Blog
The Challenges in Building an AI Inference Engine for Real-Time Applications

The artificial intelligence (AI) boom took off when people realized that they can utilize GPU technology to train deep-learning models much faster than waiting days for a general-purpose CPU to complete one cycle of model training. (Check out this informative Quora thread for more details.)
Since 2016, when GPU manufacturers like NVIDIA, Intel, and others created their first AI-optimized GPUs, most AI development has been related to how to train models to be as accurate and predictive as possible. In late 2017 many enterprises and startups began to think about how to take machine learning/deep learning (ML/DL) to production. Successful open source projects like MLFlow and Kubeflow aim to move AI from its research and scientific phase to solving real-world problems, by managing the entire AI lifecycle. They introduce similar approaches for managing the machine learning pipeline lifecycle, as nicely presented in the graphic below taken from Semi Koen’s Not yet another article on Machine Learning! blog):
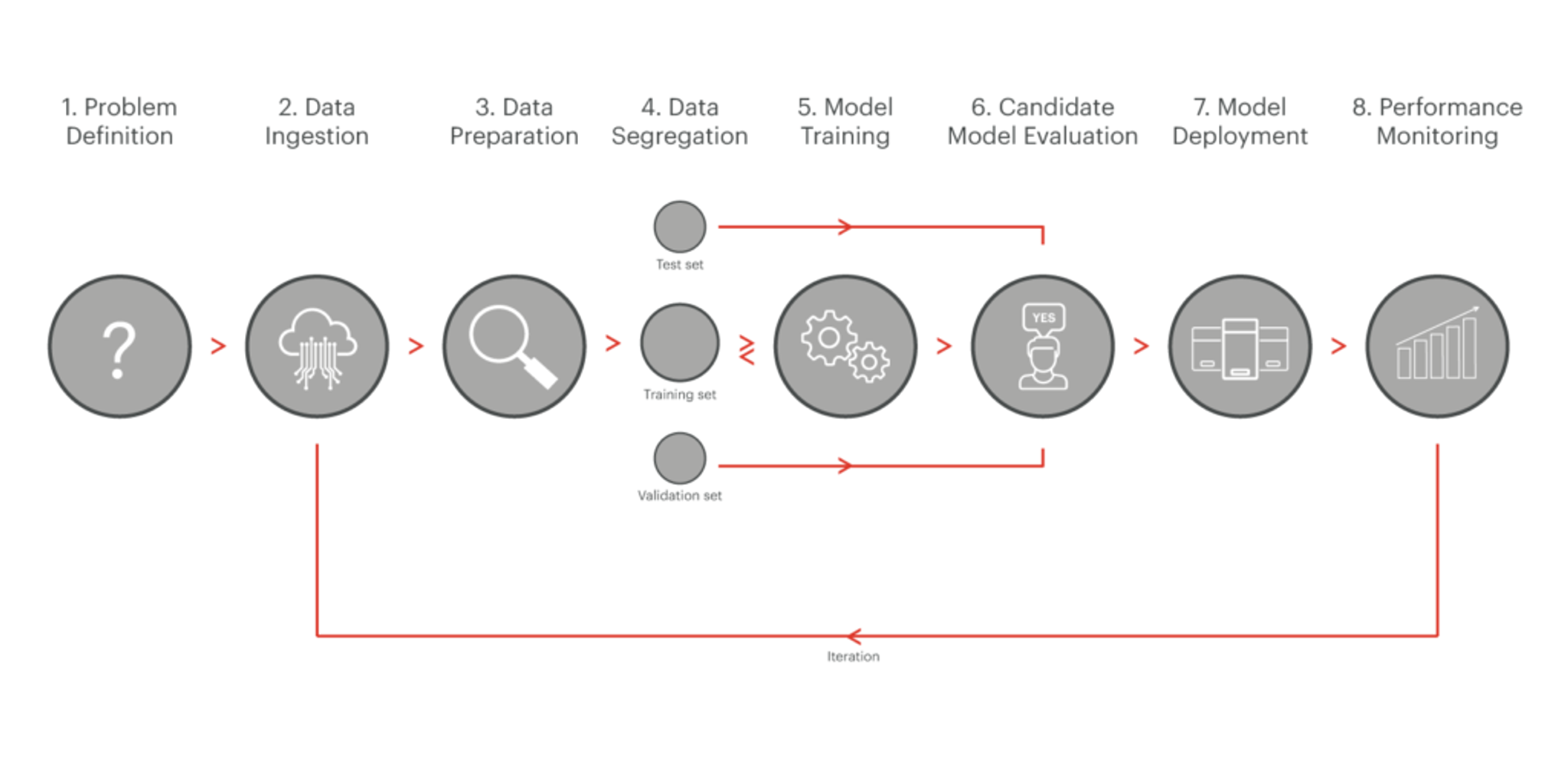
At a very high level, one of the most critical steps in any ML pipeline is called AI serving, a task usually performed by an AI inference engine. The AI inference engine is responsible for the model deployment and performance monitoring steps in the figure above, and represents a whole new world that will eventually determine whether applications can use AI technologies to improve operational efficiencies and solve real business problems.
The challenges in building an AI inference engine for real-time applications
We have been working with Redis Enterprise customers to better understand their challenges taking AI to production and, more specifically, their architecture requirements from an AI inference engine. After multiple interactions with many customers, we came up with this list:
- Fast end-to-end inferencing/serving: Our customers already heavily rely on Redis as the engine behind their instant-experience applications. They require that adding AI functionality to their stack have little to no effect on their application performance.
- No downtime: As every transaction potentially includes some AI processing, customers need to maintain the same level of SLA, preferably five-nines and above for mission-critical applications, using proven mechanisms such as replication, data-persistence, multi availability zone/rack, active-active geo-distribution, periodic backups, and auto-cluster recovery.
- Scalability: Driven by their users’ behavior, many of our customers’ applications were built to serve peak usages, and need the flexibility to scale-out or scale-in their AI inference engine based on their expected and actual load.
- Support for multiple platforms: The AI inference engine must be able to serve deep-learning models trained by state-of-the-art platforms like TensorFlow or PyTorch. Furthermore, machine-learning models like random-forest and linear-regression still provide good predictability for many use cases and should be included.
- Easy to deploy new models: Customers want the option to frequently update their models according to market trends or in-order to exploit new opportunities. Updating a model should be as transparent as possible and shouldn’t affect application performance.
- Performance monitoring and retraining: Everyone wants to know how well the model they trained is executing, and be able to tune it according to how well it performs in the real world. It is therefore required that the AI inference engine support A/B testing to compare the model against a default model. Customers also look for the system to provide tools to rank the AI execution of their applications.
- Deploy everywhere: Customers want to build and train in the cloud and serve/inference everywhere: in a particular vendor’s cloud, across multiple clouds, on-premises, in hybrid clouds, or at the edge. The AI inference engine should therefore be platform agnostic, based on open source technology with a well-known deployment model that can run on CPUs, state-of-the-art GPUs, high-end compute engines, or even on tiny Raspberry Pi devices.
3 Ways to achieve fast end-to-end AI inferencing/serving
Our first mission at Redis is to help our customers and users solve complex problems at the speed of a millisecond. So let’s take a look at the first challenge in our list—fast end-to-end inferencing/serving—and see how to achieve that goal when adding AI to the production deployment stack.
1. The new AI inference chipsets can help, but address only part of the problem
There has been plenty of coverage (for example here and here) on how chipset vendors are making significant efforts to provide highly optimized inferencing chipsets by 2021. These chipsets aim to accelerate inference processing such as video, audio, and augmented reality/virtual reality by increasing the processes’ parallelism and memory bandwidth. But accelerating only the AI processing portion of the transaction chain may provide only limited benefits, as in many cases the AI platform should be enriched with reference data scattered across multiple data sources. The process of retrieving and enriching AI with reference data can be orders of magnitude slower than the AI processing itself, as shown in this transaction scoring example:
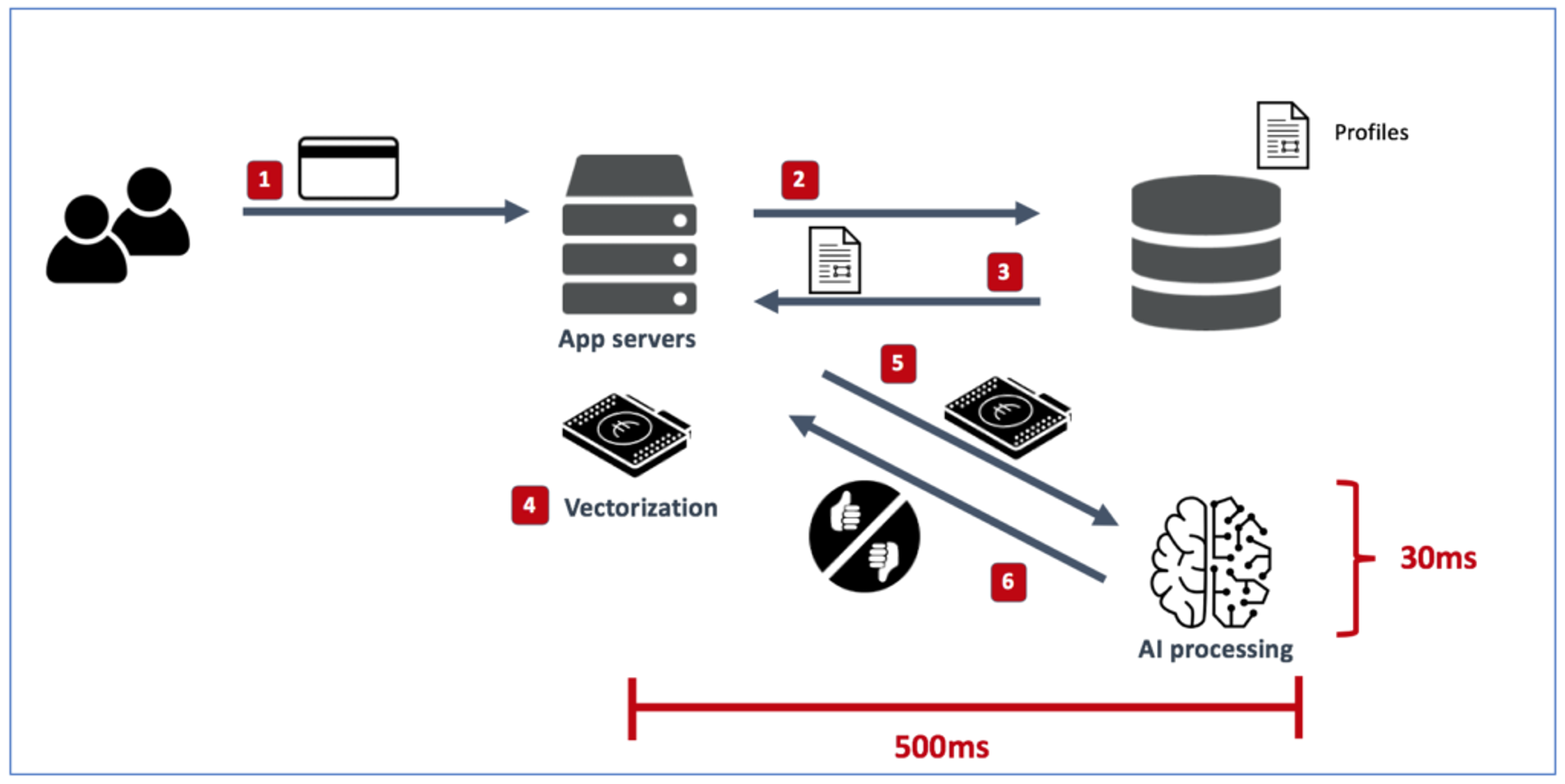
Let’s walk through what’s happening here:
- Step 1: The transaction scoring application received a credit-card score request from one of the merchants it’s working with.
- Steps 2-3: The application server performs multiple database queries, to one or more database services, to retrieve the reference data of that transaction. The reference data in this case can include user profile, merchant profile, location profile, and so on.
- Step 4: The transaction scoring application vectorizes the transaction data with the reference data and prepares it for the AI processing engine.
- Step 5: The vectorized data is sent to the AI engine.
- Step 6: Passed/failed responses are sent back to the application server.
- Step 7: Passed/failed responses are sent back to the merchant.
As shown above, even if we improve the AI processing by an order of magnitude (from 30ms to 3ms) the end-to-end transaction time inside the data center remains about 500ms, because the AI processing represents less than 10% of the overall transaction time.
So for use cases like transaction scoring, recommendation engines, ad bidding, online pricing, fraud detection, and many others where the AI inferencing time is mainly associated with bringing and preparing the reference data to the AI processing engine, the new inferencing chipset can only marginally improve the end-to-end transaction time.
2. Run your AI inference platform where your data lives
As most of the reference data of a latency sensitive application is stored in a database, it makes sense to run the AI inference engine where the data lives, in the database. That being said, there are a few challenges with this approach:
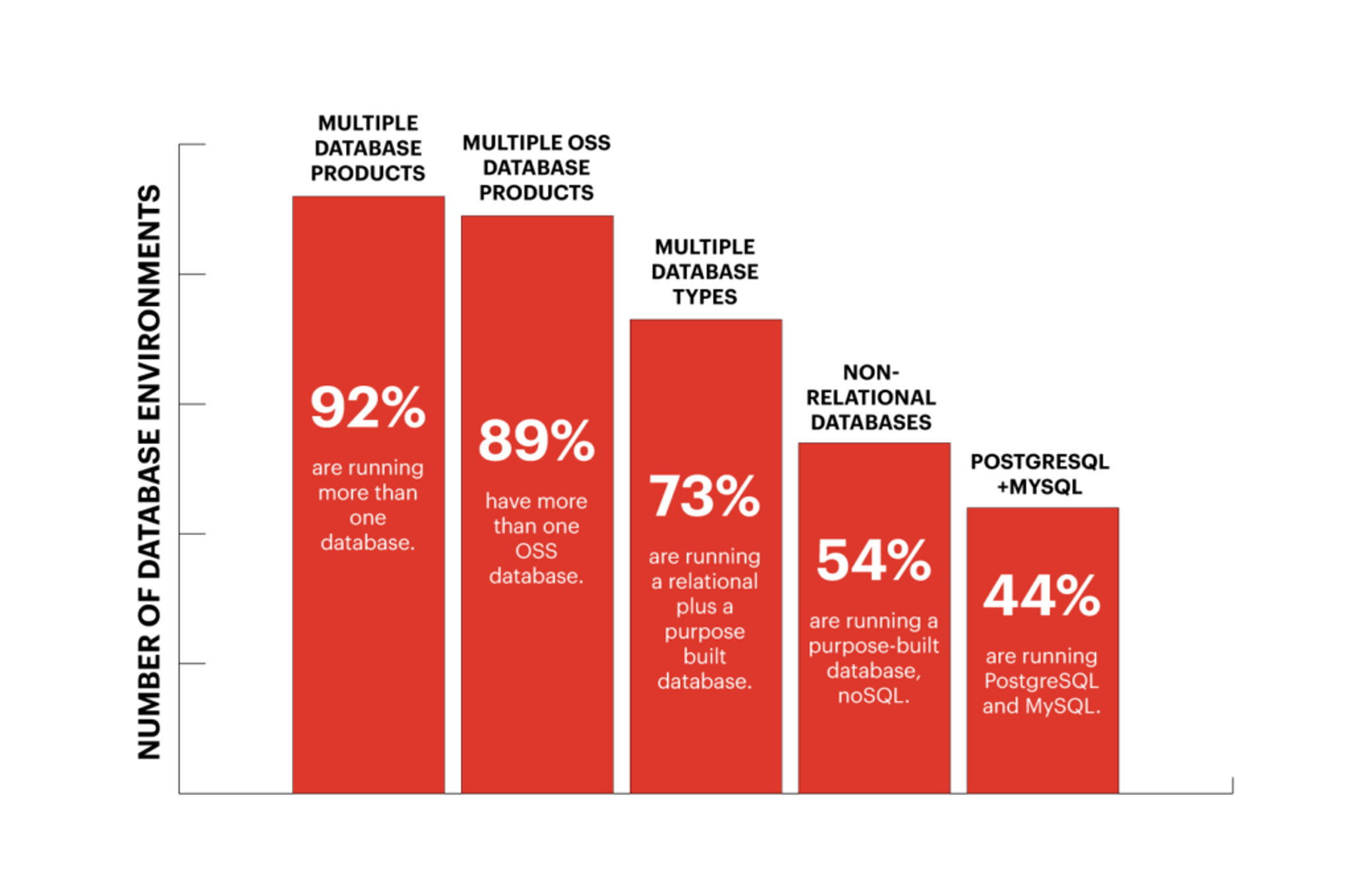
1. In cases where the application data is scattered across multiple databases, which database should the AI inference engine run on? Even if we ignore the deployment complexity and decide to run a copy of the AI inference engine on every database, how do we deal with a situation where a single application transaction requires bringing the reference data from multiple databases? A recent survey from Percona nicely demonstrated how multiple databases represent the deployment architecture of most applications:
2. To achieve the low-latency AI inferencing requirements, reference data should be stored in-memory. Many people believe that by adding a caching layer on the top of existing databases this problem can easily be solved. But caching has its own limitations. For instance, what happens in cache misses events where the application doesn’t find the data in the cache, forced to query the data from a disk-based database and then update the cache with the latest data? In this scenario the probability of infringing your end-to-end response time SLA is very high. And how do you make sure your database updates are in-sync with your cache and immune to consistency problems? Finally, how do you ensure that your caching system has the same level of resiliency as your databases? Otherwise your application uptime and your SLA will be driven by the weakest link in the chain, your caching system.
To overcome the need for maintaining a separate caching layer, we believe that the right architecture choice to deploy the AI inference engine is an in-memory database. This avoids problems during cache misses events and overcomes data-synchronization issues. The in-memory database should be able to support multiple data models, allowing the AI inference engine to be as close as possible to each type of reference data and avoid having to build high-resiliency across multiple databases and a caching system.
3. Use a purpose-built, in-database, serverless platform
It is easy to imagine how latency-sensitive applications can benefit from running the AI inference engine in an in-memory database with multiple data models for solving these performance challenges. But one thing is still missing in this puzzle: Even if everything sits together in the same cluster with fast access to shared memory, who will be responsible for collecting the reference data from multiple data sources, processing it, and serving it to the AI inference engine, while minimizing end-to-end latency?
Serverless platforms, like AWS Lambda, are often used for manipulating data from multiple data sources. The problem with a generic serverless platform for AI inferencing is that users have no control where the code is actually executing. This leads to a key design flaw: Your AI inference engine is deployed as close as possible to where your data lives, in your database, but the serverless platform that prepares the data for AI inferencing runs outside your database. This breaks the concept of serving AI closer to your data, and leads to the same latency problems discussed earlier when the AI inference engine was deployed outside your database.
There’s only one way to solve this problem: a purpose-built serverless platorm that is part of your database architecture and runs on the same shared cluster memory where your data and your AI inference engine live.
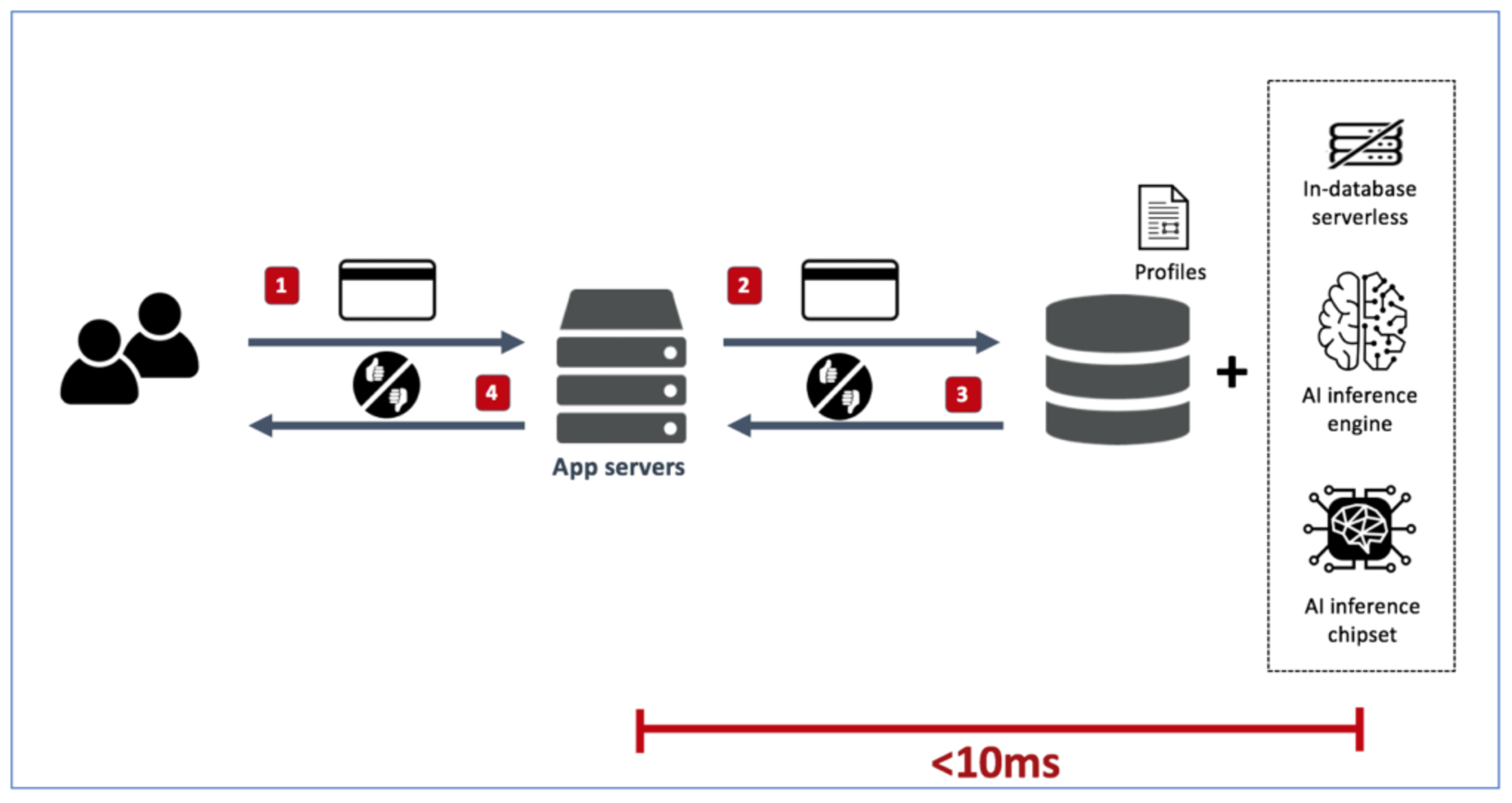
Going back to the transactions scoring example, this is how fast (and simple) the solution can look if we apply these principles:
AI in production
Taking AI to production creates new challenges that did not exist during the training phase. Solving these problems requires many architectural decisions, especially when a latency-sensitive application needs to integrate AI capabilities in every transaction flow. In conversations with Redis customers who are already running AI in production, we found that in many cases a significant part of the transaction time is spent on bringing and preparing the reference data to the AI inference engine rather than on the AI processing itself.
We therefore propose a new AI inference engine architecture that aims to solve this problem by running the system in an in-memory database with built-in support for multiple data models, and uses a purpose-built, low-latency, in-database serverless platform to query, prepare, and then bring the data to AI inference engine. Once these ingredients are in place, a latency-sensitive application can benefit from running the AI on a dedicated inference chipset, as the AI processing takes up a more significant portion of the entire transaction time.
Finally, adding AI to your production deployment stack should be done with extreme care. We believe that businesses that rely on latency-sensitive applications should follow these suggestions to prevent the user experience being degraded by slowness in the AI inference engine. In the early days of AI, the slow performance of general-purpose CPUs created headwinds for developers and researchers during the training phase. As we look toward deploying more AI applications into production, architecting a robust AI inference engine will ultimately separate the winners from the losers in the pending AI boom.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.