
To build an effective question-answering system like RAG for finance, you need a model that understands the industry’s vocabulary. Generic embedding models often lack the domain-specific knowledge necessary for accurate information retrieval.
That’s where fine-tuning comes in. Training domain-specific embedding models with finance datasets or using pre-trained models built for financial text helps the system retrieve accurate, relevant information based on user queries.
Getting an embedding model to truly understand specialized fields like medicine, law, or finance takes more than off-the-shelf solutions. This guide walks through fine-tuning with domain-specific datasets to capture nuanced language patterns and concepts. The payoff is more accurate retrieval and stronger NLP performance in your field.
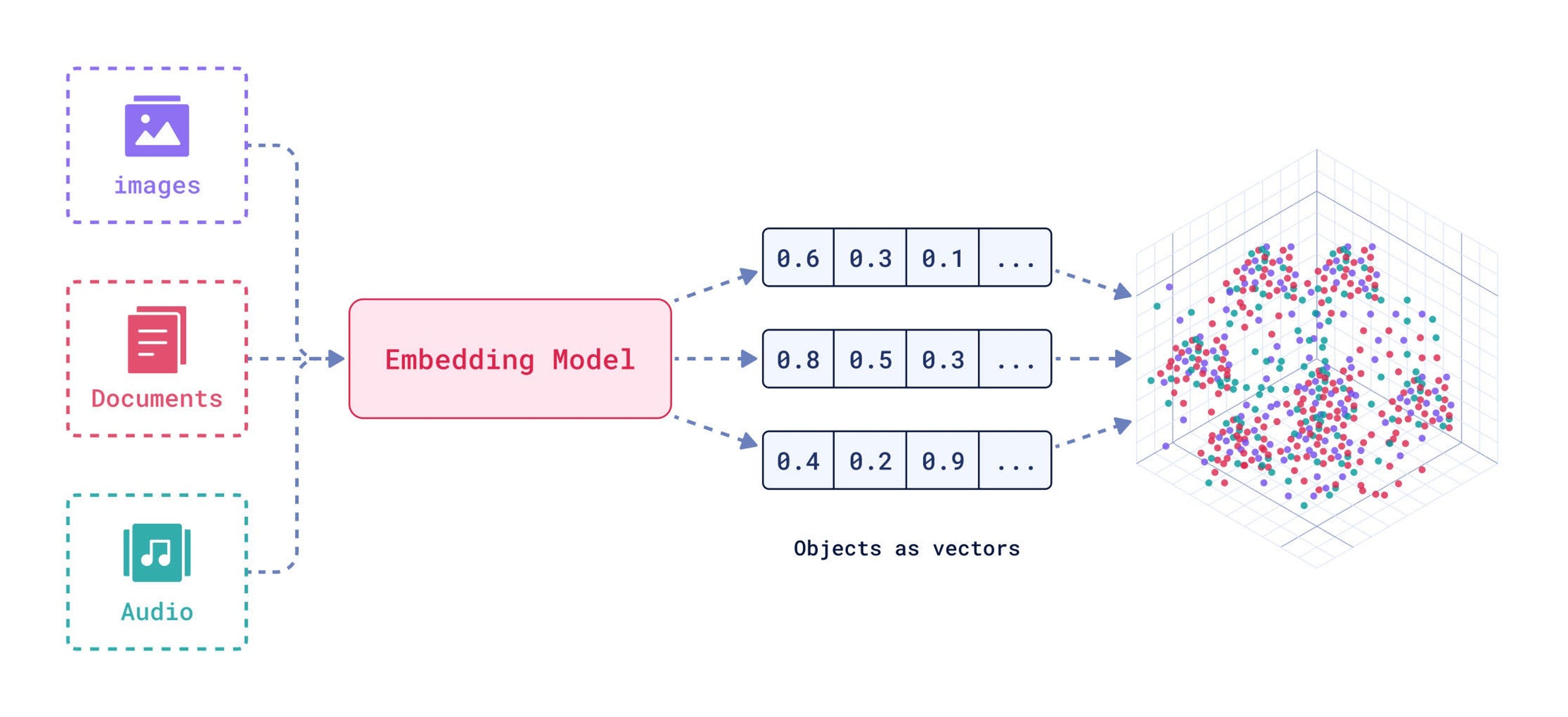
Embeddings as vectors
Embeddings are numerical representations of text, images, or audio that capture semantic relationships by mapping them into a multi-dimensional space. In this space, similar items (e.g., words or phrases) are positioned closer together, reflecting their semantic similarity, while dissimilar items are farther apart. This structure makes embeddings powerful for tasks like natural language processing, image recognition, and recommendation systems.
Embeddings are essential for many NLP tasks like :
- Semantic similarity: measuring how closely related two texts or images are.
- Text classification: categorizing data based on its meaning.
- Question answering: identifying the most relevant document to answer a query.
- Retrieval-augmented generation (RAG): enhancing text generation by combining embedding models for retrieval with language models.
Bge-base-en
The BAAI/bge-base-en-v1.5 model, developed by the Beijing Academy of Artificial Intelligence (BAAI), is a versatile text embedding model excelling in NLP tasks. It performs well on benchmarks like MTEB and C-MTEB and is particularly suitable for apps with limited computing resources.
Why fine-tune embeddings?
Fine-tuning an embedding model for a specific domain enhances retrieval-augmented generation (RAG) systems by aligning the model’s similarity metrics with domain-specific context and language. This improves the retrieval of relevant documents, resulting in more accurate and contextually appropriate responses.
Dataset formats: Building the foundation for fine-tuning
- Positive pair: a pair of related sentences, such as questions and their corresponding answers, that are similar to each other.
- Triplets: a set of three elements—an anchor, a positive, and a negative—where the anchor is similar to the positive but dissimilar to the negative.
- Pair with similarity score: a pair of sentences accompanied by a similarity score that quantifies their relationship.
- Texts with classes: a text paired with its corresponding class label, indicating its category or classification.
Loss functions: Guiding the training process
Loss functions are essential for training embedding models, as they measure the difference between the model’s predictions and actual labels, guiding weight adjustments. Different loss functions are suited to various dataset formats:
- Triplet loss: used with (anchor, positive, negative) triplets to position similar sentences closer together and dissimilar ones farther apart.
- Contrastive loss: applied to positive and negative pairs, encouraging similar sentences to be close and dissimilar ones to be distant.
- Cosine similarity loss: used with sentence pairs and similarity scores, aiming to align cosine similarities with the provided scores.
- Matryoshka loss: a specialized loss function for creating truncatable Matryoshka.
- MultipleNegativesRankingLoss: a great loss function if you only have positive pairs, for example, only pairs of similar texts like pairs of paraphrases, pairs of duplicate questions, pairs of (query, response), or pairs of (source_language, target_language).
Code example
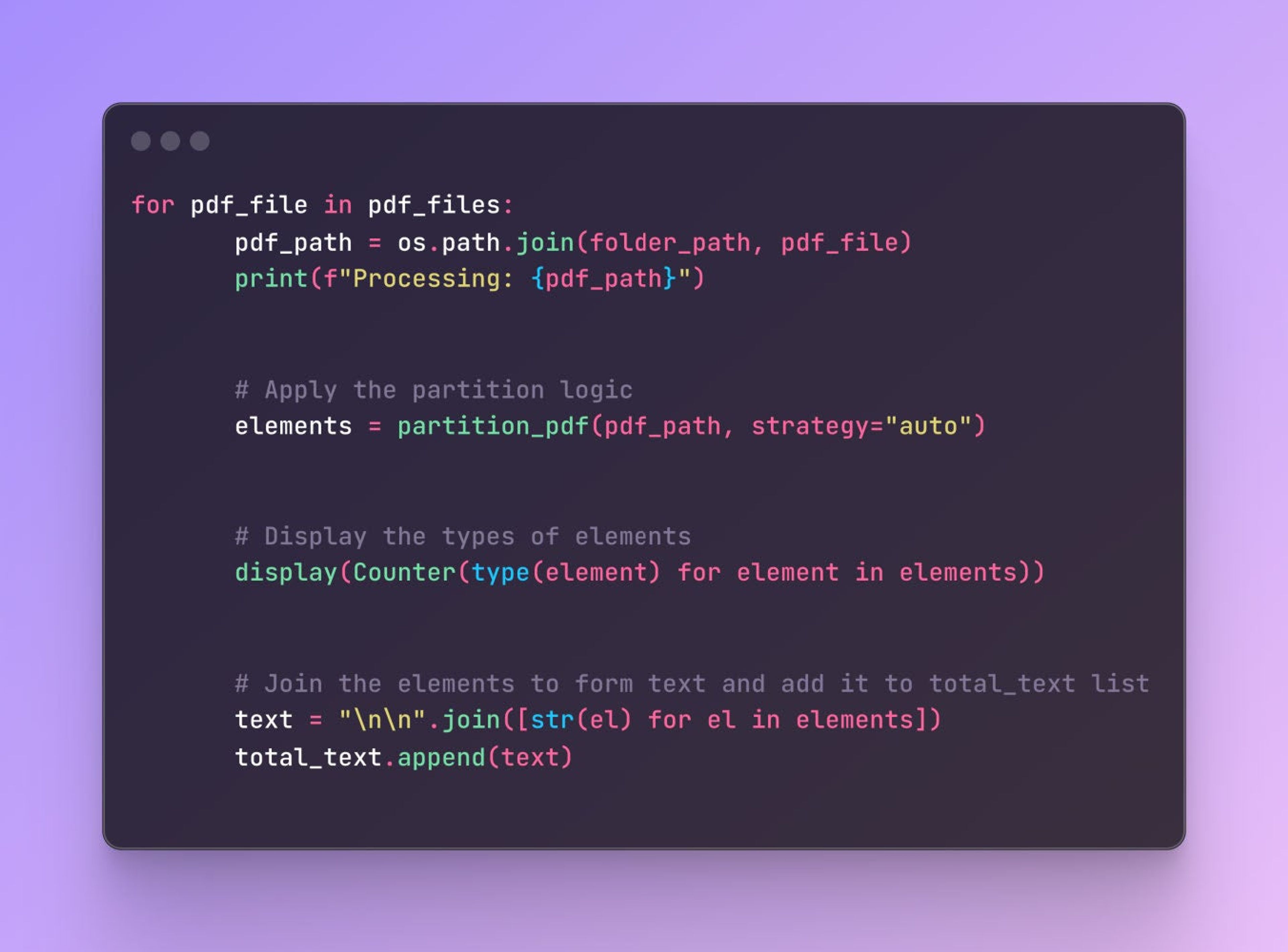
We’ll use the unstructured library to extract text and tables from PDF files.
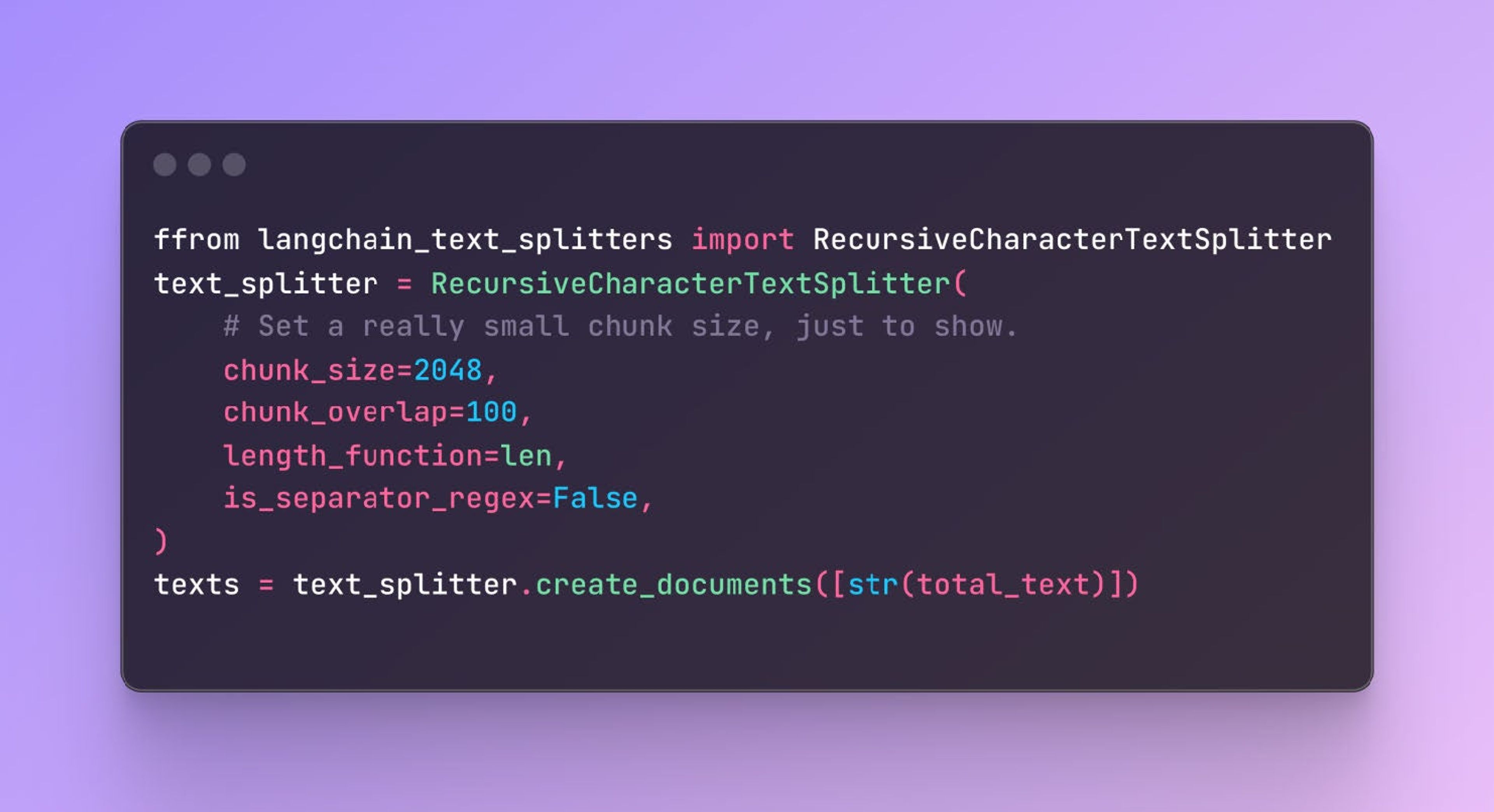
Break the extracted text into manageable chunks using LangChain. This is essential for making the text more suitable for processing by the LLM.
Synthetic dataset generation
Create a prompt for the Hugging Face Llama model that asks for a question-answer pair based on a given text chunk.
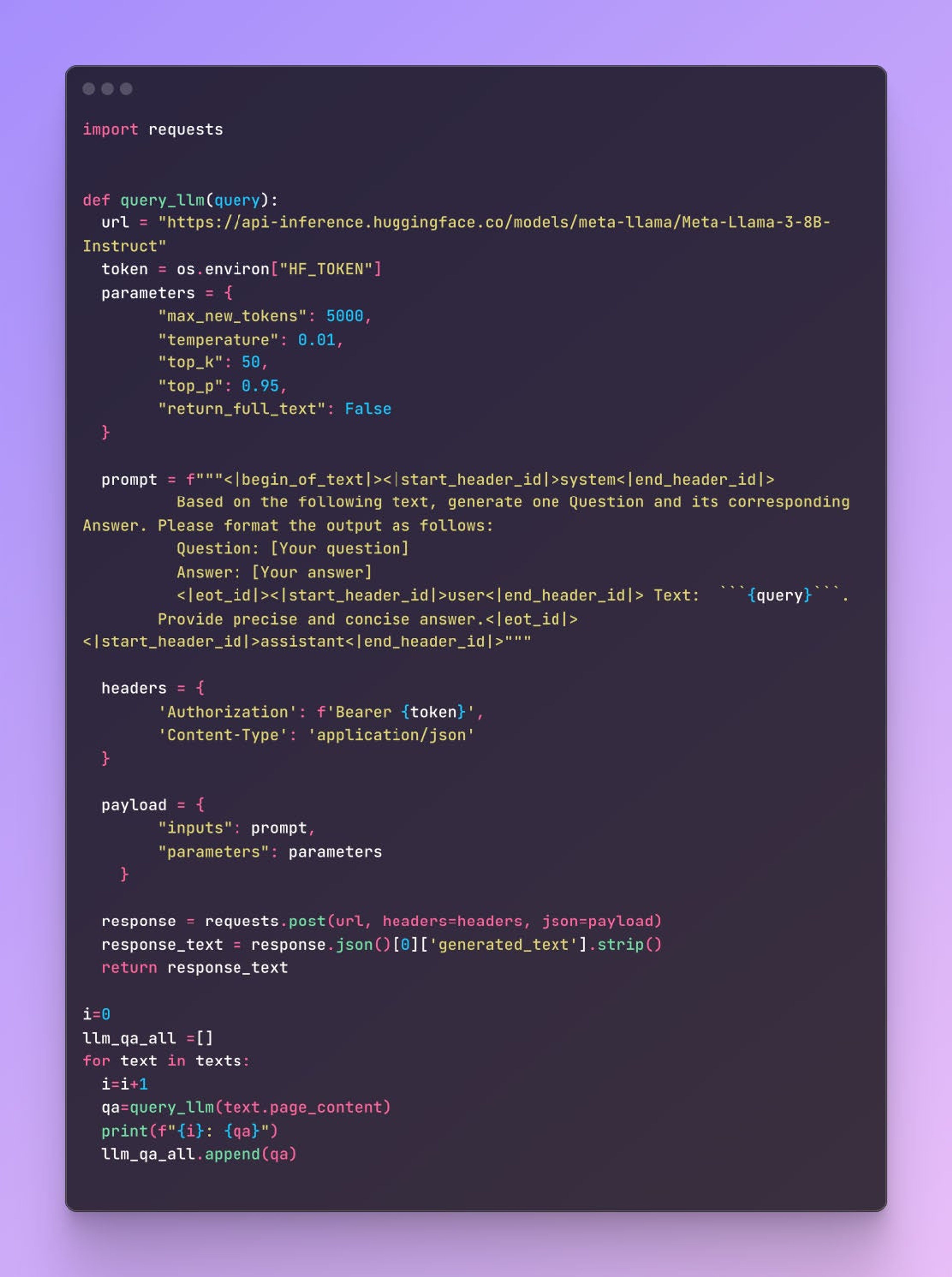
Sample response from LLM
Question: What is the filing date of the 10-K report for NVIDIA Corporation in 2004?
Answer: The filing dates of the 10-K reports for NVIDIA Corporation in 2004 are May 20th, March 29th, and April 25th.
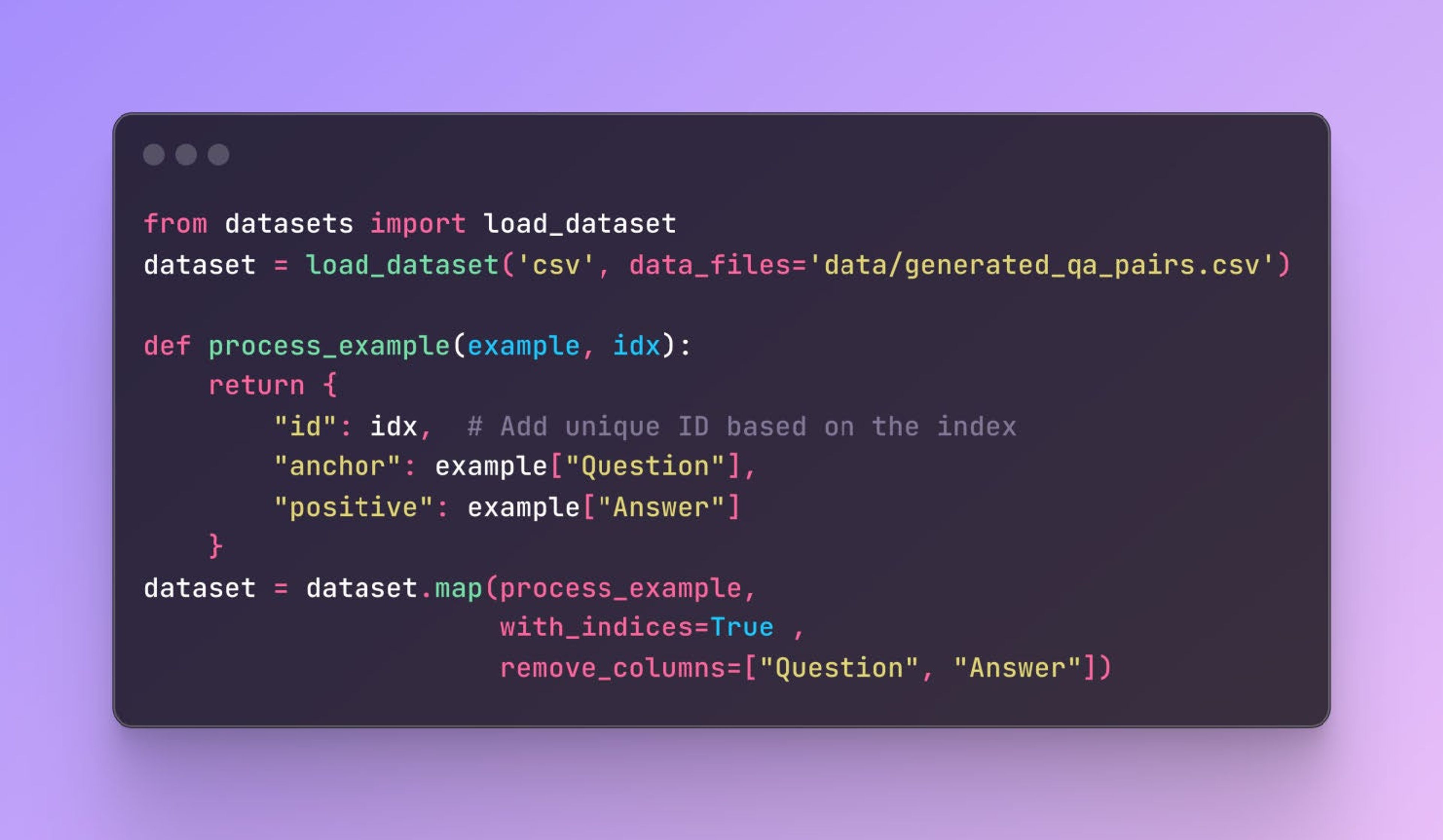
Next, load the generated QA pairs from the CSV file into a HuggingFace dataset. We make sure the data is in the correct format for fine-tuning.
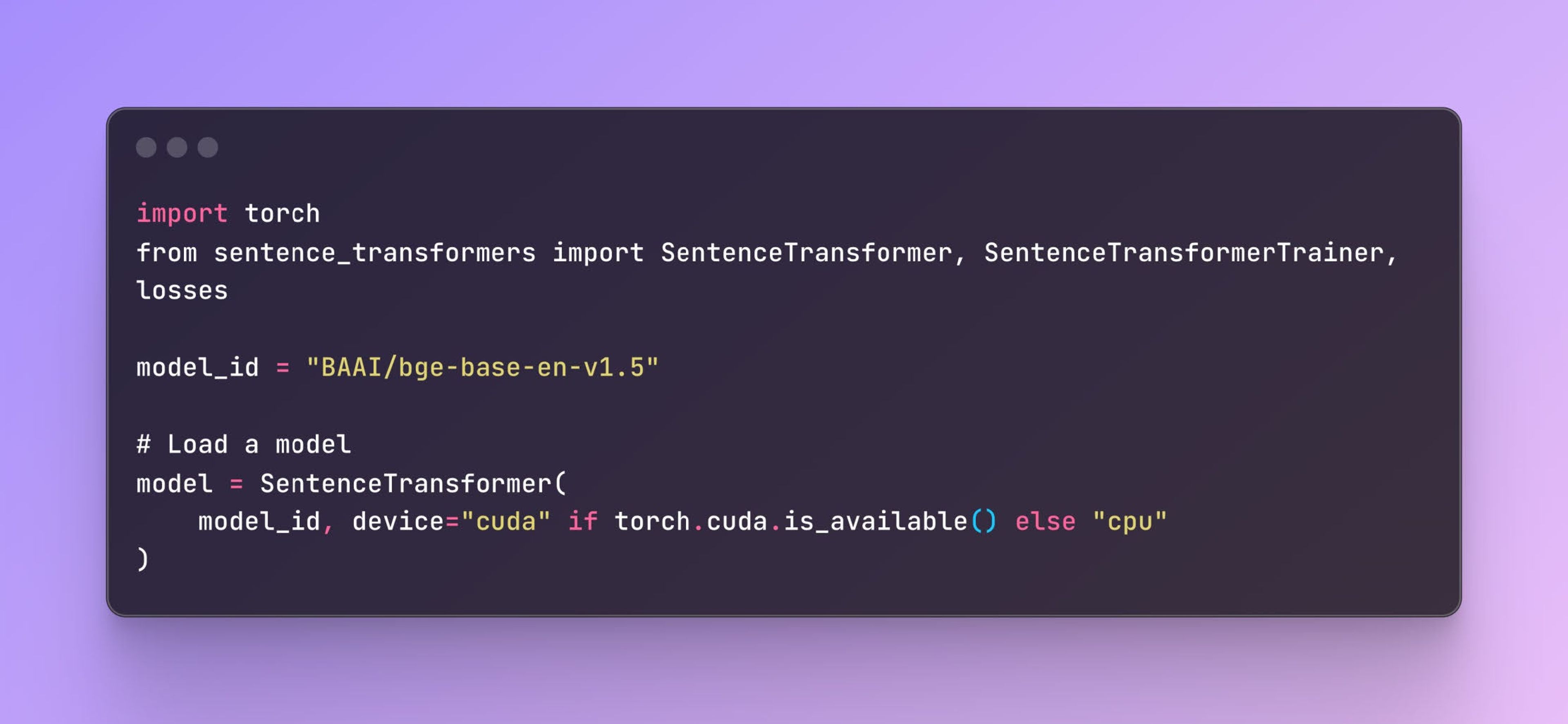
Load bge-base-en-v1.5 from Huggingface ( BGE: One-Stop Retrieval Toolkit For Search and RAG ) with sentence_transformers.
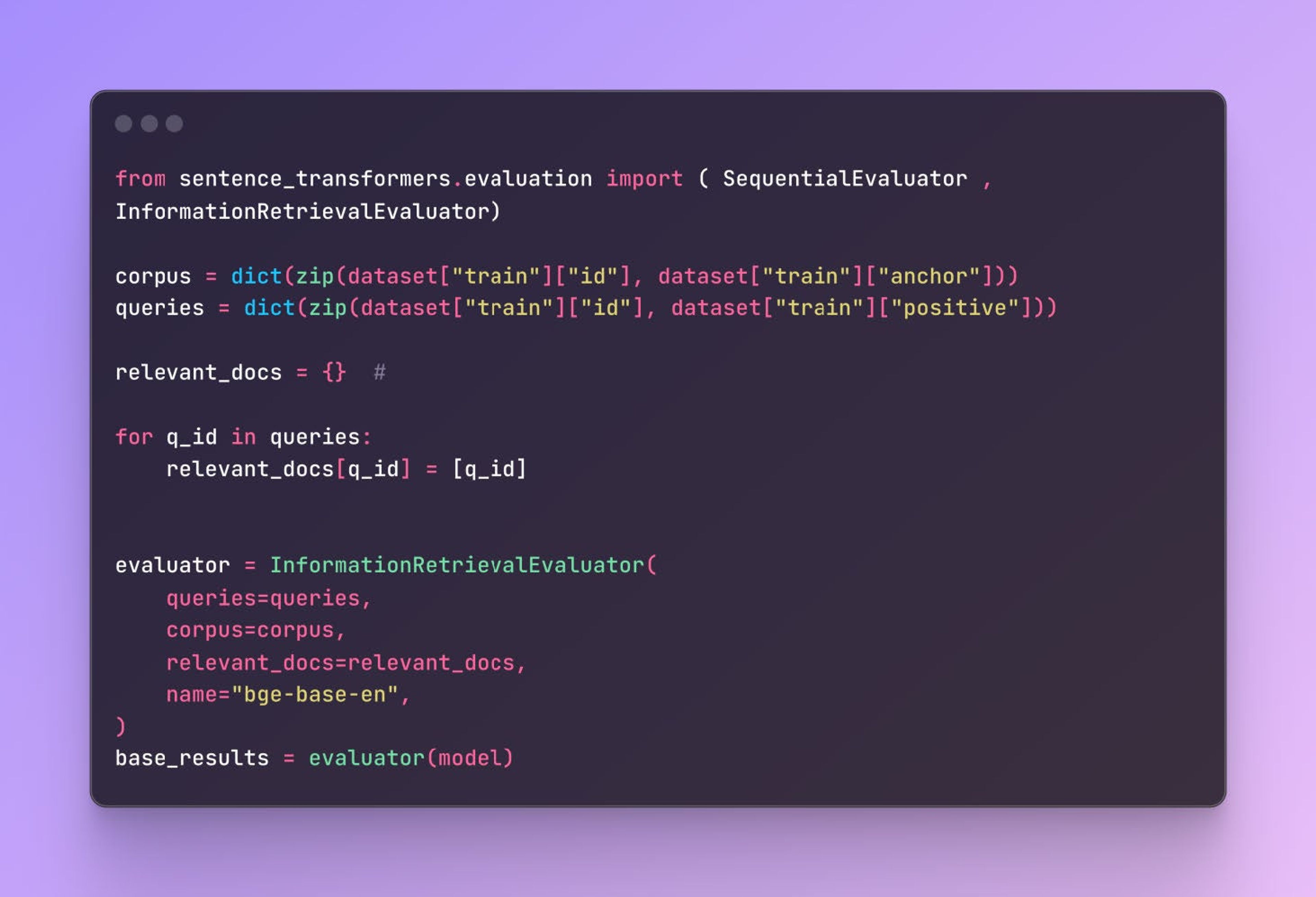
Create an InformationRetrievalEvaluator evaluator to measure the model’s performance during training. The evaluator assesses the model’s retrieval performance using InformationRetrievalEvaluator.
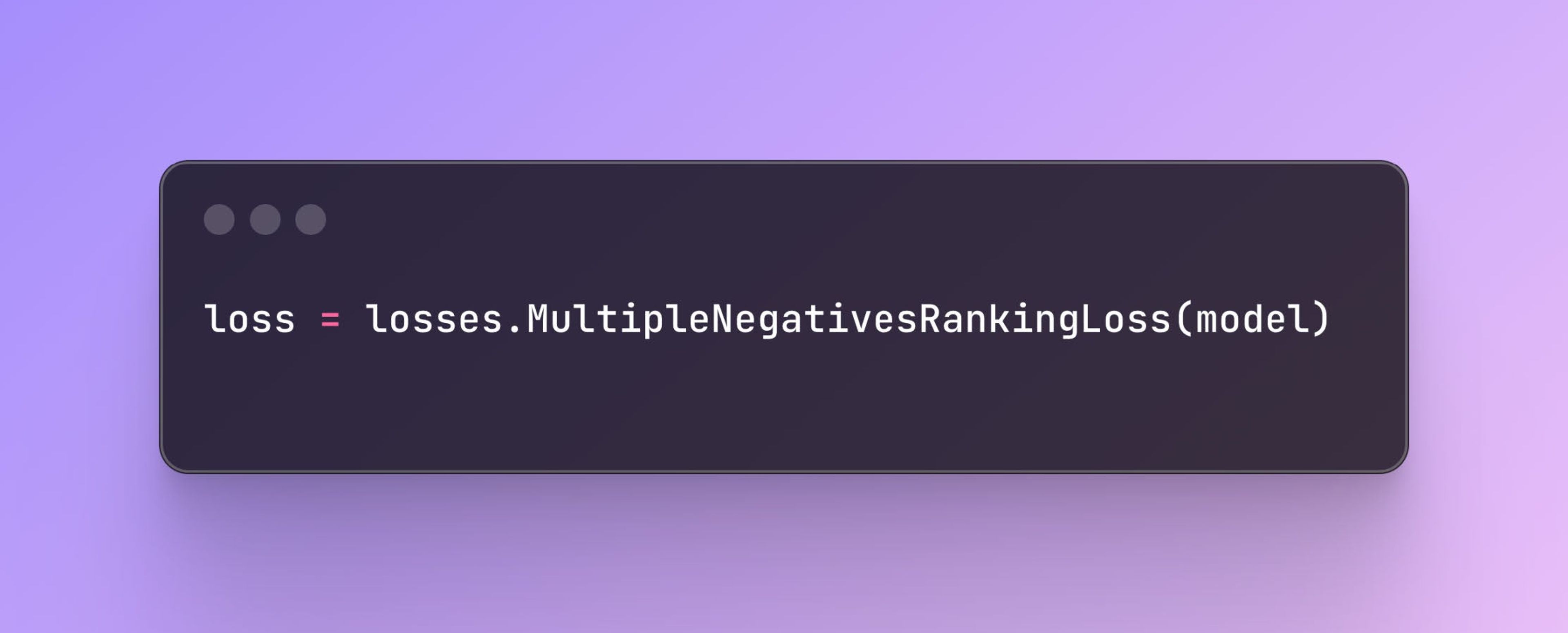
The loss function, MultipleNegativesRankingLoss, helps the model produce embeddings suitable for retrieval tasks.
Use SentenceTransformerTrainingArguments to define the training parameters. This includes the
- output directory,
- number of epochs
- batch size
- learning rate
- evaluation strategy
metric_for_best_model=”bge-base-en_dot_ndcg@10″, # Optimizing for the best ndcg@10 score for the 128 dimension
Create a SentenceTransformerTrainer object, specifying the model, training arguments, dataset, loss function, and evaluator
The trainer.train() method starts the fine-tuning process, updating the model’s weights using the provided data and loss function.

bge-base-en_dot_ndcg@10 metric before tuning 0.5949908809486526.
bge-base-en_dot_ndcg@10 metric after tuning 0.8245911858212284.
Fine-tuning an embedding model for your domain helps NLP apps better understand industry-specific language and concepts, making tasks like question answering, document retrieval, and text generation more accurate.
Practical techniques for building domain-specific embedding models include leveraging MRL and using powerful models like BGE-base-en. While fine-tuning is key, the quality and careful curation of your dataset are just as important for achieving the best results.
NLP is constantly evolving, with new embedding models and fine-tuning methods improving what’s possible. Staying on top of these changes and refining your approach will help you build smarter, more effective domain-specific applications.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.