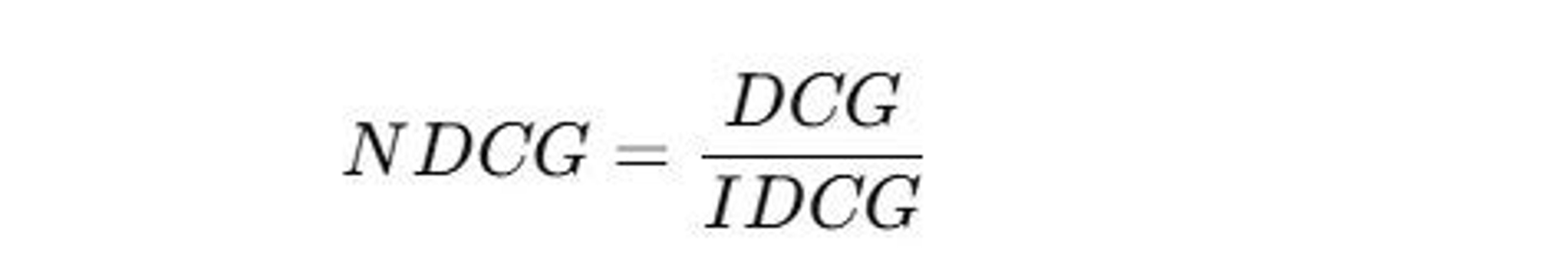
How to define relevance scores
Relevance scores quantify how useful a retrieved item is for a given query. Scores can be defined based on the importance of the result:
- Graded relevance (This can be customized to your problem):
- Top 1 position: Score = 3 (Highly relevant).
- Top 2 or 3 positions: Score = 2 (Moderately relevant).
- Top 4 or 5 positions: Score = 1 (Barely relevant).
- Beyond top 5: Score = 0 (Not relevant).
Why use graded relevance?
Graded relevance captures varying degrees of relevance, offering richer feedback for evaluating rankings. It reflects that some results may be useful but not perfect, while others are completely irrelevant.
Let’s get back to our steps to calculate NDCG.

Step-by-step NDCG calculation

Why use NDCG?
- Position sensitivity: Emphasizes higher-ranked items, aligning with user behavior.
- Graded relevance: Supports varying relevance levels, enhancing versatility.
- Comparability: Normalization enables comparison across queries or datasets.
Limitations of NDCG:
- Complexity: Relies on subjective and challenging-to-obtain graded relevance judgments.
- Bias toward longer lists: Sensitive to the length of ranked lists during normalization.
Redis vector database & NDCG@10 calculation
The objective is to compute embeddings for all answers using both the base and fine-tuned embedding models and store them in two separate vector indexes. These embeddings will be used to retrieve answers based on the corresponding questions. After retrieval, the NDCG@K score will be calculated for both sets of embeddings to evaluate their performance.
Setting up Redis vector database with udocker in Colab

Calculate NDCG for BGE base model:
Download BGE base model (BAAI/bge-base-en-v1.5) from Huggingface
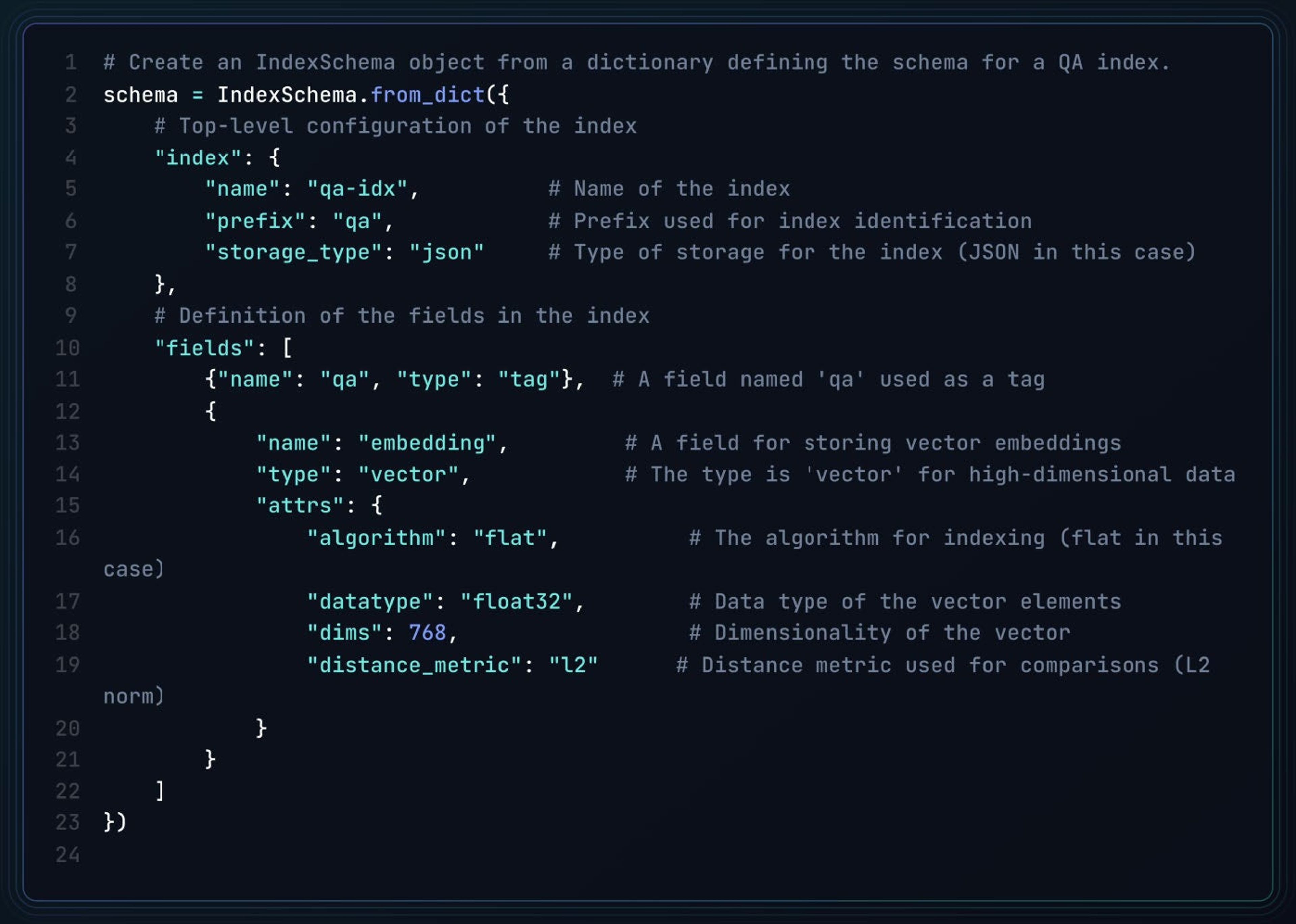
The following code defines a schema for an index with two fields: a “tag” field (qa) and a “vector” field (embedding) configured for high-dimensional data search with specified attributes like algorithm, data type, dimensionality, and distance metric.
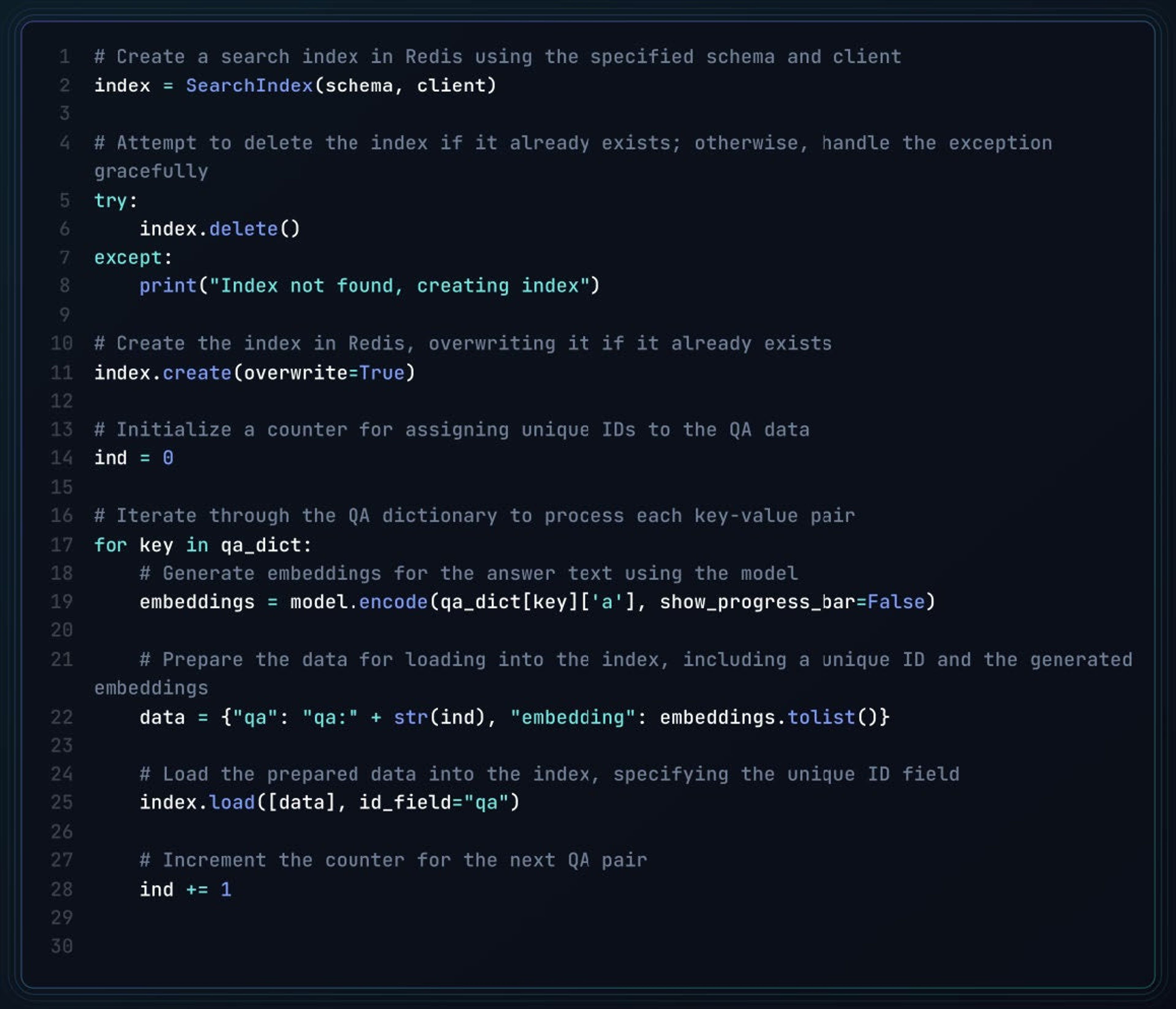
The following script creates a Redis index, processes QA pairs by generating vector embeddings for the answers, and loads the data into the index for search and retrieval.
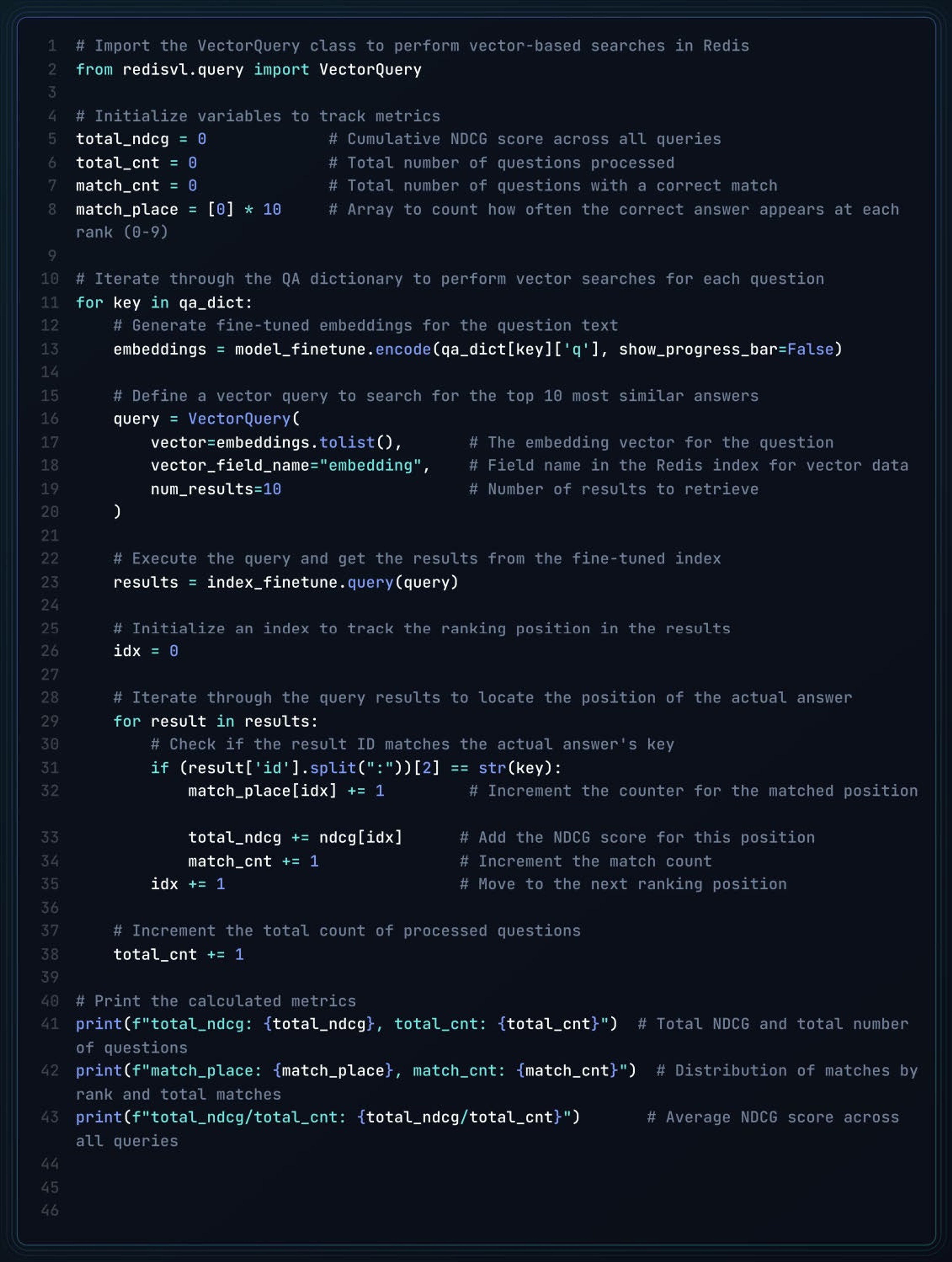
The following script performs vector searches for each question in the QA dataset, calculates metrics like NDCG scores and match rankings, and tracks how often the correct answer is found at each position in the results. The final output includes key metrics for evaluating the model’s performance.
Here’s a summary of the results:
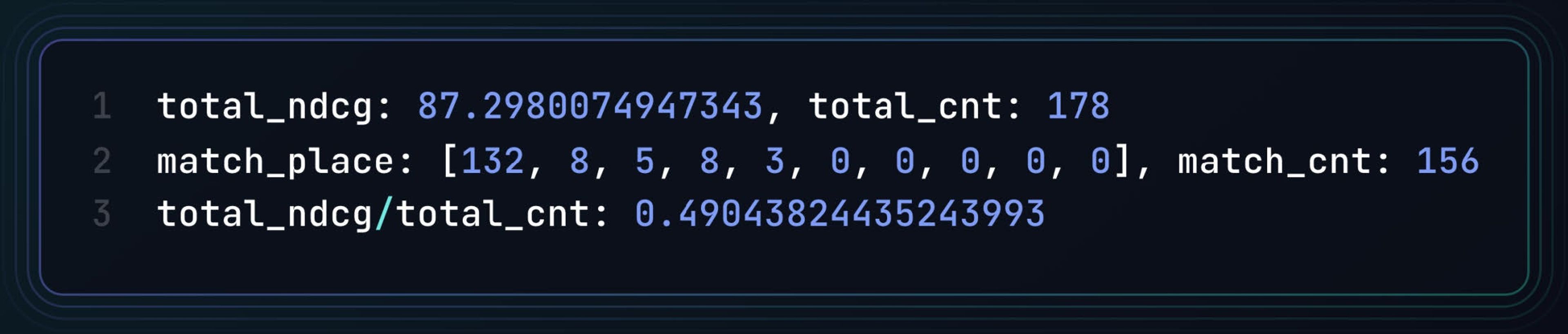
- Total NDCG score: 87.30
- Total questions processed: 178
- Match distribution by rank:
Rank 1: 132 matches
Rank 2: 8 matches
Rank 3: 5 matches
Rank 4: 8 matches
Rank 5: 3 matches
Ranks 6-10: 0 matches each
- Total Matches: 156
- Average NDCG per Query: 0.49
This indicates that the model performs relatively well, with the correct answer being frequently ranked highly (e.g., 132 times in the top position), but the performance drops significantly in the lower ranks. The average NDCG score is 0.49, suggesting room for improvement.
Calculate NDCG for BGE fine-tuned model:
Download BGE fine-tuned model (rezarahim/bge-finetuned-detail) from Huggingface.
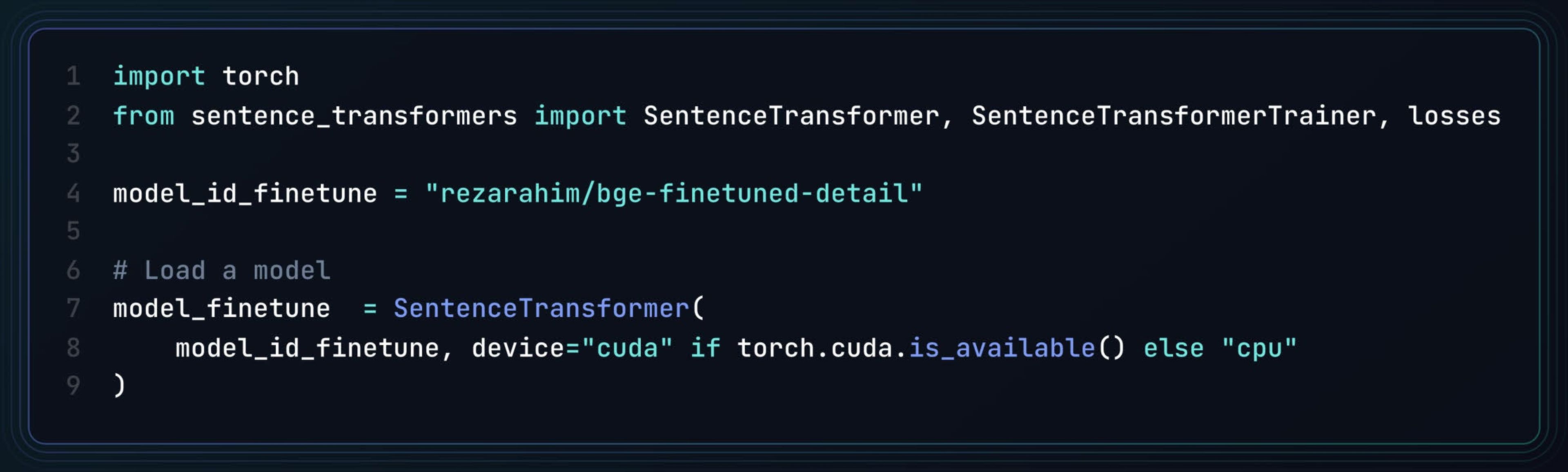
Detail of this portion of the code can be found in the notebook.
Here’s a summary of the fine-tuned model results:
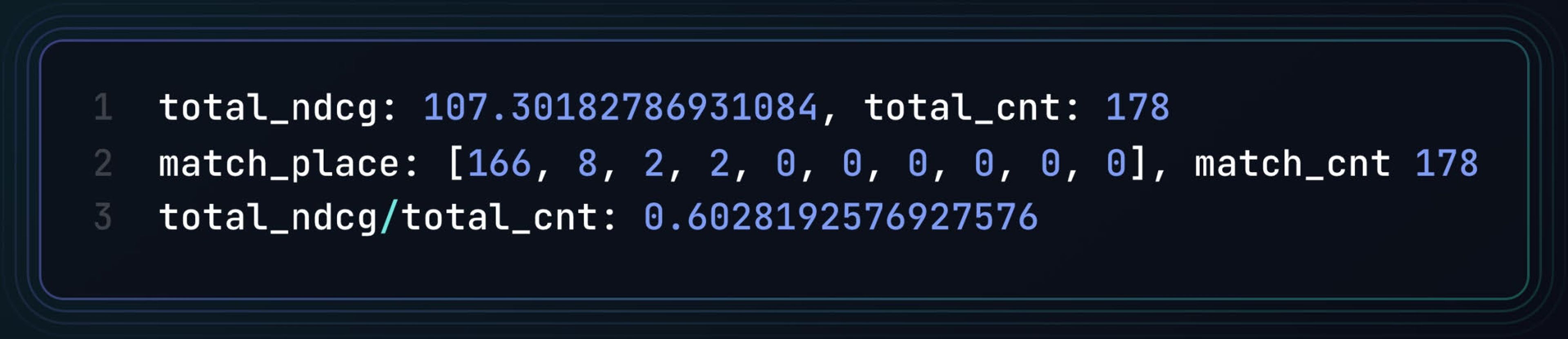
Here’s a summary of the updated results:
- Total NDCG score: 107.30
- Total questions processed: 178
- Match distribution by rank:
Rank 1: 166 matches
Rank 2: 8 matches
Rank 3: 2 matches
Rank 4: 2 matches
Ranks 5-10: 0 matches each
- Total matches: 178 (matches every question, 100% accuracy)
- Average NDCG per query: 0.60
This marks a clear improvement over previous results. The fine-tuned model frequently places the correct answer in the top rank (166 times) and achieves an average NDCG score of 0.60, showing better ranking performance and overall accuracy.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.