Tutorial
Kubernetes Operator: What It Is and Why You Should Really Care About It
February 26, 202618 minute read

TL;DR:A Kubernetes Operator for Redis is a custom controller that automates the deployment, scaling, backup, and lifecycle management of Redis clusters on Kubernetes. Instead of manually managing stateful Redis workloads, the Redis Enterprise Operator uses Custom Resource Definitions (CRDs) so you can declare your desired cluster state in YAML and let the Operator handle the rest.

#What you'll learn
- Why stateful applications like Redis are hard to manage on Kubernetes
- What the Kubernetes Operator pattern is and how it extends the Kubernetes API
- How the Redis Enterprise Operator deploys and manages Redis clusters and databases
- How to scale a Redis cluster by changing a single field in a YAML spec
- Where to find popular Operators on OperatorHub.io
Kubernetes is popular due to its capability to deploy new apps at a faster pace. Thanks to "Infrastructure as data" (specifically, YAML), today you can express all your Kubernetes resources such as Pods, Deployments, Services, Volumes, etc., in a YAML file. These default objects make it much easier for DevOps and SRE engineers to fully express their workloads without the need to learn how to write code in a programming language like Python, Java, or Ruby.
Kubernetes is designed for automation. Out of the box, you get lots of built-in automation from the core of Kubernetes. It can fast-track your development process by making easy, automated deployments, updates (rolling update), and by managing your apps and services with almost zero downtime. However, Kubernetes can't automate the process natively for stateful applications. For example, say you have a stateful workload, such as a database application, running on several nodes. If a majority of nodes go down, you'll need to reload the database from a specific snapshot following specific steps. Using existing default objects, types, and controllers in Kubernetes, this would be impossible to achieve.
Think of scaling nodes up, or upgrading to a new version, or disaster recovery for your stateful application — these kinds of operations often need very specific steps, and typically require manual intervention. Kubernetes cannot know all about every stateful, complex, clustered application. Kubernetes, on its own, does not know the configuration values for, say, a Redis database cluster, with its arranged memberships and stateful, persistent storage. Additionally, scaling stateful applications in Kubernetes is not an easy task and requires manual intervention.
#Stateful vs Stateless Apps
Let's try to understand the difference between stateful versus stateless applications with a simple example. Consider a Kubernetes cluster running a simple web application (without any operator). The YAML file below allows you to create two replicas of NGINX (a stateless application).
In the example above, a Deployment object named
nginx-deployment is created under a namespace "web," indicated by the .metadata.name field. It creates two replicated Pods, indicated by the .spec.replicas field. The .spec.selector field defines how the Deployment finds which Pods to manage. In this case, you select a label that is defined in the Pod template (app: nginx). The template field contains the following subfields: the Pods are labeled app: nginx using the .metadata.labels field and the Pod template's specification indicates that the Pods run one container, nginx, which runs the nginx Docker Hub image at version 1.14.2. Finally, it creates one container and names it nginx.Run the command below to create the Deployment resource:
Let us verify if the Deployment was created successfully by running the following command:
The example above shows the name of the Deployment in the namespace. It also displays how many replicas of the application are available to your users. You can also see that the number of desired replicas that have been updated to achieve the desired state is 2.
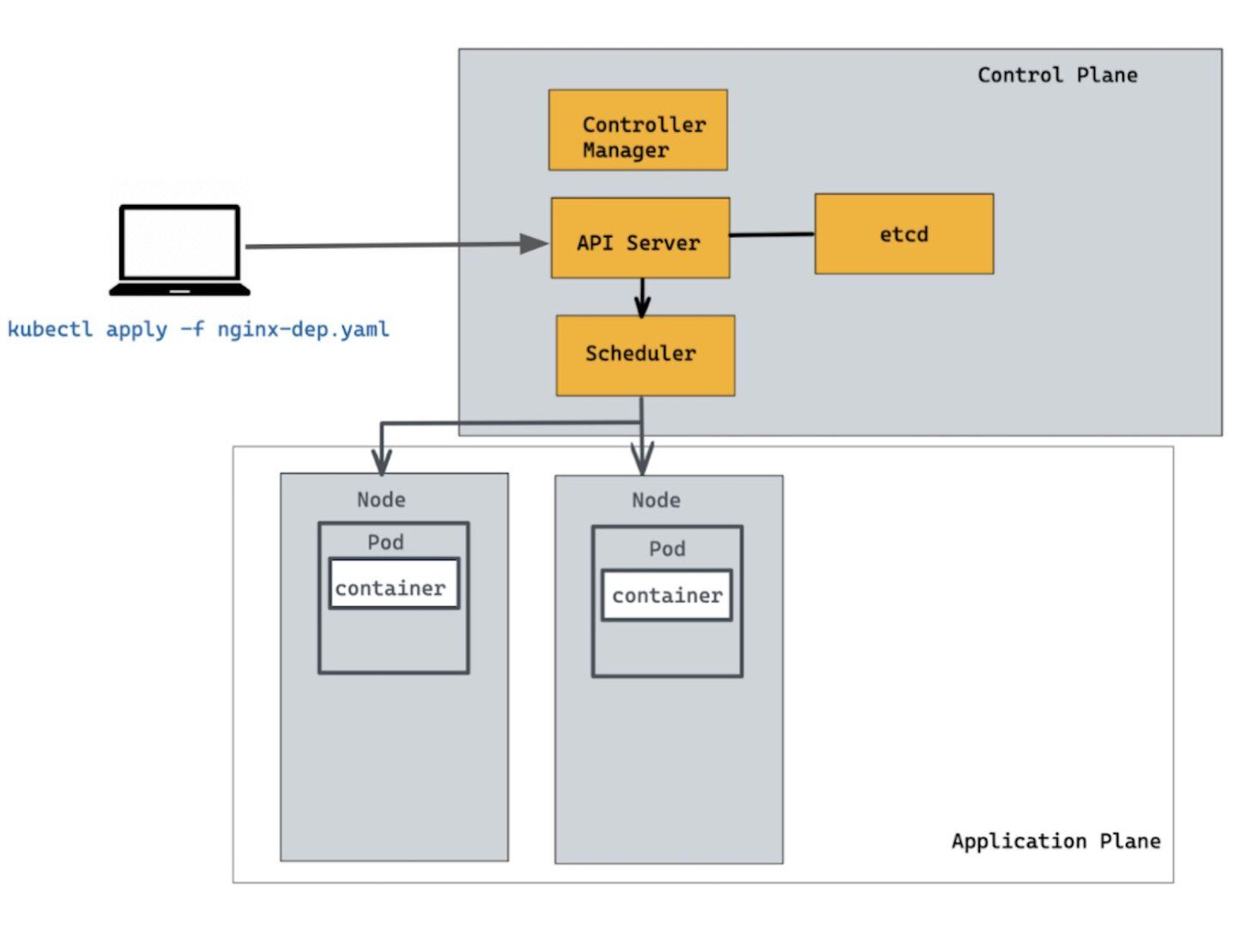
You can run the
kubectl describe command to get detailed information of deployment resources. To show details of a specific resource or group of resources:A Deployment is responsible for keeping a set of Pods running, but it's equally important to expose an interface to these Pods so that the other external processes can access them. That's where the Service resource comes in. The Service resource lets you expose an application running in Pods to be reachable from outside your cluster. Let us create a Service resource definition as shown below:
The above YAML specification creates a new Service object named "nginx-service," which targets TCP port 80 on any Pod with the
app=nginx label.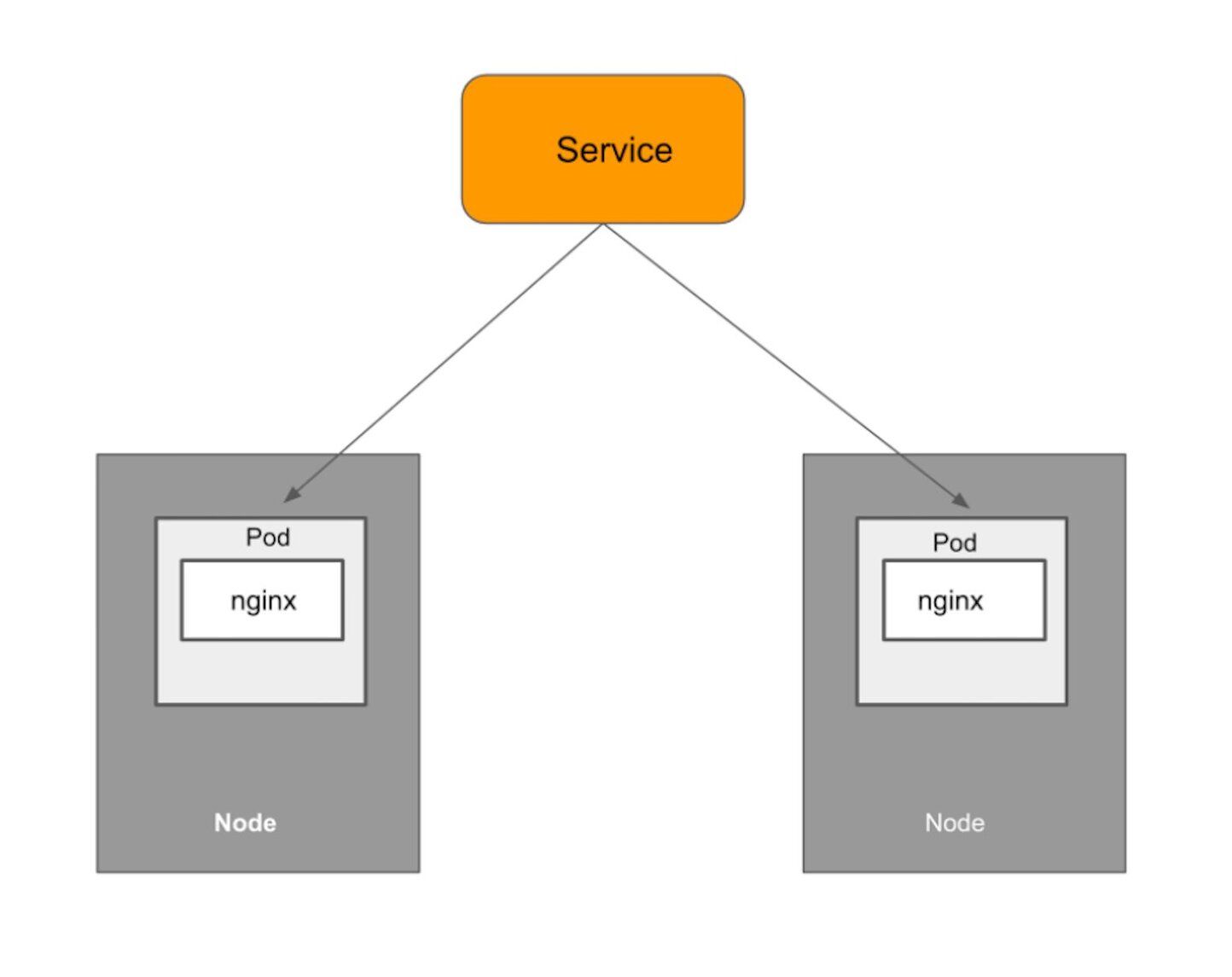
Let's scale the Deployment to 4 replicas. We are going to use the
kubectl scale command, followed by the deployment type, name, and desired number of instances. The output is similar to this:The change was applied, and we have 4 instances of the application available. Next, let's check if the number of Pods changed. There should now be 4 Pods running in the cluster (as shown in the diagram below)
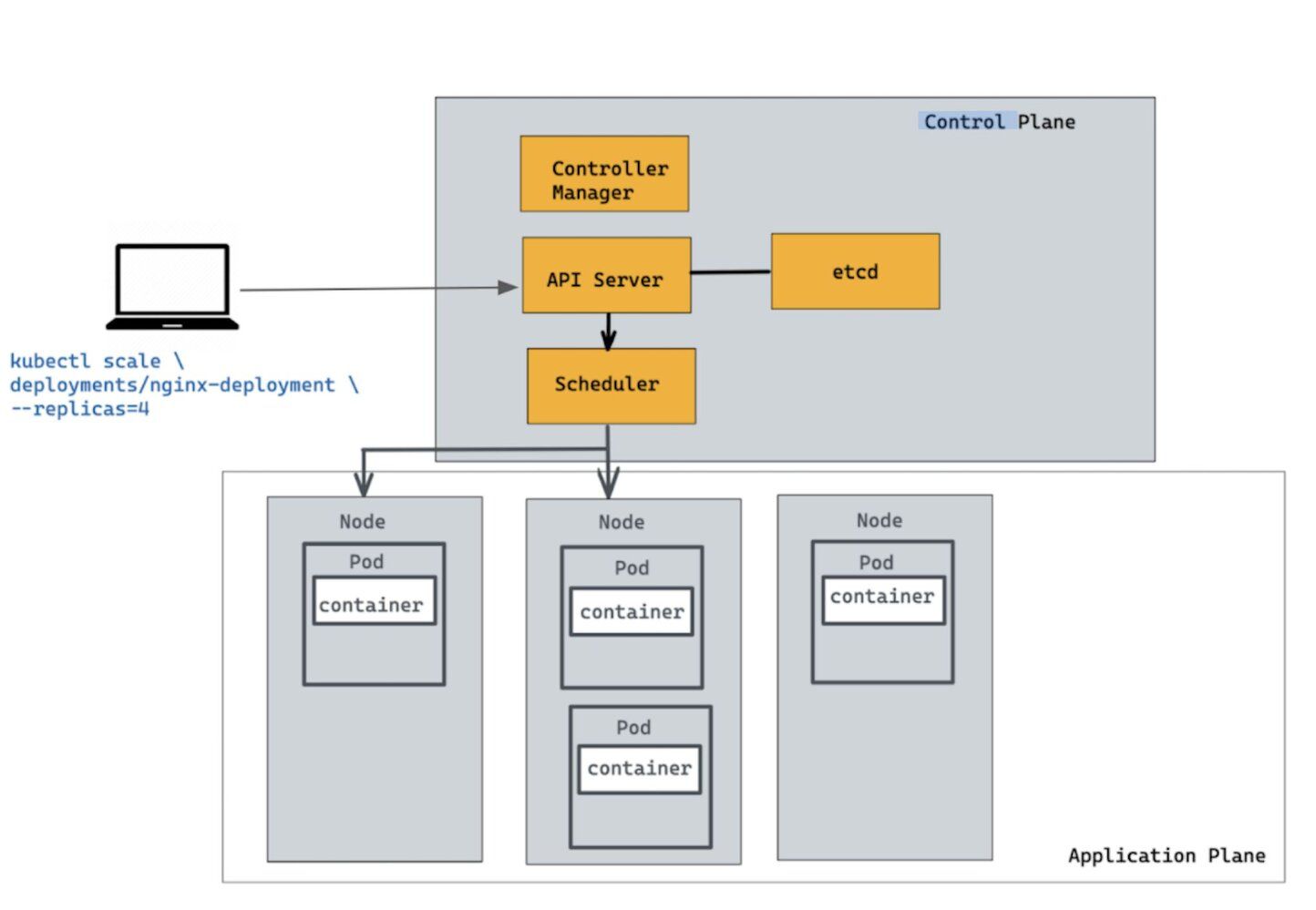
There are 4 Pods, with different IP addresses. The change was registered in the Deployment events log.
Deleting one of the web server Pods triggers work in the control plane to restore the desired state of four replicas. Kubernetes starts a new Pod to replace the deleted one. In this excerpt, the replacement Pod shows a STATUS of ContainerCreating:
You will notice that the Nginx static web server is interchangeable with any other replica, or with a new Pod that replaces one of the replicas. It doesn't store data or maintain state in any way. Kubernetes doesn't need to make any special arrangements to replace a failed Pod, or to scale the application by adding or removing replicas of the server. Now you might be thinking, what if you want to store the state of the application? Great question.
#Scaling stateful application is hard
Scaling stateless applications in Kubernetes is easy but it's not the same case for stateful applications. Stateful applications require manual intervention. Bringing Pods up and down is not that simple. Each Node has an identity and some data attached to it. Removing a Pod means losing its data and disrupting the system.
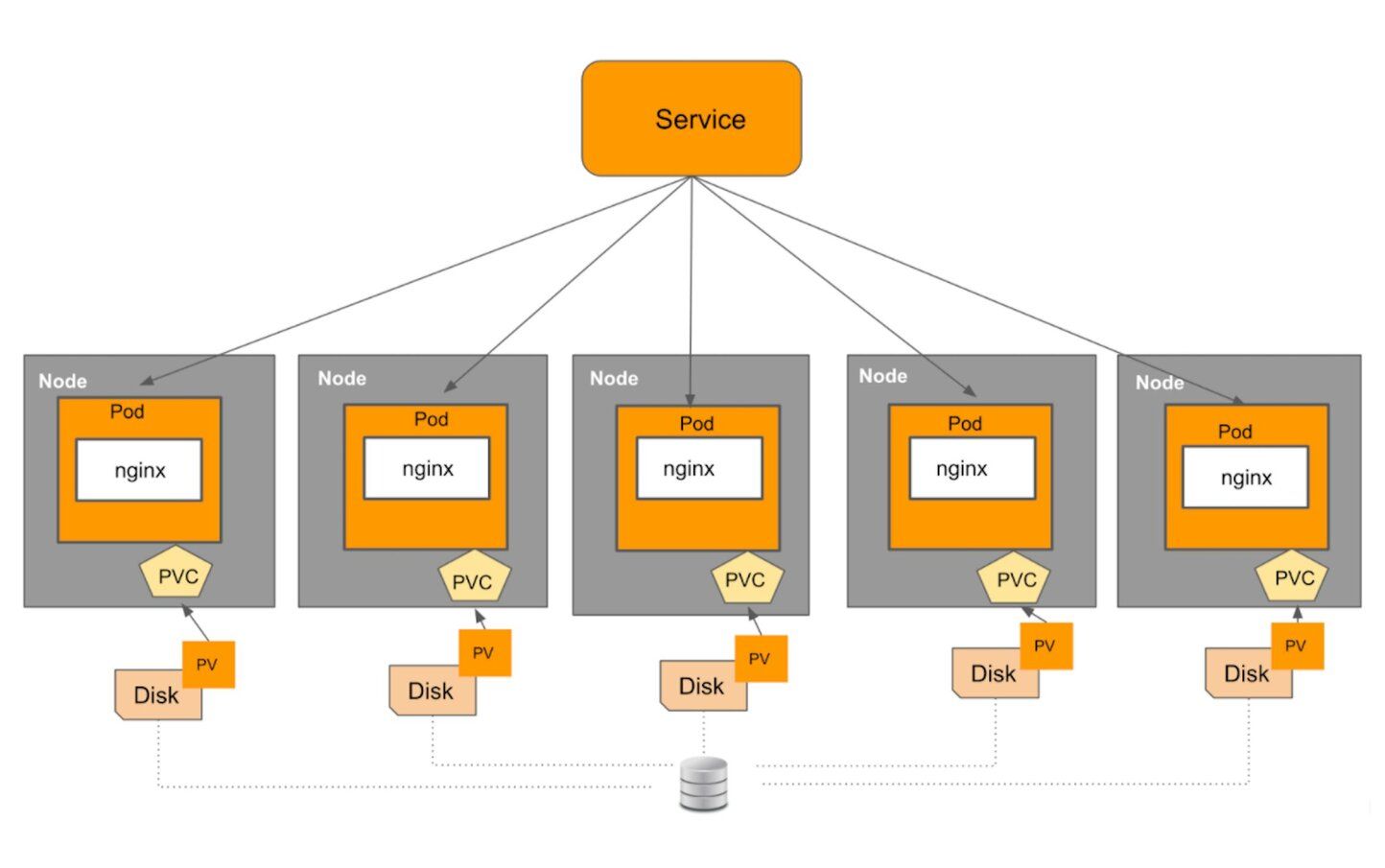
Consider a Kubernetes cluster with 6 worker Nodes hosting a Nginx web application connected to a persistent volume as shown above. Here is the snippet of StatefulSets YAML file:
Kubernetes makes physical storage devices available to your cluster in the form of objects called Persistent Volumes. Each of these Persistent Volumes is consumed by a Kubernetes Pod by issuing a PersistentVolumeClaim object, also known as PVC. A PVC object lets Pods use storage from Persistent Volumes. Imagine a scenario in which we want to downscale a cluster from 5 Nodes to 3 Nodes. Suddenly removing 2 Nodes at once is a potentially destructive operation. This might lead to the loss of all copies of the data. A better way to handle Node removal would be to first migrate data from the Node to be removed to other Nodes in the system before performing the actual Pod deletion. It is important to note that the StatefulSet controller is necessarily generic and cannot possibly know about every possible way to manage data migration and replication. In practice, however, StatefulSets are rarely enough to handle complex, distributed stateful workload systems in production environments.
Now the question is, how to solve this problem? Enter Operators. Operators were developed to handle the sophisticated, stateful applications that the default Kubernetes controllers aren't able to handle. While Kubernetes controllers like StatefulSets are ideal for deploying, maintaining, and scaling simple stateless applications, they are not equipped to handle access to stateful resources, or to upgrade, resize, and backup of more elaborate clustered applications such as databases. A Kubernetes Operator fills in the gaps between the capabilities and automation provided by Kubernetes and how your software uses Kubernetes for automation of tasks relevant to your software.
An Operator is basically an application-specific controller that can help you manage a Kubernetes application. It is a way to package, run, and maintain a Kubernetes application. It is designed to extend the capabilities of Kubernetes, and also simplify application management. This is especially useful for stateful applications, which include persistent storage and other elements external to the application, and may require extra work to manage and maintain.
#Functions of Kubernetes Operator
A Kubernetes Operator uses the Kubernetes API to create, configure, and manage instances of complex stateful applications on behalf of a Kubernetes user. There is a public repository called OperatorHub.io that is designed to be the public registry for finding Kubernetes Operator backend services. With Operator Hub, devs can easily create an app based on an operator without going through the complexity of crafting an operator from scratch.
Below are a few examples of popular Kubernetes Operators and their functions and capabilities.
#Kubernetes Operators
- Helps you deploy an application on demand (for example, Argo CD operator (Helm is a declarative, GitOps continuous delivery tool for Kubernetes that helps with easy installation and configuration on demand)
- Helps you install applications with the required configurations and number of application instances
- Allows you to take and restore backups of the application state (for example, Velero operator manages disaster recovery, backup, and restoration of cluster components such as pv, pvc, deployments, etc., to aid in disaster recovery)
- Handles the upgrades of the application code plus the changes, such as database schema (for example, Flux is a continuous delivery solution for Kubernetes that allows automating updates to configuration when there is new code to deploy)
- Can manage a cluster of database servers (for example, MariaDB operator creates MariaDB server and database easily by defining simple custom resource)
- Can install a database cluster of a declared software version and number of members
- Scale applications in or out
- Continues to monitor an application as it runs (for example, Prometheus Operator simplifies the deployment and configuration of Prometheus, Alertmanager, and related monitoring components)
- Initiate upgrades, automated backups, and failure recovery, simulating failure in all or part of your cluster to test its resilience
- Allows you to publish a service to applications that don't support Kubernetes APIs to discover them
#How does an Operator work?
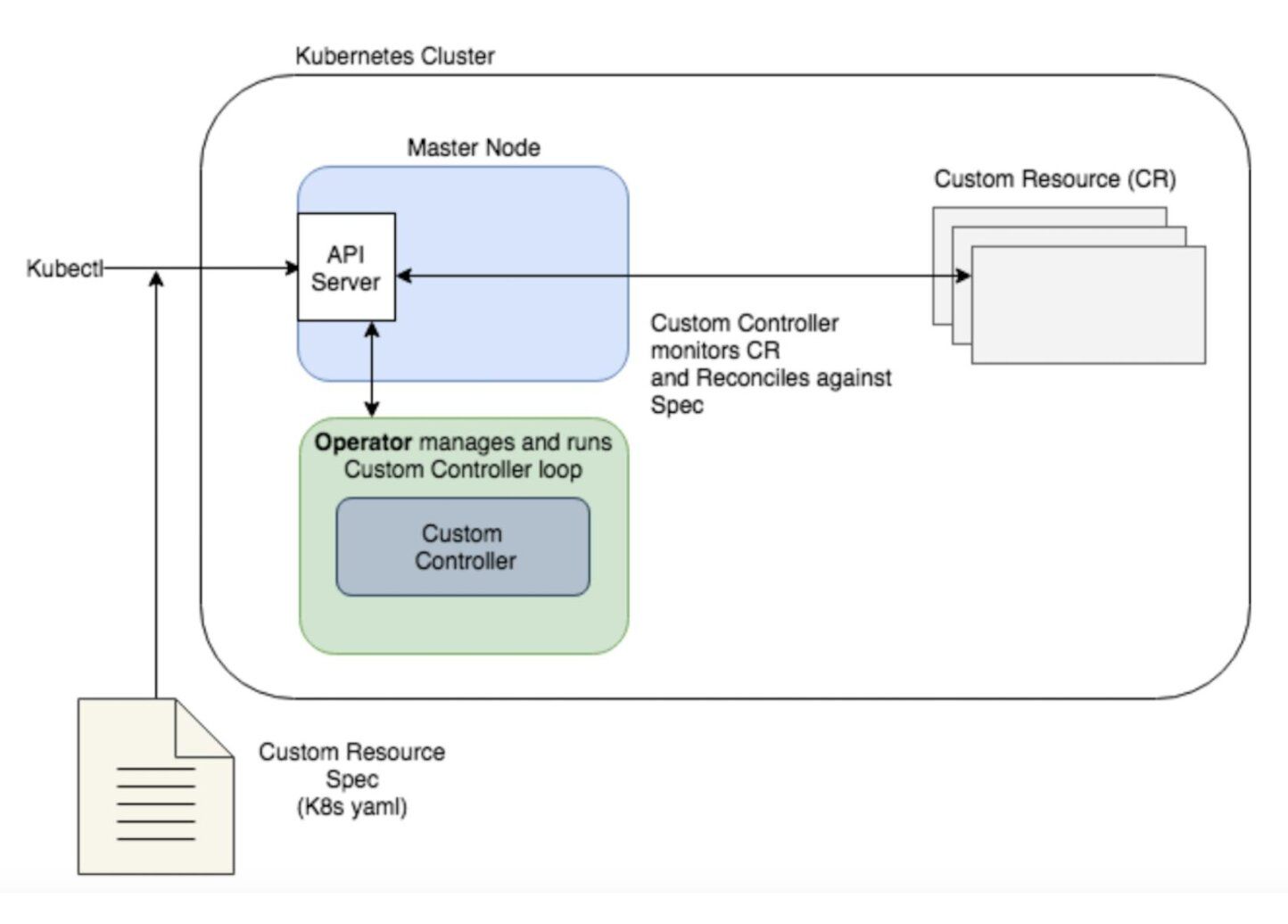
Operators work by extending the Kubernetes control plane and API. Operators allows you to define a Custom Controller that watches your application and performs custom tasks based on its state. The application you want to watch is usually defined in Kubernetes as a new object: a Custom Resource (CR) that has its own YAML spec and object type that is well understood by the API server. That way, you can define any specific criteria in the custom spec to watch out for, and reconcile the instance when it doesn't match the spec. The way an Operator's controller reconciles against a spec is very similar to native Kubernetes controllers, though it is using mostly custom components.
#What is the Redis Operator?
Redis has created an Operator that deploys and manages the lifecycle of a Redis cluster. The Redis Operator is the fastest, most efficient way to deploy and maintain a Redis cluster in Kubernetes. The Operator creates, configures, and manages Redis deployments from a single Kubernetes control plane. This means that you can manage Redis instances on Kubernetes just by creating native objects, such as a Deployment, ReplicaSet, StatefulSet, etc. Operators allow full control over the Redis cluster lifecycle.
The Redis Operator acts as a custom controller for the custom resource Redis cluster, or "REC", which is defined through Kubernetes CRD (customer resource definition) and deployed with a YAML file. The Redis Operator functions as the logic "glue" between the Kubernetes infrastructure and the Redis cluster.
#How does the Redis Operator work?
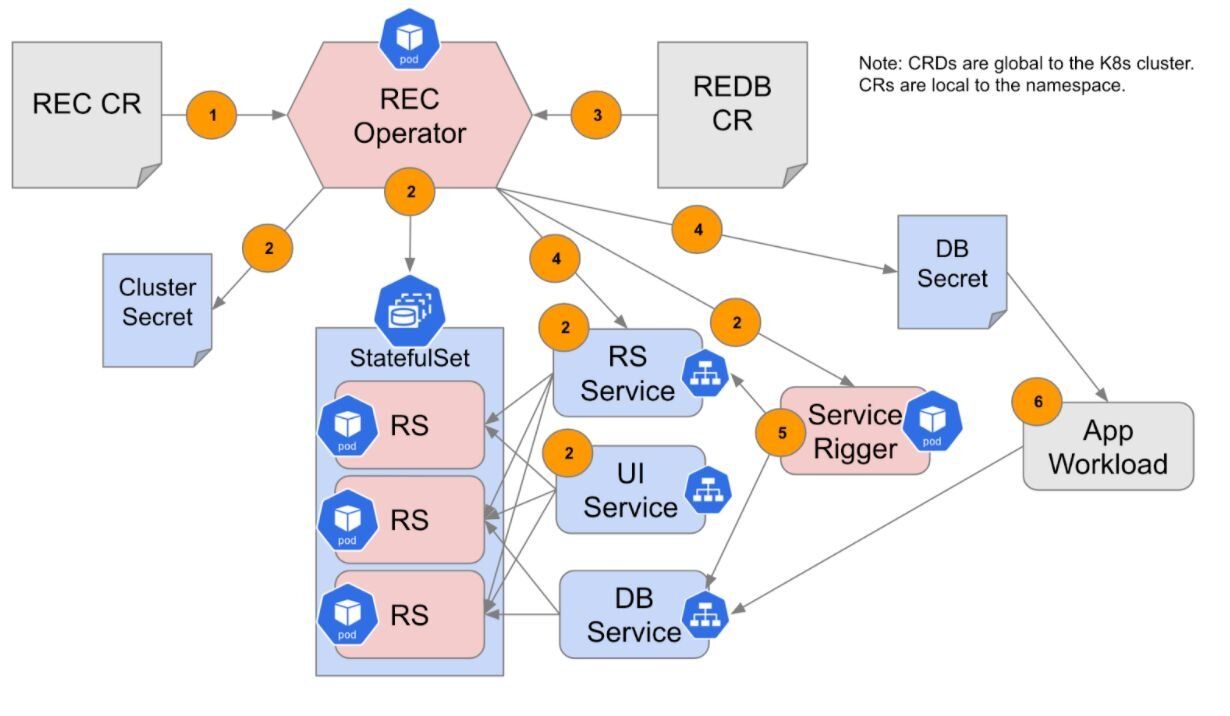
The Redis Operator supports two Custom Resource Definitions (CRDs):
- Redis Cluster (RC): An API to create Redis clusters. Note that only one cluster is supported per Operator deployment.
- Redis Database (RDB): An API to create Redis databases running on the Redis cluster. Note that the Redis Operator is namespaced. See high-level architecture and overview of the solution.
This is how it works:
- First, the Redis cluster custom resource ("CR" for short) is read and validated by the operator for a cluster specification.
- Secondly, cluster StatefulSet, service rigger, cluster admin secrets, RS/UI services are created.
- A Redis Database CR is read and validated by the operator.
- The database is created on the cluster and the database access credentials are stored in a Kubernetes secret object.
- The service rigger discovers the new database and configures the Kubernetes service for the database.
- An application workload uses the database secret and service for access to data.
#Example of Operator automation
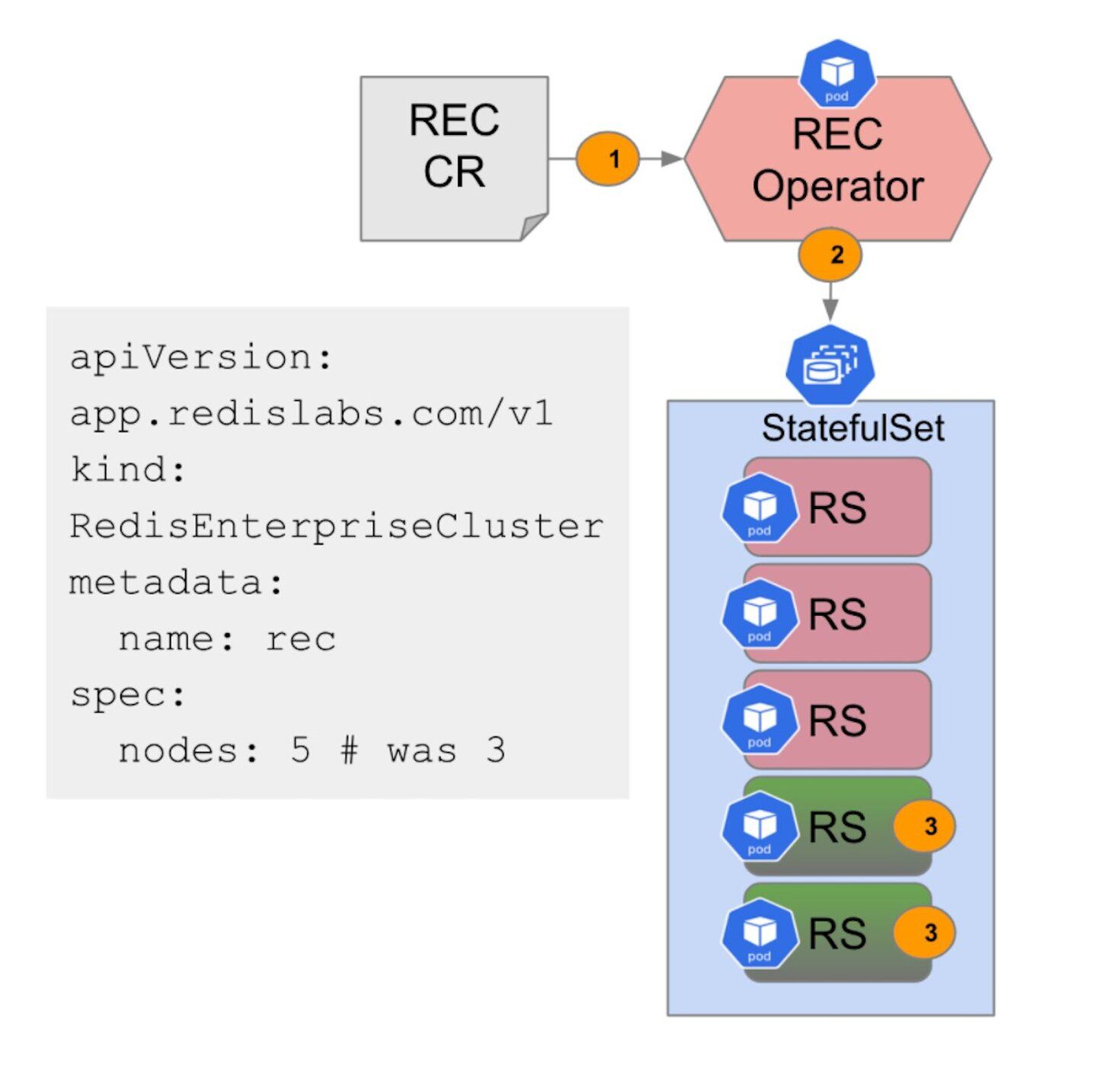
Consider the YAML file below:
If you change the number of nodes to 5, the Operator talks to StatefulSets, and changes the number of replicas from 3 to 5. Once that happens, Kubernetes will take over and bootstrap new nodes one at a time, deploying Pods accordingly. As each becomes ready, the new Nodes join the cluster and become available to Redis master nodes.
In order to create a database, the Operator discovers the resources, talks to the cluster RestAPI, and then it creates the database. The server talks to the API and discovers it. The DB creates a Redis database service endpoint for that database and that will be available.
#Next steps
- Create a Redis database on Google Kubernetes Engine (GKE) — a hands-on tutorial for deploying Redis on a managed Kubernetes cluster
- Redis Kubernetes Architecture — learn how Redis Software integrates with Kubernetes
- Redis Kubernetes Operator-based Architecture — deep dive into how the Operator manages Redis clusters
- Sizing and Scaling a Redis Cluster on Kubernetes — best practices for production sizing
- Redis Enterprise Operator on OperatorHub.io — install the Redis Enterprise Operator via OLM