Blog
Building LLM Applications with Redis on Google’s Vertex AI Platform

Google’s Vertex AI platform recently integrated generative AI capabilities, including the PaLM 2 chat model and an in-console generative AI studio. Here, you learn about a novel reference architecture and how to get the most from these tools with your existing Redis investment.
Generative AI, a fast-growing AI subset, has captured significant attention for its potential to transform entire industries. Google’s Google Cloud Platform (GCP) has been making strides to democratize access to generative AI to make adoption easier, and the company is backing it with robust security, data governance, and scalability.
Recently, Google announced generative AI support on Vertex AI with four new foundation models:
- Imagen excels at tasks such as image generation, image editing, image captioning, and visual question answering.
- PaLM 2 for Chat, an extension of the PaLM 2 family, is designed for multi-turn chat applications. Its goal is to significantly enhance what customer service chatbots can accomplish.
- Codey caters to coding tasks, with support for code generation and code chat.
- Chirp is a speech model that enables a more inclusive communication platform. It supports over 100 languages.
The language model building blocks
An application’s ability to produce, comprehend, and engage with human language is becoming essential. The need for this functionality spans numerous domains, from customer service chatbots and virtual assistants to content generation. And it is achievable thanks to foundation models, such as Google’s PaLM 2, that were meticulously trained to generate human-like text.
Amidst this dynamic environment, two fundamental components consistently stand out as critical for the creation of efficient, scalable language model applications: foundation models and a high-performance data layer.
Foundation models
Foundation models, of which large language models (LLMs) are a subset, are the cornerstone of generative AI applications. LLMs are trained on vast collections of text, which enables them to create contextually relevant, human-like text for an array of tasks. Improvements in these models have made them more sophisticated, leading to more refined and effective responses to user inputs. The chosen language model significantly impacts an application’s performance, cost, and overall quality.
Yet, for all their capabilities, models such as PaLM 2 have limitations. When they lack domain-specific data, the models’ relevance can wane, and they might lag in reflecting fresh or correct information.
There are hard limits to the context length (i.e number of tokens) that LLMs can handle in prompts. Plus, LLM training or fine-tuning requires substantial computational resources that add considerable cost.
Balancing these limitations with the potential benefits requires careful strategy and a robust infrastructure.
You need a high-performance data layer
An efficient LLM application is underpinned by a scalable, high-performance data layer. This component ensures high-speed transactions with low latency, which is crucial for maintaining fluid user interactions. It plays a vital role in caching pre-computed responses or embeddings, storing a history of past interactions (persistence), and conducting semantic searches to retrieve relevant context or knowledge.
Vector databases have emerged as one popular solution for the data layer. Redis invested in vector search well before the current wave, and the technology reflects our experience–particularly with performance considerations. That experience is reflected in the just-announced Redis 7.2 release, which includes a preview of scalable search features that improves queries per second by 16X, compared to the previous version.
Foundation models and vector databases have sparked substantial interest (and hype) in the industry, given their pivotal role in molding LLM applications across different sectors. For example, some newer standalone vector database solutions, such as Pinecone, announced strong funding rounds, and are investing a lot of effort into gaining developer attention. Yet, with all of the new tools emerging each week, it’s hard to know where to put your trust to be enterprise-ready.
What sets GCP apart is its unified offering. It marries the availability of powerful foundation models with scalable infrastructure and a suite of tools for tuning, deploying, and maintaining these models. Google Cloud places paramount importance on reliability, responsibility, and robust data governance, ensuring the highest level of data security and privacy. Guided by its publicly declared AI principles, GCP champions beneficial use, user safety, and ethical data management, providing a dependable and trustworthy application foundation.
However, to truly tap into these advancements, a complementary high-performing and scalable data layer is indispensable.
Naturally, this is where Redis steps in. In the subsequent sections, we dissect these core components and explore their interaction through a reference architecture.
A reference architecture for scalable language model applications
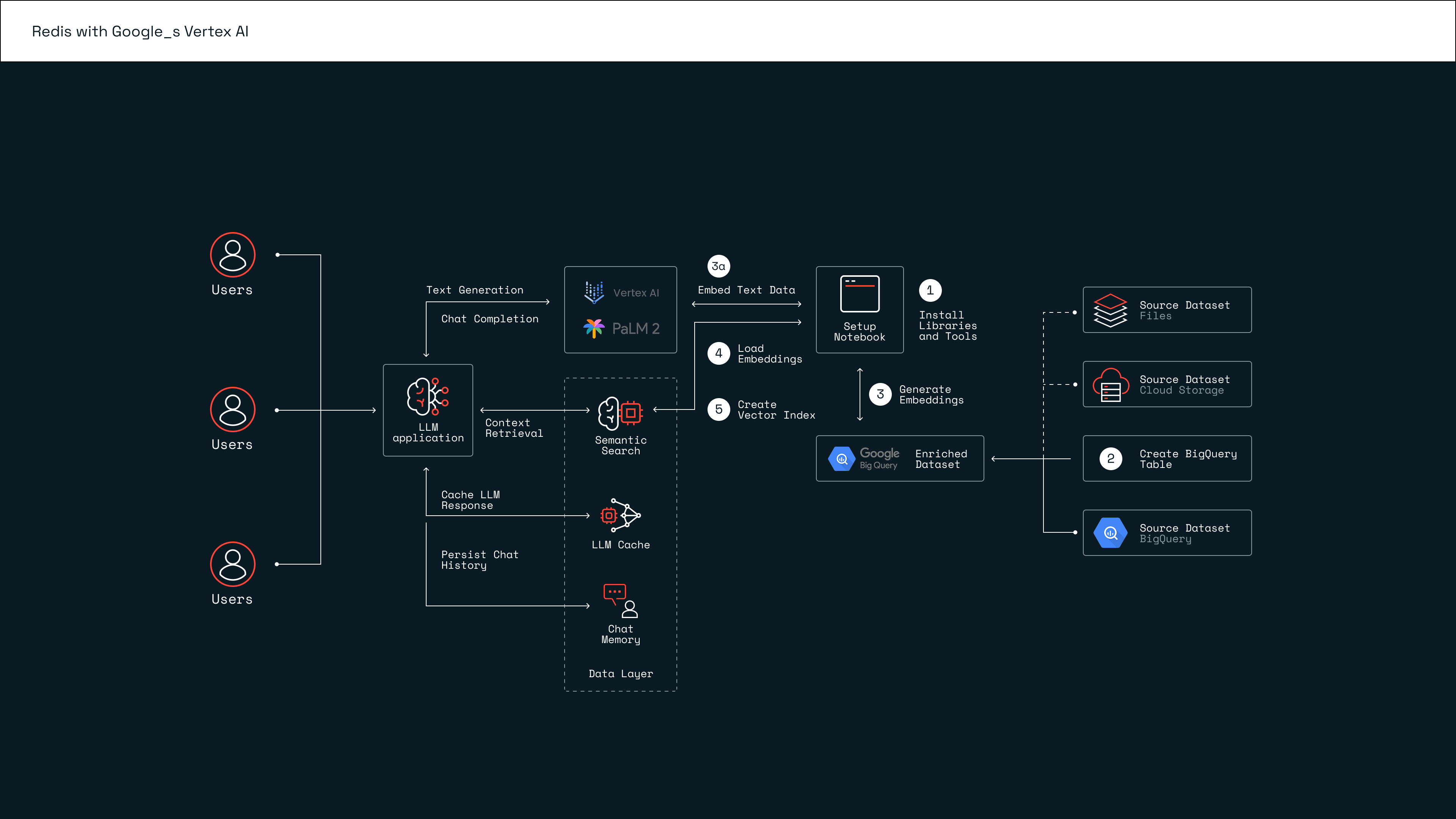
GCP and Redis Enterprise reference architecture for LLM applications
The reference architecture illustrated here is for general-purpose LLM use cases. It uses a combination of Vertex AI (PaLM 2 foundation model), BigQuery, and Redis Enterprise.
GCP and Redis Enterprise reference architecture for LLM applications
You can follow along with the setup of this LLM architecture step-by-step using the Colab notebook in an open-source GitHub repository.
- Install the libraries and tools. Install the required Python libraries, authenticate with Vertex AI, and create a Redis database.
- Create the BigQuery table(s). Load a dataset into a BigQuery table in your GCP project.
- Generate text embeddings. Loop through records in the dataset to create text embeddings with the PaLM 2 embeddings API.
- Load embeddings. Load the text embeddings and some metadata to the running Redis server.
- Create a vector index. Run Redis commands to create a schema and a new index structure that allows for real-time search.
Once you complete the necessary setup steps, this architecture is primed to facilitate a multitude of LLM applications, such as chatbots and virtual shopping assistants.
The most important LLM concepts you need to know
Even experienced software developers and application architects can get lost in this new knowledge domain. This short summary should bring you up to speed.
Semantic search
Semantic search extracts semantically similar content from an expansive knowledge corpus. Doing so depends on the power of Natural Language Processing (NLP), foundation models like PaLM 2, and a vector database. In this process, knowledge is transformed into numerical embeddings that can be compared to find the most contextually relevant information to a user’s query.
Redis, in its role as a high-performing vector database, excels at indexing unstructured data, which enables efficient and scalable semantic search. Redis can enhance an application’s capacity to swiftly comprehend and react to user queries. Its robust search index facilitates accurate, responsive user interactions.
Retrieval-augmented generation
The Retrieval-Augmented Generation (RAG) approach uses methods like semantic search to dynamically infuse factual knowledge into a prompt before it’s sent to a LLM. The technique minimizes the need to fine-tune an LLM on proprietary or frequently changing data. Instead, RAG permits contextual augmentation of the LLM, equipping it to better tackle the task at hand, whether that’s answering a specific question, summarizing retrieved content, or generating fresh content. RAG is typically implemented within the scope of an agent.
Agents involve an LLM making decisions about which actions to take, taking the stated action, making observations, and iterating until complete. LangChain provides a common interface for agent development.
Redis, as a vector database and full text search engine, facilitates the smooth functioning of RAG workflows. Owing to its low-latency data retrieval capabilities, Redis is often a go-to tool for the job. It ensures that a language model receives the necessary context swiftly and accurately, promoting efficient AI agent task execution.
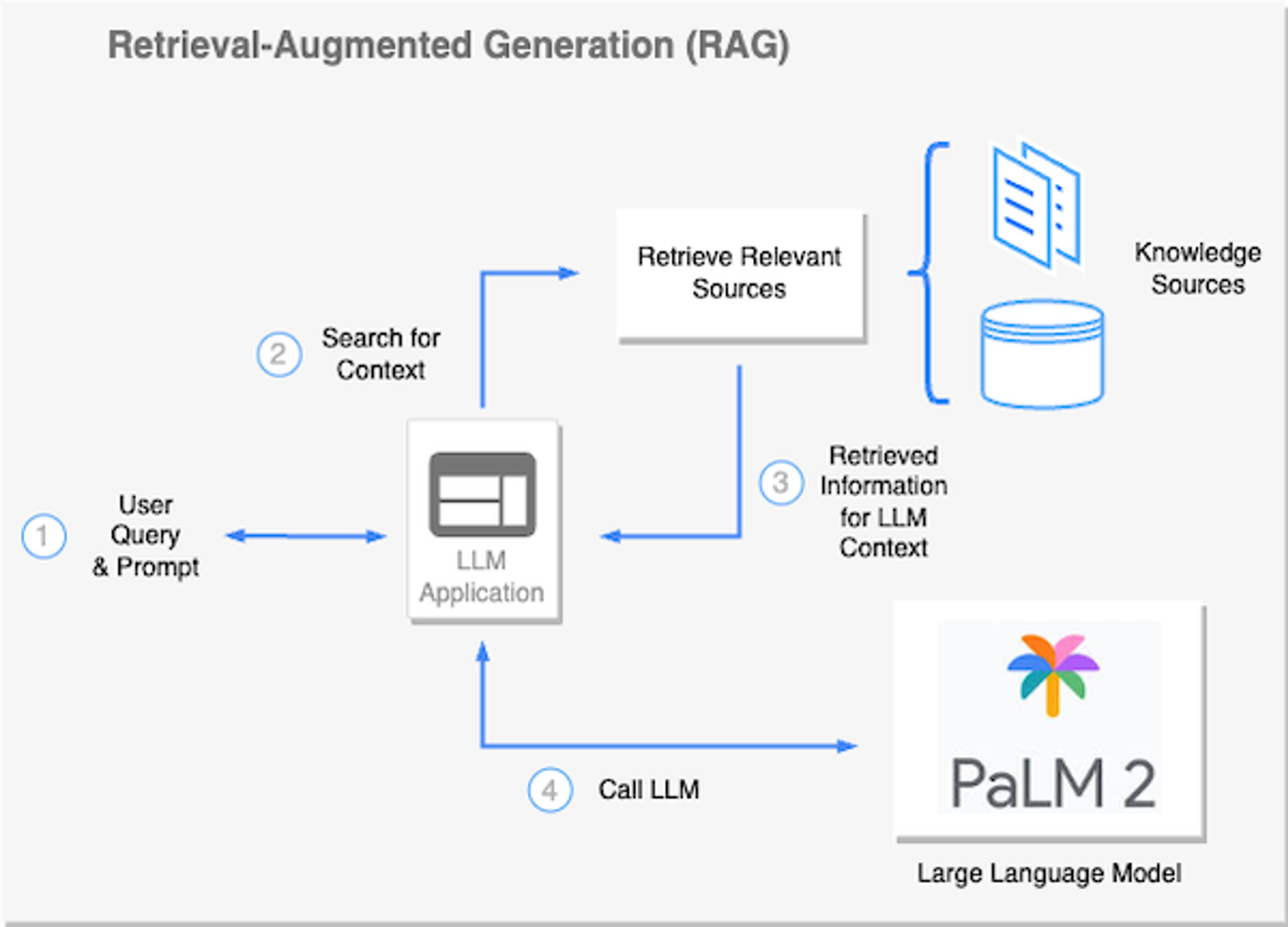
Example of a RAG architecture
Caching for LLMs
Caching serves as a potent technique to enhance LLM responsiveness and computational efficiency.
Standard caching provides a mechanism to store and quickly retrieve pregenerated responses for recurrent queries, thereby reducing computational load and response time. However, in a dynamic conversational context with human language, identically matching queries are rare. This is where semantic caching comes into play.
Semantic caching understands and leverages queries’ underlying semantics. Semantic caching identifies and retrieves cached responses that are semantically similar enough to the input query. This ability dramatically increases the chances of cache hits, which further improves response times and resource utilization.
For instance, in a customer service scenario, multiple users might ask similar frequently-asked-questions but use different phrasing. Semantic caching allows LLMs to respond swiftly and accurately to such queries without redundant computations.
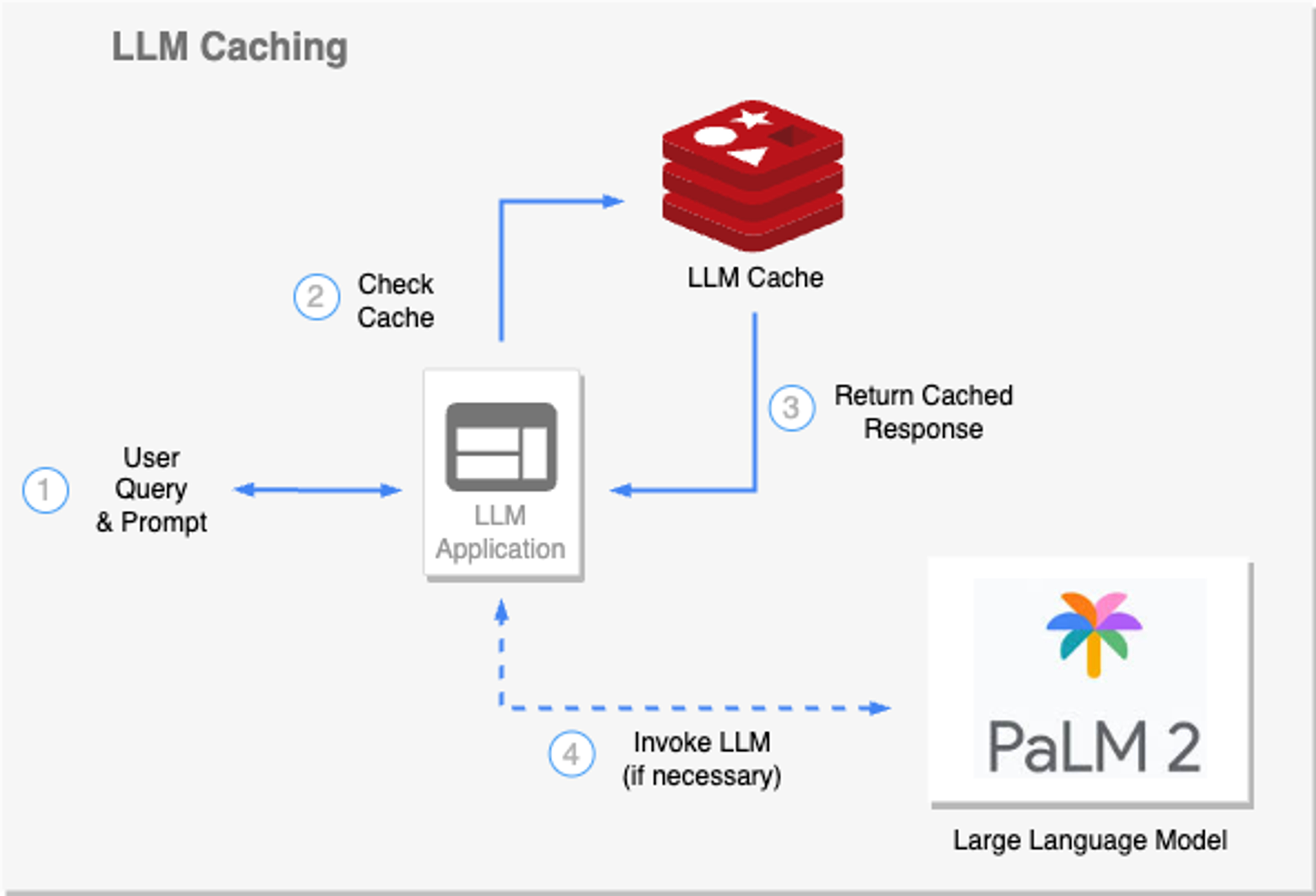
Caching for LLMs
Redis is highly suited for facilitating caching in LLMs. Its robust feature set includes support for Time-To-Live (TTL) and eviction policies for managing ephemeral data. Coupled with its vector database capabilities for semantic searches, Redis enables efficient and rapid retrieval of cached responses, resulting in a noticeable boost in LLM response speed and overall system performance, even under heavy loads.
Memory and persistence
It is important to retain past interactions and session metadata to ensure contextually coherent and personalized dialogues. However, LLMs do not possess adaptive memory. That makes it crucial to rely on a dependable system for swift conversational data storage.
Redis offers a robust solution for managing LLM memory. It efficiently accesses chat history and session metadata, even under substantial demand. Using its data structure store, Redis handles traditional memory management, while its vector database features facilitate the extraction of semantically related interactions.
Where LLMs make sense
What does it matter? Who needs these features? These three scenarios demonstrate the practical application of this LLM architecture.
Document retrieval
Some businesses need to handle vast volumes of documents, an LLM empowered application can serve as a potent tool for document discovery and retrieval. Semantic search aids in pinpointing pertinent information from an extensive corpus of knowledge.
Virtual shopping assistants
An LLM can serve as the backbone for a sophisticated ecommerce virtual shopping assistant. Using contextual understanding and semantic search, it can comprehend customer inquiries, offer personalized product recommendations, and even simulate conversational interactions, all in real time.
Customer service agents
Deploying an LLM as a customer service agent can revolutionize customer interactions. Beyond answering frequent queries, the system can engage in complex dialogue, providing bespoke assistance while learning from past interactions.
Why Redis and Google Cloud?
A whirlwind of new products and buzzwords can easily lead to a shiny object syndrome. Amidst this cacophony, the combination of GCP and Redis shines through, providing not just an innovative solution but a reliable and time-tested foundation.
Grounded in factuality: GCP and Redis empower LLM applications to be more than just advanced text generators. By swiftly injecting domain-specific facts from your own sources at runtime, they ensure your applications deliver factual, accurate, and valuable interactions that are specifically tailored to your organization’s knowledge base.
Architectural simplification: Redis is not just a key-value database; it’s a real-time data Swiss army knife. By eliminating the need for managing multiple services for different use cases, it vastly simplifies your architecture. As a tool that many organizations already trust for caching and other needs, Redis’ integration in LLM applications feels like a seamless extension rather than a new adoption.
Optimized for performance: Redis is synonymous with low-latency and high-throughput data structures. When coupled with GCP’s unrivaled computing prowess, you have an LLM application that not only talks smart but also responds swiftly, even under heavy demand scenarios.
Enterprise readiness: Redis isn’t the new kid on the block. It’s a battle-tested, open-source database core, reliably serving Fortune 100 companies worldwide. With achievable five nines (99.999%) uptime in its enterprise offering and bolstered by GCP’s robust infrastructure, you can trust in a solution that’s ready to meet enterprise demand.
Accelerate time to market: With Redis Enterprise available at your fingertips via the GCP Marketplace, you can put more focus on crafting your LLM applications and less on wrangling with setups. This ease of integration speeds time to market, giving your organization a competitive edge.
While new vector databases and generative AI products might create a lot of noise in the market, the harmony of GCP and Redis sings a different tune–one of trust, reliability, and steadfast performance. These time-tested solutions aren’t going anywhere soon, and they’re ready to power your LLM applications today and for years to come.
Interested in learning more?
Redis will attend Google Next ‘23 between August 29-31 in San Francisco. We invite you to visit the Redis booth, #206, where we’re happy to talk about the details.
Ready to get your hands dirty now? You can set up Redis Enterprise through the GCP Marketplace and work through the getting started tutorial.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.