Blog
Context engineering: Best practices for an emerging discipline

LLMs can perform an enormous amount of tasks – that much is now undeniable – but building performance-grade software with LLMs is still difficult because we don’t know which tasks an LLM will succeed at until we try. This is the core question at the heart of AI-based development, and context engineering is the answer.
The power of LLMs lies in their non-determinative nature, but that nature is also the source of their hallucinations and unreliability. A non-technical user just playing around with ChatGPT will quickly learn that better prompts lead to better results, so it stands to reason that professional users could turn this into a skillset. Enter prompt engineering.
Prompt engineering, both as a term and as a role, emerged in 2020 with the launch of GPT-3 and gained popularity with the launch of ChatGPT in 2022, but in 2025, the framework is showing its limitations. In 2020, given both the limitations of the LLMs themselves and our understanding of them, focusing on prompts made sense. We couldn’t see the horizon yet, and prompt improvement was low-hanging fruit – and it worked. It still works.
And yet, it’s limited. Prompt engineering, by its nature, focuses on phrasing and language tweaks, constraining our imagination to the space of the request. Context engineering zooms out to include instruction, tool calls, and knowledge, and treats context as infrastructure, not as background color.
Leaders in the field are consolidating around the term. Tobi Lutke, CEO at Shopify, and Andrej Karpathy, part of the founding team at OpenAI, both prefer it over prompt engineering. The terminology has to evolve as the research and best practices evolve.
Context, not wording, is proving to be the real bottleneck for AI-based development. The discipline will continue to be refined, but the foundation is ready to be understood, and the early best practices are ready to be put into action.
What is context engineering?
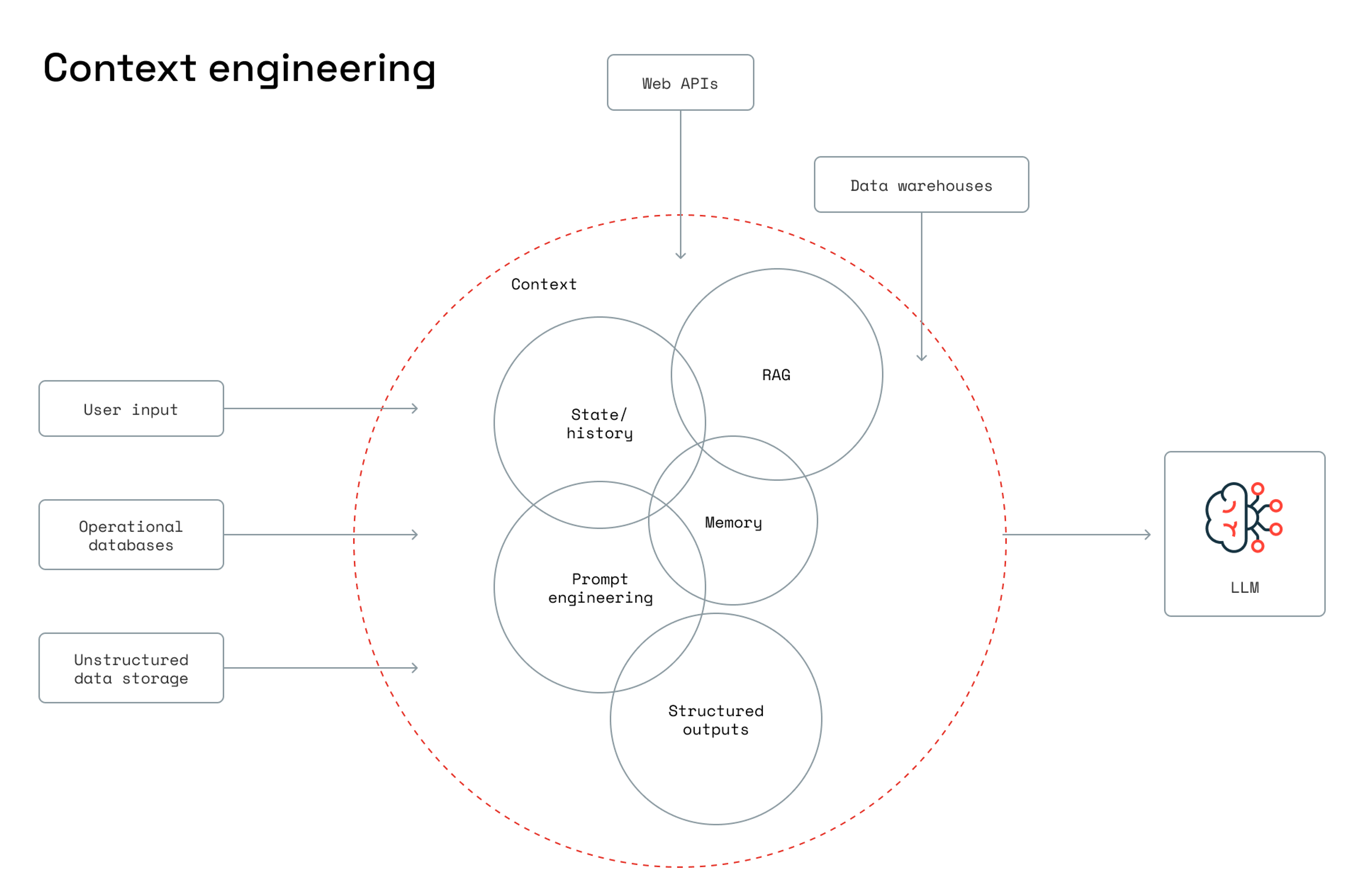
Context engineering is the discipline of systematically selecting, structuring, and delivering the right context to an LLM to improve reliability and performance.
Lutke prefers context engineering over prompt engineering because “it describes the core skill better.” For Lutke, the core skill is best understood as “the art of providing all the context for the task to be plausibly solvable by the LLM.”
Karpathy agrees, explaining that “People associate prompts with short task descriptions you'd give an LLM in your day-to-day use.” In contrast, “Context engineering is the delicate art and science of filling the context window with just the right information for the next step.”
Context engineering: Beyond buzzwords
Context engineering isn’t a new buzzword, built for the sake of hype, but an emergent concept borne from the practical limitations of prompt engineering.
Prompt-only workflows are limited and brittle, and developers started experiencing reliability issues long before this new term arose. Performance from prompts also varies from model to model, which can lead to broken apps when new models are released. Clever phrasing and templated prompts yielded diminishing returns over time.
Prompt engineering failed to deliver consistent results for production apps, even as context windows widened. Eventually, more and more developers realized they needed structured tactics for memory, retrieval, and context compaction.
Context engineering is gaining traction because, as Karpathy writes, it combines the science of task descriptions, including examples, RAG, tools, state, history, and more, with the art of the developer’s intuition.
Context engineering requires art and science because it expands beyond prompts while still requiring precision. Every token still has weight. Bigger context windows offer flexibility, but careless token usage introduces noise and drift.
The solution lies in using context, but not just stuffing the window with as much information as it can fit. As Drew Breunig has explained, overloading your context can lead to context poisoning (when a hallucination makes it into the context, context distraction (when the context overwhelms the training, context confusion (when superfluous context influences the response, and context clash (when parts of the context disagree).
The old “garbage in, garbage out” adage still applies, and your input can be garbage due to having too little context or too much. But once you can increase context while still accounting for weight, you can shift from prompting a chatbot to building agent-driven applications with systematic context management.
Context engineering vs. prompt engineering
At a high level, prompt engineering is ad hoc, and context engineering is systemic.
That doesn’t mean one is better than the other in all cases, but it does mean that prompt engineering is best understood as a subset of context engineering.
(Source)
Sometimes, all you need is a good prompt. You should realize, though, that if you’re only using a prompt, you’re only using one element of all the context you could be providing.
Prompt engineering is best for:
- One-off requests in a conversational tone.
- Tasks that can be guided by intuition or “vibes” alone.
- Functions that can be solved by iteratively and reactively adding details.
- Simple, chat-based interactions.
Context engineering is best for:
- Structured, programmatic, and repeatable workflows.
- Storing and using metadata (including preferences, conversation summaries, and last active timestamps) in an LLM application.
- Apps, pipelines, and production agents.
Prompts are just one input. Context engineering includes prompts as well as retrieved knowledge, long-term memory, tool calls, and structured formatting (e.g., JSON). With complete, relevant inputs, including source code, design docs, and data schemas, context engineering enables developers to reduce error and hallucination rates when they use LLMs.
As LLMs evolve, and AI-based engineering with it, context engineering is how we’ll professionalize and scale their results.
Context engineering management: Best practices
Prompt engineering laid the groundwork, and context engineering is maturing into a discipline that development teams can learn. There are still many things to iterate on, but there are tried and true places to start.
If you want to build agentic AI, which 70% of executives believe is important to their organization’s future, according to 2025 IBM research, then you need to learn context engineering. As Philipp Schmid, Senior AI Relation Engineer at Google DeepMind, writes, with the advancement of foundation models, “Most agent failures are not model failures anymore, they are context failures.”
Use the pyramid approach for prompts
Journalists, when they write about breaking news that requires background information to understand, follow the “inverted pyramid” model, which starts with the most newsworthy information at the top of the article, then adds important details as the article goes on, and then ends with more general background information.
Developers building context for AI agents don’t have to worry about hooking distracted, human readers, so they should reset the pyramid: Start with the general background information and then move to more and more specific details.
The background information structures and shapes how the agent interprets the following, narrower information. You wouldn’t want a coding agent, for example, to start planning a coding task without knowing your codebase and its coding conventions.
As Salvatore Sanfilippo, Redis’s founder (now Redis evangelist), writes, “When your goal is to reason with an LLM about implementing or fixing some code, you need to provide extensive information to the LLM: papers, big parts of the target code base (all the code base if possible, unless this is going to make the context window so large than the LLM performances will be impaired). And a brain dump of all your understanding of what should be done.”
Provide a reason and rationale alongside each piece of context to help the LLM understand the task’s purpose and how the context fits in. Throughout, prioritize being as clear as possible, as you would with a human teammate: Keep formatting and templates consistent to reduce ambiguity, and give explicit, descriptive instructions that include goals, constraints, and audiences. Where possible, include concrete examples to minimize guesswork.
Apply Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation, or RAG, is the process of grounding AI queries and inputs in approved data sources (often internal documentation), and it’s essential to providing agents the proper context.
“The secret to building truly effective AI agents has less to do with the complexity of the code you write, and everything to do with the quality of the context you provide.”
“The secret to building truly effective AI agents has less to do with the complexity of the code you write, and everything to do with the quality of the context you provide.” – Philipp Schmid, Senior AI Relation Engineer at Google DeepMind
For most development teams, the highest quality context won’t be on the public Internet; it will be in private, internal data sources. As Schmid writes, “The secret to building truly effective AI agents has less to do with the complexity of the code you write, and everything to do with the quality of the context you provide.”
Many vendors offer RAG solutions and components, but the ideal solution should dynamically inject only the most relevant context at runtime, avoiding overloading the model with static or outdated information. RedisVL, for example, provides semantic caching that allows teams to use Redis’s caching capabilities and vector search to store questions previously asked through RAG.
Prune context and distill essential information
Context engineering is a balancing act between providing too much context and too little. As Karpathy writes, “Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant, and the LLM costs might go up and performance might come down.”
As a result, context pruning has to be an essential part of your agent pipeline, not an afterthought. Remove irrelevant or outdated content that creates noise, and consider tools like Provence, which can automate the pruning of unnecessary content with “negligible to no drop in performance.”
In this respect, passing context to an agent is surprisingly similar to offering context for a human teammate. As the LangChain team writes, “Just like communicating with humans, how you communicate with LLMs matters. A short but descriptive error message will go a lot further than a large JSON blob.”
The goal is to include as much context as possible while intelligently summarizing it, preserving only the essential information. This doesn’t need to be manual. LLM-powered summarization stages in your agent pipeline can generate focused, task-ready context.
This balancing act can shift depending on the task you’re asking an agent to accomplish. When Sanfilippo was writing tests for vector sets, a Redis data type too new for LLMs to understand, he added the README file into the context window. “With such a trivial trick,” Sanfilippo writes, “The LLM can use vector sets at expert level immediately.”
Store context for reuse and isolate context for focus
Context engineering builds on prompt engineering, but it requires a different framework. In prompt engineering, the primary input is the prompt itself. In context engineering, the inputs are much broader and more diverse, which requires a systems thinking perspective.
As Schmid writes, context engineering is “a system, not a string.” Context isn’t raw information fed into the LLM or a bigger prompt. “Context isn't just a static prompt template,” Schmid continues, “It’s the output of a system that runs before the main LLM call.” As you iterate on the context you provide, you can store and reuse it, turning the development of context into an infrastructure for all LLM-based work.
The ability to store context, however, doesn’t mean that you should give every agent every piece of context. Some agents have specific, narrow jobs and benefit from the clarity and focus that less context provides. Break tasks into separate, dedicated contexts to prevent cross-contamination between relevant and irrelevant contexts, and assign isolated contexts to ensure agents remain focused on the most relevant context.
Select the right tools
Similar to the balancing acts between adding and pruning context, and storing and isolating context, agents are at their best when they’re using only tools relevant to the task at hand. If agents have access to too many other tools, they can get confused, leading them to pull in more irrelevant context that could make them even more confused.
As the LangChain team writes, “Giving the LLM the right tools is just as important as giving it the right information.” To help agents pick the right tools, and not just any tool available to them, you can apply RAG to fetch tool definitions dynamically instead of preloading everything.
Why context engineering needs a memory layer
Prompt-based strategies are insufficient to support AI agents and complex, LLM-based workflows. Context engineering, if it’s just treated as an expansion of prompt engineering, risks facing the same issues. Without a memory layer, context engineering can just be prompt engineering by another name.
As Andrej Karpathy puts it, LLMs are not chatbots; they’re “the kernel process of a new Operating System.” Lance Martin, software engineer at LangChain, expands on this metaphor, writing, “The LLM is like the CPU, and its context window is like the RAM, serving as the model’s working memory.”
The analogy shows why the memory layer isn’t just an addition but an essential part of providing the right context at the right time. “Just like RAM,” Martin writes, “the LLM context window has limited capacity to handle various sources of context. And just as an operating system curates what fits into a CPU’s RAM, ‘context engineering’ plays a similar role.”
With a memory layer, developers can provide AI agents with persistence that enables both short and long-term memory functions:
- “Short-term” memory, which typically refers to active sessions or chats, can be stored with lower Time To Live (TTL) values.
- “Long-term” memory, which usually includes summaries of or key highlights from largely inactive sessions, can be preserved for future reference or rehydration.
The combination of both allows for lower token usage and reduced costs through the avoidance of repeated context injection.
“Good context engineering caches well. Bad context engineering is both slow and expensive.”
Redis, which has long provided the premier in-memory cache enabling real-time apps to run at enterprise scale, is similarly positioned to provide the backbone for the memory layer AI agents need to run reliably, efficiently, and accurately.
Returning to Lutke’s original definition, context engineering is “the art of providing all the context for the task to be plausibly solvable by the LLM.”
At production scale, the question of plausibility extends from providing the right context to maintaining reliable, robust levels of performance, scalability, and durability across the tasks that agents are performing. In the same way that it’s implausible for an agent to answer a request without context, it’s implausible for an agent to answer a request if the systems providing that context go down.
The memory layer is an important part of making context engineering effective. As Ankur Goyal, founder and CEO at Braintrust, writes, “Good context engineering caches well. Bad context engineering is both slow and expensive.” Your cache is the difference between good context engineering and agents that run inefficiently and expensively.
Redis vs. common alternatives for context management
There are numerous ways to provide and manage context, but the role of context management in context engineering is too important to accept limited approaches.
Dexter Horthy, founder of HumanLayer, puts it well, explaining, “The context window is your primary interface with the LLM.” Context engineering, as a discipline, shapes how you manage your context window and how you interface with the LLMs you’re using. That primacy means you need to be thoughtful about choosing your context management tooling.
Vector databases alone aren’t enough
Vector databases are excellent at semantic retrieval because they're designed to store embeddings and perform nearest-neighbor searches, but that specialization makes them narrow.
Their specialization allows them to store and retrieve vectors well, but it also means they lack the integrated mechanisms necessary to maintain conversation history, which requires turn-by-turn context, agentic state (including current phase and user-specific variables), and session threads that can separate parallel conversations and agent state machines.
Redis, in contrast, combines vector search with structured state and memory management. Redis offers vector similarity search capabilities (via HNSW) while supporting complex querying over structured data.
Redis also natively supports a wide range of data types, including hashes, JSON documents, lists, and modules for broad-based search and indexing. Altogether, this means you can store embedding vectors for semantic retrieval, conversation state, metadata, and session threads, offering a performant, low-latency datastore developers can use to support context engineering.
Why not just cache or SQL?
Traditional caches and SQL queries lack vector capabilities and memory semantics, making them, like vector databases, similarly incomplete.
Simple caches are optimized for speed, but they don’t support vector similarity or provide structured memory patterns. Relational systems typically involve heavier transactional overhead – introducing tens of milliseconds of latency, which is too high for real-time conversation and agent-driven interactions. Agents can often have multiple steps that require information retrieval, leading to very slow responses.
Redis advantage
Redis offers what simple caches, relational databases, and vector databases can’t – a holistic approach to memory that supports context engineering at production scale.
Redis provides:
- Unified memory and vector capabilities, including in-memory storage for chat history, session per-user or per-agent context, and memory summaries.
- Proven scalability and operational simplicity for production workloads, resulting from Redis’s clustering, replication, and high availability features.
- Deep integration with LangGraph for agent orchestration, enabling agents to maintain thread-level persistence (short-term memory) and cross-thread or session-level memory (long-term memory).
Together, these features combine semantic retrieval with structured state retrieval, all through a memory layer that is production-ready, scalable, multi-user, and persistent.
How can Redis help?
Context engineering is a maturing discipline, but it’s already clear that memory is and will remain the foundation of context engineering at its most effective and most scalable.
Short-term memory, which operates within sessions, preserves task states across multi-step processes, which can include tool outputs, prior messages, and intermediate results – all without reloading the full context.
A high-performance cache like Redis offers a way to store a rolling window of previous messages that can be continuously updated to reflect the ongoing conversation. Long-term memory, which operates across sessions, can complement a high-performance cache by persisting user preferences, history, and knowledge so that agents pick up where they left off.
Redis is built to power this memory layer through numerous features, including:
- Real-time storage: Sub-millisecond read/write performance ensures agents can retrieve or update context instantly.
- Flexible memory types: Redis supports a wide range of data types, including string, hash, list, set, sorted set, vector set, stream, bitmap, bitfield, geospatial, JSON, probabilistic data types, and time series.
- Vector capabilities: Native vector search that enables fast, semantic memory recall for RAG workflows and agent context retrieval.
- Scalability: Redis offers linear scaling to hundreds of millions of operations per second, and high availability with up to 99.999% uptime
- Developer-friendly integrations: Redis pairs seamlessly with LangGraph for composable agent memory, which reduces complexity for developers while keeping agent memory simple and modular.
To learn more, watch a demo or visit the Redis for AI page. Also, check out the memory management for AI agents webinar.
Frequently asked questions about context engineering
LLMs only “remember” what’s inside their context windows. Memory systems let agents store and retrieve relevant info beyond those windows, enabling personalized, coherent, and contextually aware responses that can extend across sessions.
Redis provides fast, in-memory storage and built-in vector search, which are, together, highly effective at storing both chat history and long-term memory, enabling scalable and low-latency memory retrieval.
Developers often overload windows with irrelevant or stale data and ignore summarizing or pruning strategies, which leads to hallucinations, confusion, and degraded performance.
Vector search lets agent systems encode text as embeddings, then semantically retrieve relevant memory, so that agents can fetch the past information accurately when context is needed.
Short‑term memory holds the recent conversation context. Long‑term memory stores enduring facts, preferences, and experiences – often as embeddings – for persistent recall and personalization.
Redis runs server‑side, offering robust, persistent, scalable in‑memory storage with vector search, unlike transient, limited, client‑side browser cache.
Yes. Redis Agent Memory Server integrates with systems like LangGraph, offering a fast persistent memory backend for AI agents.
By trimming redundant or irrelevant info, context pruning lowers token count per request, which reduces processing load and compute usage, and cuts API or inference costs.
RAG fetches relevant documents before generation, augmenting agent context with accurate, up‑to‑date info, which improves accuracy and reduces hallucinations without constant retraining.
The AI model may hallucinate, lose focus, confuse responses, consume more compute, and degrade reasoning.
Redis supports clustering, persistence, high availability, vector indexing, and the handling of billions of embeddings – all with sub-millisecond latency – which makes it production-ready for real-time, scalable AI memory.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.