Blog
What Serverless Databases as a Service Accomplish – and Why They Matter

We could lead with the technical advantages: flexible scaling, easier management of clusters and nodes, and offloading complicated resource analysis. But we know we can get your attention by saying Serverless Databases as a Service prevents overspending.
Selecting the right cloud database has become a progressively intricate challenge. To optimize performance and cost, developers must sift through a wide variety of instance types, determine the optimal number of cores, and consider a variety of pricing options.
The emergence of serverless Database as a service (SDBaaS) offers a promising resolution to these complexities. SDBaaS promises streamlined management, adaptable scaling, and cost-efficient operation. In particular, it can have a positive outcome on real-time use cases.
What is a serverless database as a service (SDBaaS)?
SDBaaS refers to cloud-based database services that eliminate the need for developers to manage clusters or nodes. Instead, developers can create a database with a simple click or API call. Upon creation, an endpoint for database access (i.e., IP:Port represented as a URL) is received, and thereafter, the database adjusts itself (throughput and memory/storage-wise) to accommodate the application’s load – without requiring any administrative input.
SDBaaS providers are responsible for ensuring their infrastructure is appropriate. That’s unlike instance-based DBaaS, where developers must select an instance type from a list of dozens or even hundreds of options to create a cluster to host their dataset.
SDBaaS pricing is generally determined by two factors: the size of the dataset and the cost of database operations. Some vendors charge separately for reads and writes.
A variety of billing options are available:
- Provisioning-based: You are charged based on the amount of data and rate of operations you set. SDBaaS vendors that support this method typically provide an API for changing this setting so developers can embed it into their applications.
- Usage-based: Charges are based on the actual memory used and operations executed, usually measured hourly.
- Bounded usage-based: This option combines previous options with bounded usage-based pricing to prevent out-of-control bills. The limit can usually be changed with a simple API call.
When does SDBaaS make sense?
Many factors influence the decision to use SDBaaS, but the following are the most crucial.
Choosing the right instance type for your workload is difficult. In instance-based DBaaS, developers must choose among dozens or hundreds of cloud instances without understanding how the service works. Some instance-based DBaaS vendors fail to disclose on their pricing pages that the size of the dataset that can be stored in their service instances is much less than what they actually provide. The result is that developers choose the wrong instances, scale up (or scale out) sooner than they’d planned, and pay more than they should. Next time, that developer may choose larger instances to host the database, just to be safe, and it’s well-known that overprovision costs significantly more.
Most developers don’t know how many cores a database workload actually requires, and it could be argued that they should not need to. That calculation is a complex one, which most developers have no chance of solving even if they have previous experience with a database. Whether the service is based on an open-source project or whether you used to run commercial software on-premises, in many cases, you will find that the DBaaS vendor created a fork of the software. Again, that leads to spending more money and scaling up (or scaling out) sooner than planned.
A developer who uses instance-based services is responsible for scaling and deciding when to use new instances. In some cases, they are forced to change how their application works with the database, for example, when moving from a non-cluster mode to a cluster mode database. To choose a managed cloud service but be forced to operate it without the tools or knowledge seems absurd.
SDBaaS ensures flexible scaling (to cope with the ups and downs), eliminates the need to manage anything, and prevents you from paying your DBaaS vendor a fortune.
SDBaaS for real-time use cases
Architecting real-time applications goes beyond infrastructure costs. You must also ensure that your chosen database can handle the load with a latency that guarantees end users have responsiveness.
As a rule of thumb, every millisecond spent in the database is a hundred times this number for the end users.
A typical real-time application must respond within 100 milliseconds, preferably less, for every user request, which means the database should handle any query (read or write) in less than a millisecond. How are your applications stacking up against that metric?
Real-time use cases can benefit greatly from serverless Redis
Redis Enterprise Cloud was built on a serverless architecture from the start, allowing developers to dynamically configure their data (dataset size plus replica if needed) and throughput (operations per second) limits and to be billed just for what they set. Using a comprehensive algorithm, we select the appropriate instance type for the cluster and we distribute Redis shards so that any workload can be processed in an average of less than a millisecond.
Redis relies on DRAM, which is significantly more expensive than SSD. However, the majority of the cost for an SDBaaS is determined by the number of operations executed rather than by the amount of data stored. That point is particularly relevant in real-time scenarios in which one database can manage thousands or even millions of requests per second. Because Redis is engineered for high-speed performance, a single core can handle more operations than dozens or hundreds of cores in other databases. This makes each operation carried out in Redis highly cost-effective.
This isn’t an academic exercise. We benchmarked read and update performance by running common workloads with a fixed dataset size of 50GB (plus replications) and multiple throughput levels (measured by operations per second) across two popular SDBaaS solutions: Amazon DynamoDB and Redis Enterprise Cloud. We found the following results:
The read performance:
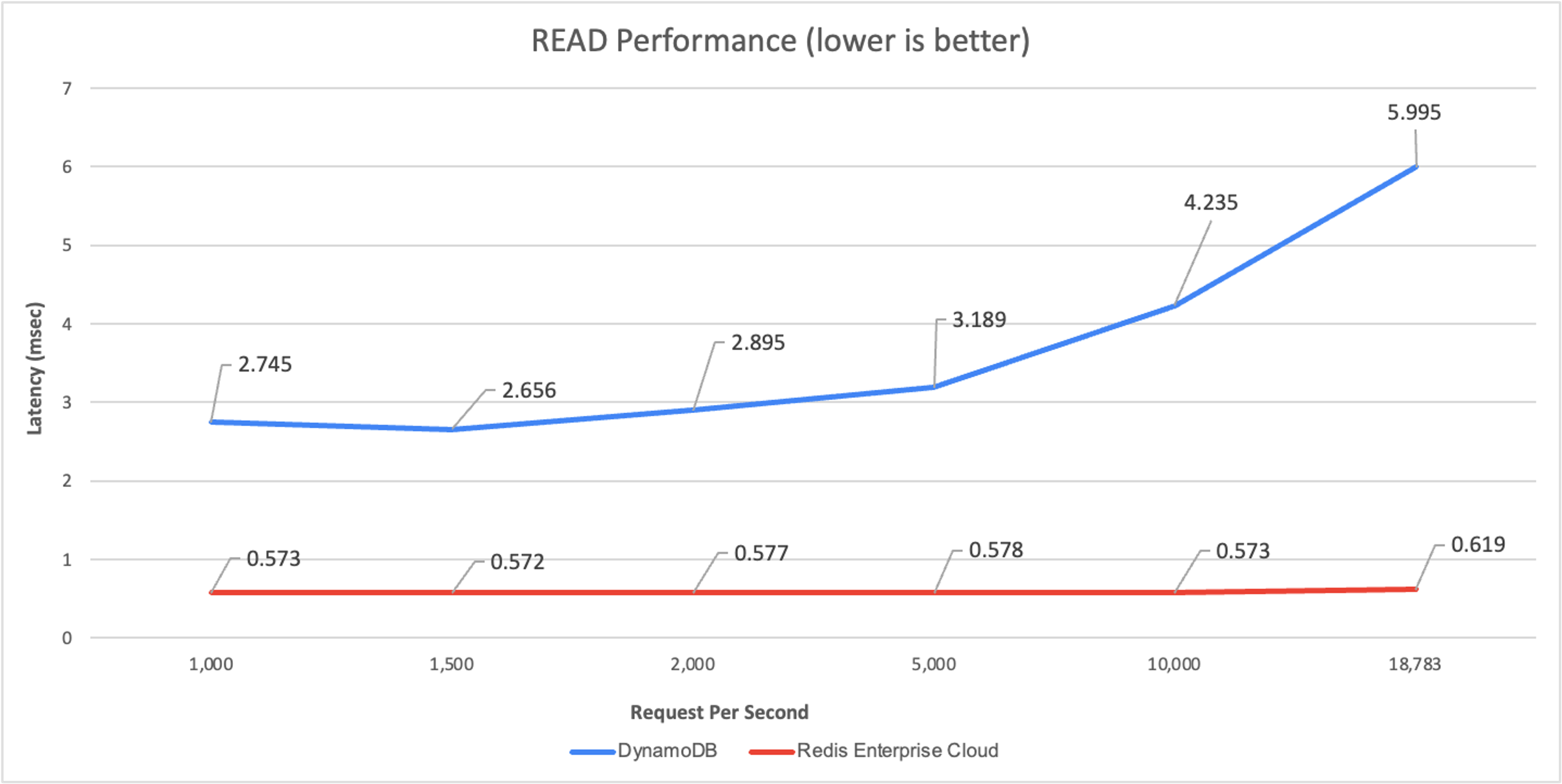
Serverless DBaaS Read Performance
The update performance:
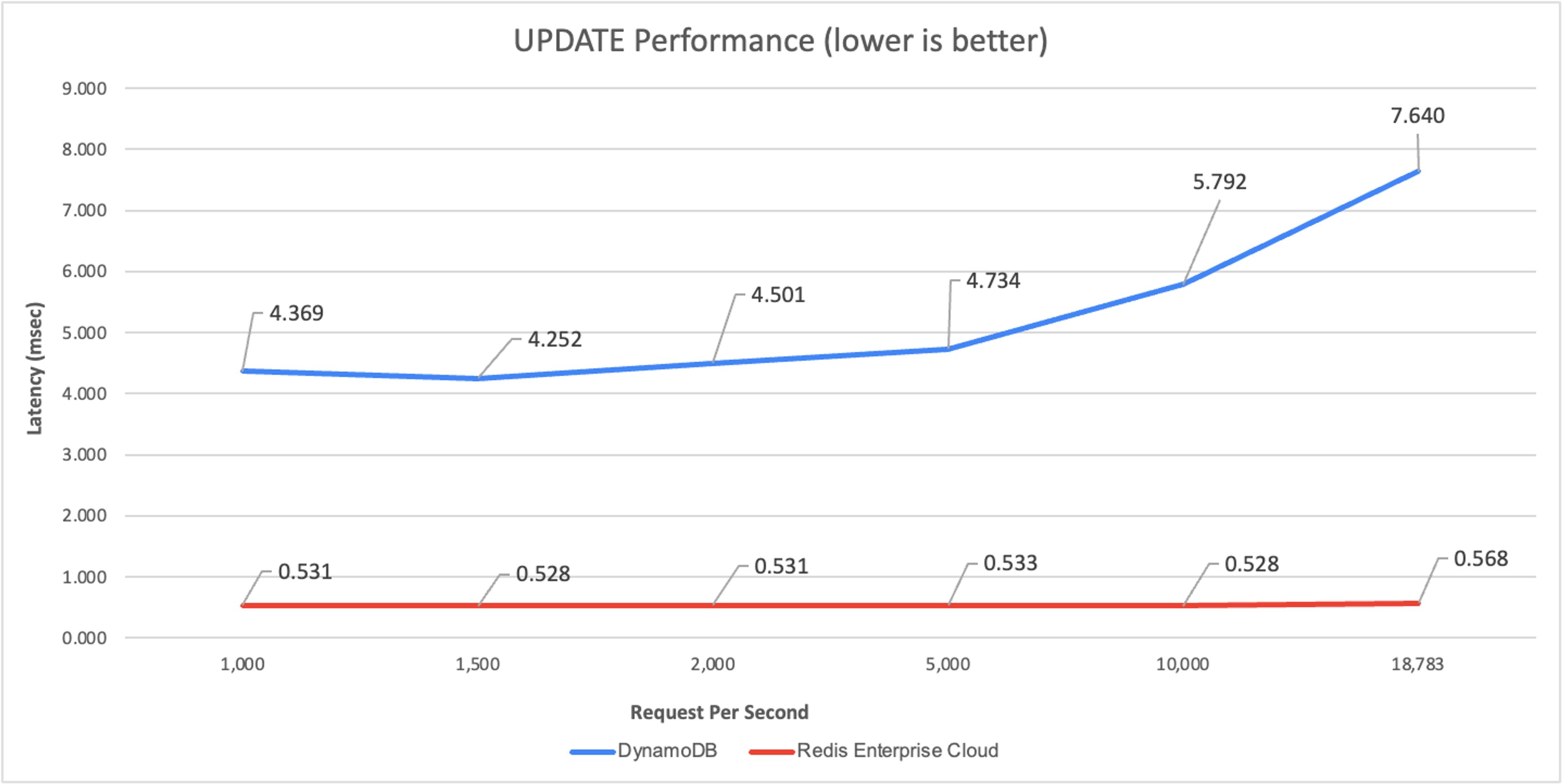
Serverless DBaaS Update Performance
No matter which workload we tested, Redis Enterprise Cloud maintained an end-to-end latency of 0.5-0.6 msec.
In contrast, DynamoDB performed no faster than 2.7ms (for read) and 4.4ms (for update), even with only a few requests per second (not shown). At 18,000 operations per second, DynamoDB latency increased to 6msec for read operations and close to 8msec for update operations, 12- and 16-times slower than Redis Enterprise Cloud, respectively.
Finally, for this workload, we found that DynamoDB cannot scale beyond 18,783 operations per second using the default throughput quotas per table.
We did the math
Our next step was to create a cost/performance graph comparing the cost of each SDBaaS solution at different requests per second levels, as well as the performance advantage Redis Enterprise Cloud provides over DynamoDB (averaged results for read and update).
The results speak for themselves:
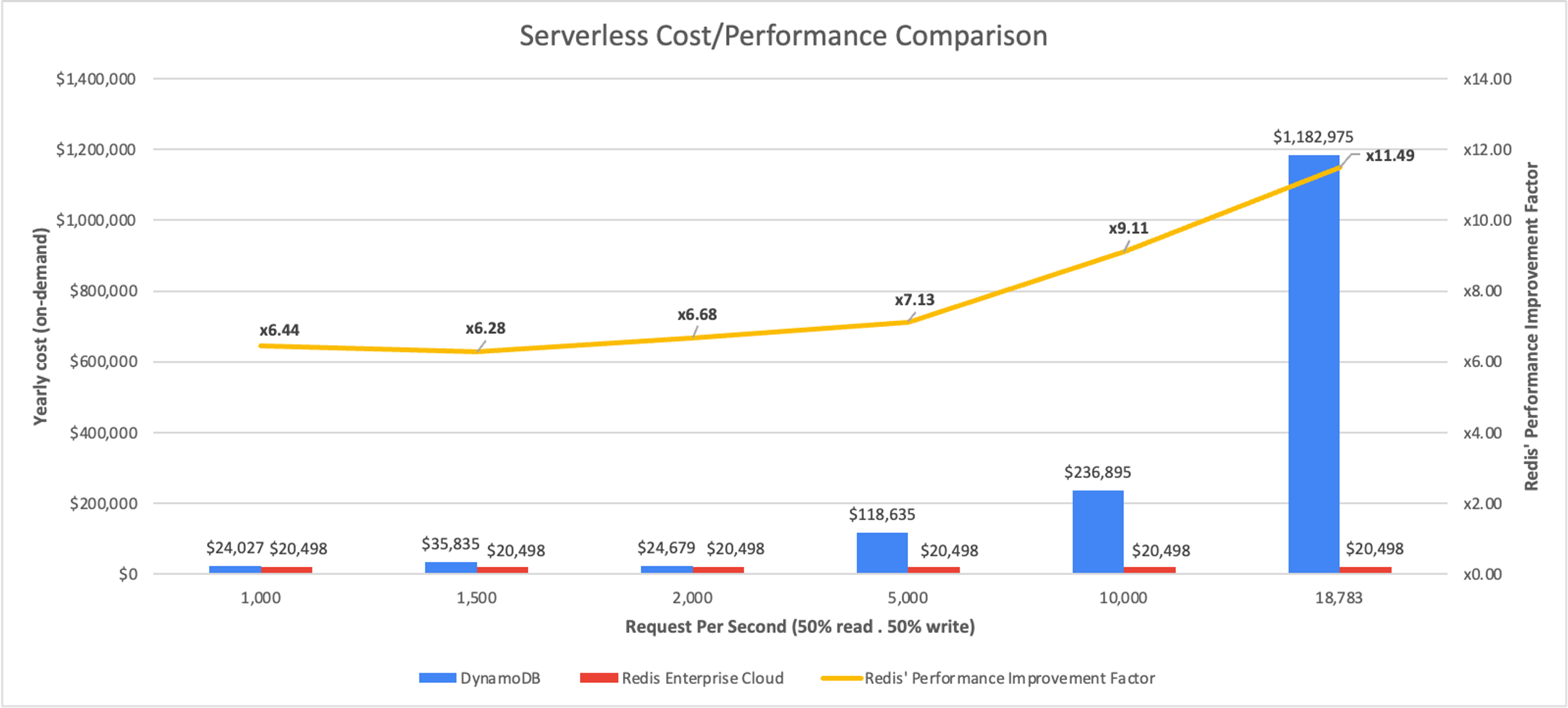
Serverless DBaaS Cost/Performance Comparison
When it comes to 1,000 requests per second, Redis Enterprise Cloud is already 15% cheaper than DynamoDB (as well as 6.44 faster). At 18,000 requests per second, Redis Enterprise Cloud is less than 2% of DynamoDB’s costs and over an order of magnitude faster.
The bottom line
Obviously, we at Redis are convinced that SDBaaS Redis is ideal for real-time applications. It is easy to manage, flexible, scalable, and extremely cost-effective. The cost of operation is much more meaningful than the cost of storing the data, and each operation in Redis is extremely cheap. Moreover, it ensures real-time experience for your end users, as any database operation can be executed in less than 1 msec.
Do your own testing, if you like, and see if our performance data matches yours.
Get a serverless Redis for free if you don’t already have one.
Appendix: benchmark details
- Size of documents: 1.5KiB – 2KiB
- Size of documents: 1.5KiB – 2KiB
- Number of documents: 50M
- Dataset size: 100GB, with replication 200GB
- Redis consistency:
- Redis: enabled by default
- DynamoDB: dynamodb.consistentReads = true
- Data-persistence:
- Redis: Append-only file every 1 sec
- DynamoDB – enabled by default
- Benchmark environment: AWS/us-east-1
- Testing tool: YCSB
- Testing tool VM:
- c5n.4xlarge, 16VCPUs Intel(R) Xeon(R) Platinum 8124M CPU at 3.00GHz
- All test runs showed that the benchmark client was not fully saturated at the network, and compute/load levels
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.