Blog
Quantization and dimensionality reduction are now available in Redis Query Engine

Picture this—our AI app is crushing it. Users love your recommendations, your RAG system delivers spot-on answers, and your vector search is lightning fast. Then your Cloud Service Provider bill arrives. Your vector database alone is consuming $50,000 monthly in memory costs, and your CFO is asking uncomfortable questions about AI ROI. Sound familiar? You're not alone. According to CIO.com’s report 46% of 1,000-plus IT pros surveyed said the lack of predictability in pricing is a primary obstacle to implementing AI.
Today, we're announcing quantization that cuts your vector memory footprint by up to 37% while your app queries run faster than before. Redis is using combined strategies for quantization and dimensionality reduction based on our partnership with Intel, powered by Intel Scalable Vector Search technology (Intel SVS).
Lower your costs for Redis vector database by 37%
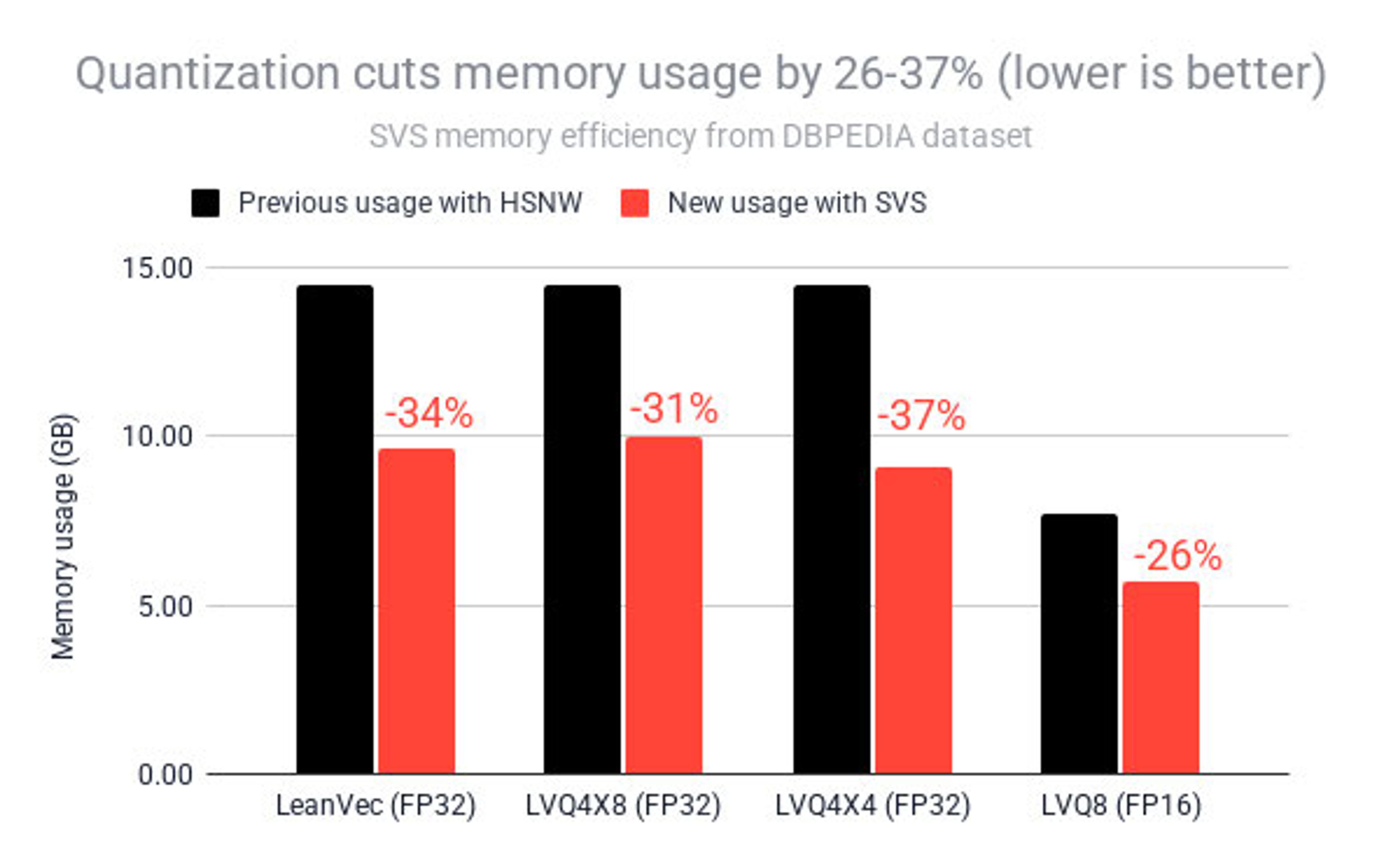
Our testing across diverse datasets shows consistent memory efficiency gains that translate directly to cost savings. The memory savings ranged from 26% to 37% total memory reduction, using different compression algorithms for LeanVec and LVQ. Comparing the vector index alone SVS-VAMANA with the existing HNSW implementation yields a memory gain of 51-74% in index memory reduction.
Improve search performance while keeping accuracy
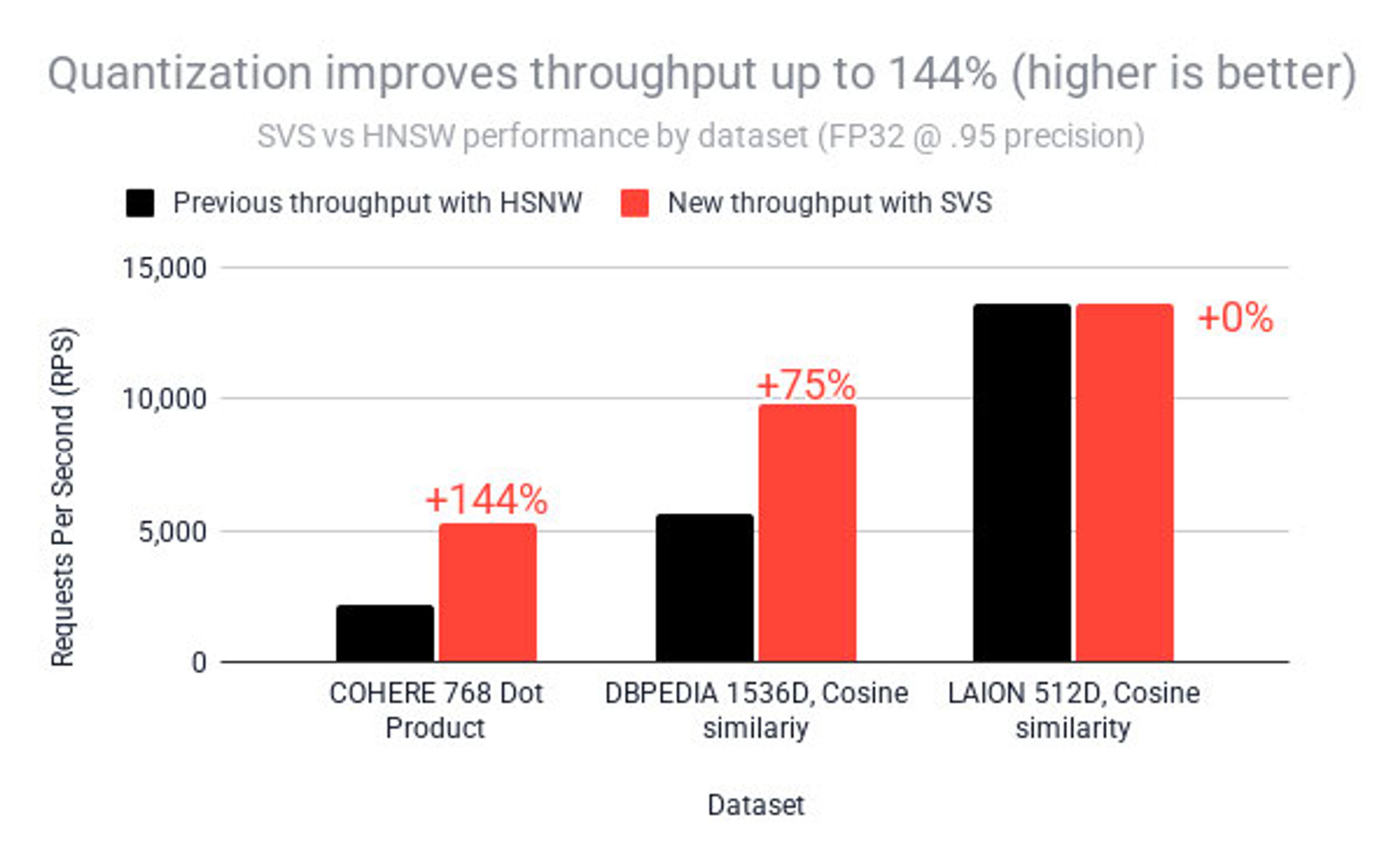
In terms of query throughput (QPS), the gains vary from 0% to 144% QPS, for FP32 datatype. The graph below showcases the gains and QPS considering the different embedding techniques, while keeping the precision of 0.95.
- COHERE, a 768 dimensions dataset, using dot product for the KNN queries: Excellent gains (up to 144% RPS improvement)
- DBPEDIA, a 1536 dimensions dataset, using cosine similarity for the KNN queries: Very good gains (up to 75% RPS improvement)
LAION, a 512 dimensions dataset, using cosine similarity for the KNN queries: Minimal gains (0-15% RPS, some degradation)
The savings are simple to implement
Your existing vector search queries continue to work exactly as before—same commands, same response times, same search accuracy. The compression happens behind the scenes in Redis Query Engine, so you get the cost benefits without any application changes.
When creating vector indices with FT.CREATE, you can now specify the new SVS-VAMANA algorithm along with compression options directly in your VECTOR field definitions.
Here's how simple it is to enable SVS compression:
The COMPRESSION parameter offers several LVQ and LeanVec variants optimized for different use cases. You can find more details about what compression is best suitable for your use case in our docs.
| Compression type | Best for | Memory savings vs. float32 | Search performance |
|---|---|---|---|
| Standard Scalar (fallback) | Fast search in most cases with low memory use | High (60%+) | Fast |
| LVQ4x4 | Fast search in most cases with low memory use | High (60%+) | Fast |
| LeanVec4x8 | Fastest search and ingestion | High (60%+) | Very Fast |
| LVQ4 | Maximum memory saving | Highest | Fast |
| LVQ8 | Faster ingestion than default | High (60%+) | Very Fast |
| LeanVec8x8 | Improved recall in case LeanVec4x8 is not sufficient | Medium | Fast |
| LVQ4x8 | Improved recall in case default is not sufficient | Medium | Moderate |
Your application code remains unchanged—the same search commands return the same high-quality results, just with dramatically improved memory efficiency. The compression happens transparently during indexing, and Redis Query Engine handles all the complexity of encoding, storage, and fast similarity computation.
Whether you're working with FLOAT16 or FLOAT32 vectors, compression is supported across both data types, giving you the flexibility to choose the precision that best fits your application requirements while still benefiting from the memory savings. If you want to understand more about the tradeoffs between different compressions, the impact on the embedding choice, and the performance for the different options, please check out the docs.
Per-vector compression saves on vector size
Understanding SVS-LVQ and SVS-LeanVec doesn't require diving into academic papers—the core concept is elegantly simple and powerful. Instead of using fixed-precision approaches like float16 that treat all vectors the same way, SVS-LVQ and SVS-LeanVec learn compressed representations that are optimized specifically for your data distribution.
The key idea behind LVQ is to apply per-vector normalization and scalar quantization, adapting the quantization bounds individually for each vector. This local adaptation ensures efficient use of the available bit range, resulting in high-quality compressed representations. LVQ introduces minimal decompression overhead, enabling fast, on-the-fly distance computations directly on compressed vectors. Its advantage lies in this balance. It significantly reduces memory bandwidth and storage requirements while maintaining high search accuracy and throughput, outperforming traditional methods.
LeanVec builds on top of LVQ by first applying linear dimensionality reduction, then compressing the reduced vectors with LVQ. This two-step approach significantly cuts memory and compute costs, enabling faster similarity search and index construction—especially for high-dimensional deep learning embeddings.
The compression gains are substantial. LVQ achieves a four-fold reduction of the vector size while maintaining search accuracy. A typical 768-dimensional float32 vector that usually requires 3,072 bytes can be reduced to just a few hundred bytes through this quantization process—that's where our 26-37% memory reduction comes from.
Get started saving today
The beauty of SVS-LVQ and SVS-LeanVec in Redis is that you don't need to become an expert in quantization theory to benefit from these optimizations. The system adapts to your data characteristics while providing consistent performance improvements across different embedding types and use cases. You get:
- Consistent Memory Savings: Across all embedding types, SVS-LVQ and SVS-LeanVec deliver 26-37% total memory reduction while maintaining recall@10 above 0.95 in all tested scenarios.
- Adaptive Performance: SVS-LVQ and SVS-LeanVec adjust to the characteristics of your specific embedding model, whether you're working with dense text representations or high-dimensional image features.
To learn more, read our docs
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.