
For those of you familiar with Redis, it should be relatively straightforward to create a configuration that guarantees ACID-ish (Atomicity, Consistency, Isolation, Durability) operations: merely create a single Redis instance with a ‘master’ role and have it configured with AOF every write (‘appendfsync always’) to a persistent storage device. This configuration provides ACID characteristics in the following ways:
- Atomicity – indivisible and irreducible characteristics are achieved using Redis transaction commands (i.e. WATCH/MULTI/EXEC) or Lua scripting. “All or nothing” property is almost always achieved, excluding cases like OOM (Out Of Memory) or a buggy Lua script
- Consistency – Redis validates that any ‘write’ operation affects the target data-structure in allowed ways, and any programming errors cannot result in the violation of any defined rules
- Isolation – at the command level, isolation is achieved due to the fact that Redis is single threaded; for multiple operations, isolation can be achieved using transactions (i.e. WATCH/MULTI/EXEC) or inside a Lua script.
- Durability – with AOF (Append Only File) every write, Redis replies to the client after the ‘write’ operation has been successfully written to disk, guaranteeing durability. In addition, you should connect your persistent storage to your network so that data can be easily recovered by attaching a new node to the same persistent storage used by the failed node.
That said, most Redis users prefer not to run Redis in this configuration as it can dramatically affect the performance. For example, if the persistent storage is currently busy, Redis would wait with the request’s execution until the storage becomes available again.
With that in mind, we wanted to determine how fast can Redis Enterprise (Redise) cluster can process ACID transactions. There are several built-in enhancements that we have made to the Redise architecture that enable a better performance in an ACID configuration, including:
- With Redis Enterprise, it is easy to create a master-only cluster and have all shards run on the same node. Since Redis is single threaded, running multiple shards on the same node will help us in terms of higher throughput because all the cores on the node get utilized. Additionally, this will also help us determine how much throughput we can get from a single node and then scale the cluster accordingly if more throughput is needed.
- Since the size of the AOF grows with every ‘write’ operation, an AOF rewrite process is needed to control the size of the file and reduce the recovery time from disk. By default (and also configurable), the OSS Redis triggers a rewrite operation when the size of the AOF has doubled the size of the previous rewrite operation. So in a ‘write’ intensive scenario, the rewrite operation can block the main loop of Redis (as well as other Redis instances that are running on the same node) from executing ongoing requests to disk. Redis Enterprise uses a greedy AOF rewrite algorithm that attempts to postpone AOF rewrite operations as much as possible without infringing the SLA for recovery time (a configurable parameter) and without reaching the disk space limit. The advantage of this approach is that throughput with Redis Enterprise is higher especially in ACID configurations, due to optimal use of the rewrite process.
- The Redis Enterprise storage layer allows multiple Redis instances to write to the same persistent storage in a non-blocking way, i.e. a busy shard that is constantly writing to disk (e.g. when AOF rewrite is performing) will not block other shards from executing durable operations.
The ACID benchmark on AWS
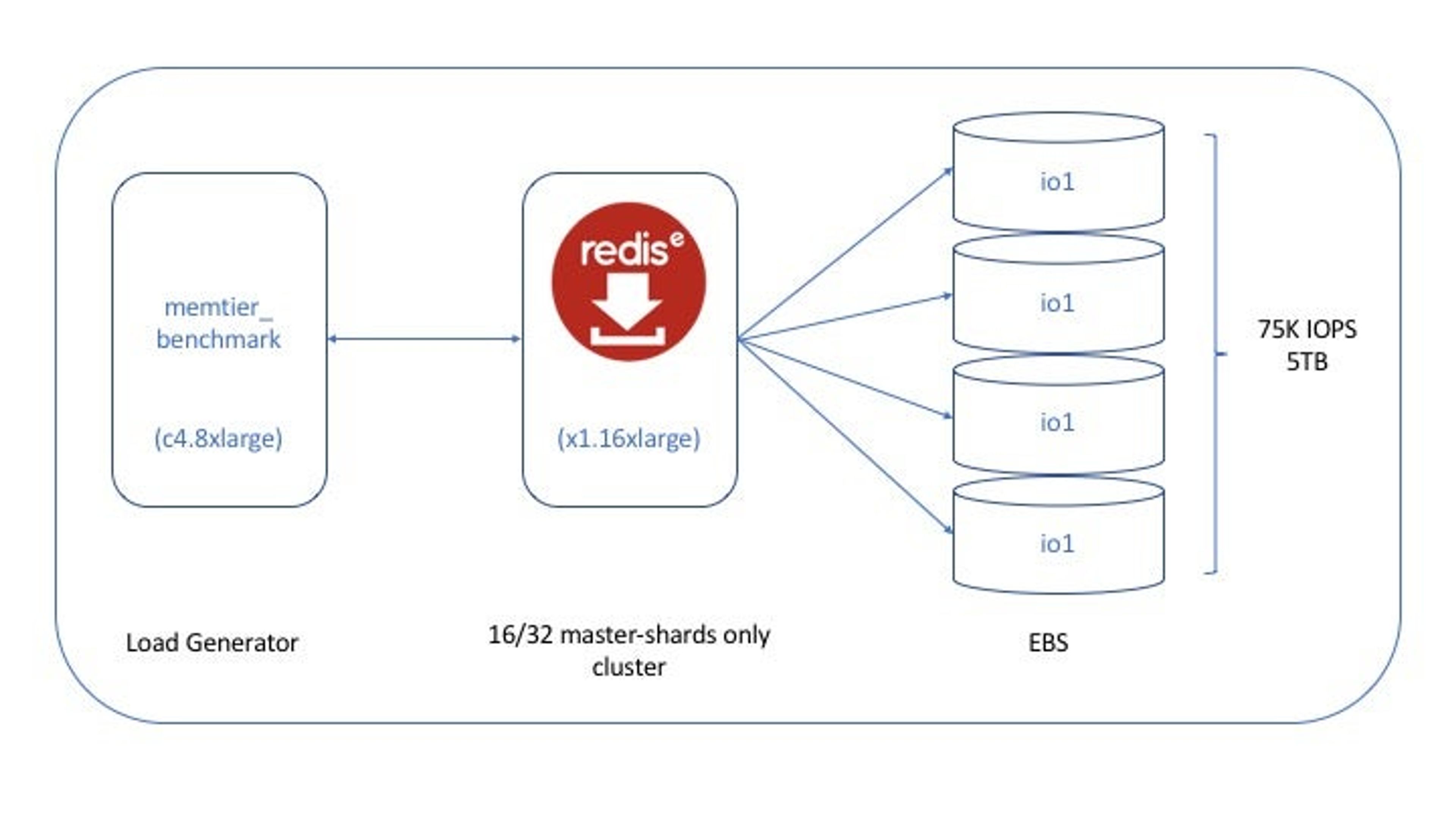
We deployed the following benchmark configuration inside an AWS VPC:
- 1x c4.8xlarge instance for running memtier_benchmark version 1.2.6 as the load generation tool
- 1x x1.16xlarge instance for running the master-shards only Redise Pack cluster version 4.4.2-30
- 4x io1 EBS volumes with a total of 5TB and 75K IOPS/sec
Running the benchmark
Despite having tested multiple types of loads, including different read/write ratios; different object sizes (from 100B to 6KB); multiple number of connections; with and without pipelining; we couldn’t get less than one millisecond latency for durable ‘write’ operations, where latency was measured from the time the first byte of the request arrived at the cluster until the first byte of the ‘write’ response was sent back to the client. Finally, we tested a single request over a single connection, but still couldn’t get less than 2-3 millisecond latency. We did a deeper analysis and found that there was no way to achieve less than two milliseconds of latency between any instance on the AWS cloud and EBS storage under an ACID configuration.
As most of our customers want <1 millisecond latency, we decided to look for alternatives.
ACID benchmarking on Dell-EMC VMAX
VMAX background
In a nutshell VMAX is a family of storage arrays built on the strategy of simple, intelligent, modular storage. It incorporates a Dynamic Virtual Matrix interface that connects and shares resources across all VMAX engines, allowing the storage array to seamlessly grow from an entry-level configuration into the world’s largest storage array.
Performance-wise, VMAX can scale from one up to eight engines (V-Bricks). Each engine consists of dual directors, each with 2-socket Intel CPUs, front-end and back-end connectivity, hardware compression module, Infiniband internal fabric, and a large mirrored and persistent cache. All writes are acknowledged to the host as soon as they registered with VMAX cache and only later, perhaps after multiple updates, are written to flash. Reads also benefit from the VMAX large cache. When a read is requested for data that is not already in cache, FlashBoost technology delivers the I/O directly from the back-end (flash) to the front-end (host) and is later staged in the cache for possible future access.
Benchmark configuration
We set up the following benchmark environment:
Below are some more details:
Benchmark parameters
- Item size – 100B and 6000B, covering most Redis use cases
- We tested different read/write ratios
- Standard – 1:1
- ‘write’ intensive – 1:9
- ‘Read’ intensive – 9:1
- In each configuration, we measured how many ACID ops/sec could be achieved while keeping sub-millisecond server latency. Server latency includes the entire Redis process and commits to disk, but excludes the client-server network overhead.
Benchmark Results
As expected, the ‘read’ intensive tests provided the best results; that said, we were very surprised to see over 660K ops/sec on the standard 1:1 read/write use case with 100B item_size, and only slightly lower throughout (i.e. 640K op/sec) on the write-intensive scenario. We were also impressed with the 6000B results, even under a write-intensive scenario such as 80K ops/sec with sub-millisecond latency on a single cluster node.
We were surprised (and happy) to discover that with high-end persistent storage devices like Dell-EMC VMAX, a single Redise cluster node can support over 650K ACID ops/sec while keeping sub-millisecond database latency.
On the other hand, we were disappointed to see that we cannot run a single durable operation under sub-millisecond latency on the state-of-the-art cloud storage infrastructure (i.e. AWS io1 EBS). With the multitude of advanced technologies and public clouds services available, there is still a ways to go.
Appendix
memtier_benchmark parameters
Each test was run with the following memtier_benchmark parameters
- Number of clients – 70
- Number of threads – 1
- Pipeline size – 20
- Test run time – 900 seconds
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.