Blog
From reasoning to retrieval: Solving the MCP Tool overload problem

We built powerful Agents. Then we broke them.
The Model Context Protocol (MCP) fundamentally changed how AI agents interact with enterprise systems. Instead of building custom integrations for every tool, MCP standardizes how agents connect to your entire stack.
This worked great with a handful of tools. But, then we deployed it at scale. After a certain point, giving agents more tools actually made them worse. Tool selection accuracy dropped. Response times slowed. Costs ballooned.
This is the MCP tool overload problem, and it's blocking real enterprise deployments. We solved this by treating tool selection as a retrieval problem, not a reasoning one. Token usage dropped by 98%, tool retrieval sped up by 8x, and accuracy doubled; and these improvements compounded with scale. Here's how Tool Filtering with Redis works.
Background
In MCP every capability becomes a "tool" which is a function with a name, description, and parameter schema that agents can call. A Travel Assistant might use search_flights from an Airline MCP Server to find flights, or create_event from a Calendar MCP Server to block travel dates.
The Challenge
MCP makes connecting services easy. But add enough, and costs, accuracy, and speed all take a hit.
Consider four simple MCP Servers below:
- Redis MCP Server: 44 tools
- GitHub: 40 tools
- Jira: 27 tools
- Grafana: 56 tools
Four servers. 167 tools. Roughly 60K tokens consumed before the user even asks a question. In production, we often see setups with significantly more tools and 150K+ tokens.
More tools here means more problems:
Accuracy drops. Models pick the wrong tool. Data gets overwritten. Requests go to the wrong place. The right tool gets lost in the noise.
Costs climb. Every tool's definition loads with each request. You’re consuming tokens before the model even reads the user's question.
Latency grows. The model has to read through every tool before picking one. More tools means more time needed to reason, which is often seconds that users feel immediately.
Our Solution: Tool Filtering
Instead of reasoning over every tool, Tool Filtering with Redis retrieves only what's relevant using pure vector or hybrid search.
We store all the tools and their meaning in Redis. When a user asks "why are payments failing," Redis finds the most relevant tools based on intent. Retrieving 3-5 tools instead of 50+. The model then picks the best one from a shortlist, not a haystack.
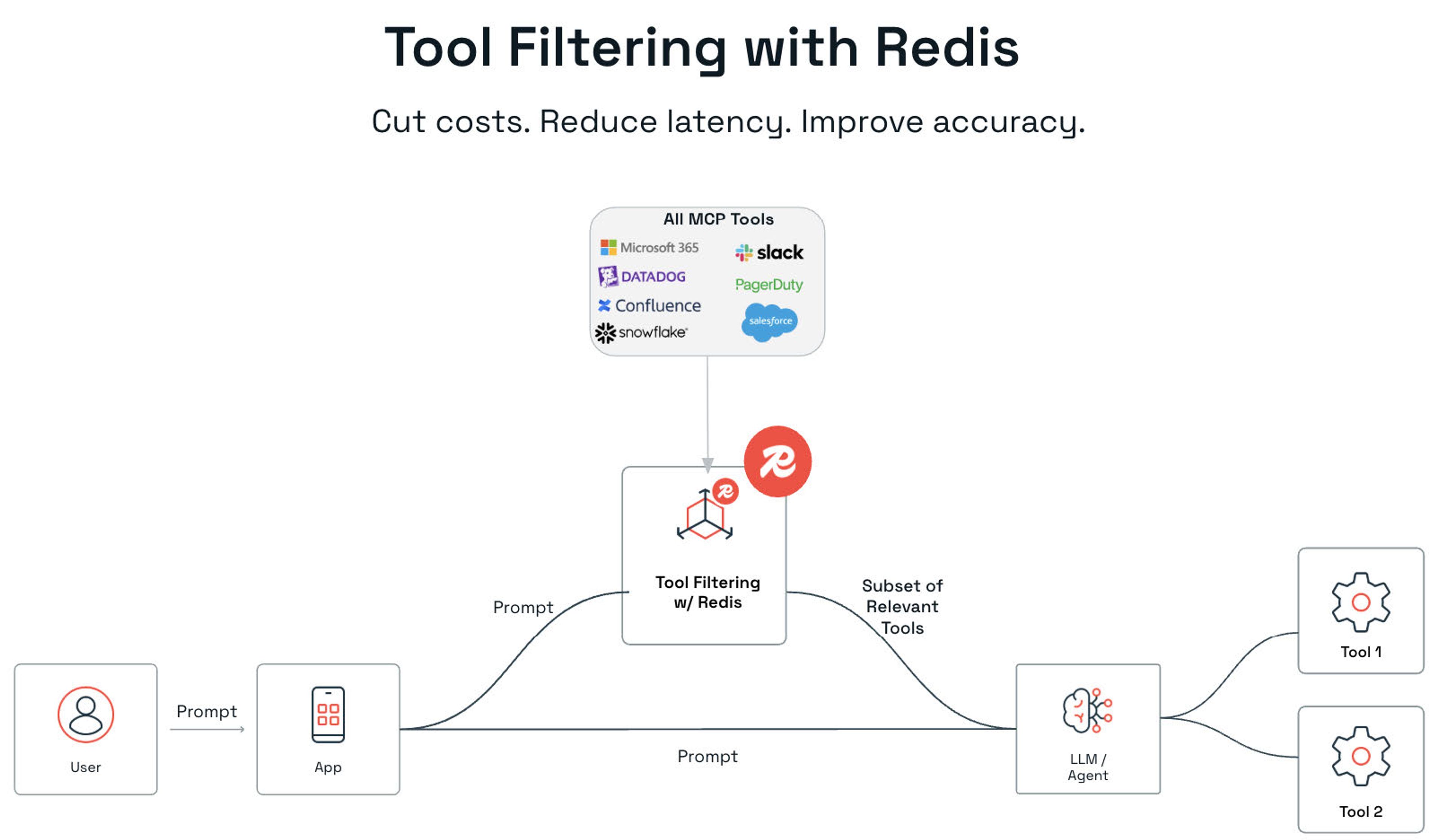
Real-world impact
We tested Tool Filtering with a customer support agent connected to just a few MCP servers.
| Metric | Without Filtering | With Redis Tool Filtering | Improvement |
|---|---|---|---|
| Token Usage | ~23k Tokens | ~0.4k Tokens | 98% reduction in token usage |
| Latency | ~3.4 sec | ~0.4 sec | 8x faster |
| Tool Selection Accuracy | ~42% | ~85% | 2x accuracy |
Performance will vary based on tool diversity, query complexity, and embedding model choice.
Consider a typical query: "Summarize today's error logs from the Payment Service." Without filtering, the model evaluated every tool, taking 3+ seconds and consuming ~23k tokens before selecting the wrong tool. With Redis’s pre-filtering, the model evaluated only 3 relevant tools, responding correctly in 392ms while consuming only 800 tokens.
Here's how it works
At startup, we generate vector embeddings for each tool's metadata, (name, description, parameters) using an embedding model. These embeddings capture what each tool actually does. We store them in Redis with an index, creating a tool catalog searchable by meaning.
At runtime, when a user sends a query:
- Embed the query using the same model
- Search Redis for semantically similar tools
- Retrieve the top-K most relevant tools (typically 3-5)
- Pass only those tools to the model for final selection
The K-value matters. Too few risks missing the right tool. Too many brings back the overload problem. Most deployments find 3-5 optimal, though this depends on your tool catalog's diversity.
Why intent matters
The community has explored different approaches to tool overload, each with trade-offs.
Another approach using hierarchical organization has agents navigate directory structures—zendesk → tickets → search_tickets. But users describe problems, not paths. A query like "why are payments failing" forces the agent to guess which tree to explore first. Each wrong path adds latency.
Instead, Tool Filtering with Redis flattens this approach exposing all tools, not siloed into independent systems.
Redis for Tool Filtering
Tool Filtering turns tool selection into a retrieval problem. Redis is the world’s fastest data retrieval platform.
It's fast. The same in-memory architecture that serves millions of cache hits per second powers vector search at the same scale. Tool lookups feel instant.
It's smart. Pure vector search isn't always enough. A query for "customer errors" needs tools that match the user's permissions, environment, and tenant. Redis handles vector similarity and metadata filtering in a single query with hybrid search.
It's already in your stack. The same Redis running your cache and sessions can run Tool Filtering. One system to manage. No new infrastructure to learn.
It's easy to start. The RedisVL library handles indexing and search. With Redis Cloud, you're operational in minutes.
Conclusion
As tool catalogs grow, loading everything upfront stops working. Token costs rise, accuracy drops, and latency compounds.
Tool Filtering solves this by retrieving only what's relevant. Redis is a natural fit: it's fast enough to make retrieval feel instant, hybrid search lets you filter by permissions and environment in a single query, and easy to get started today. No new infrastructure to learn or manage.
In our tests: tokens dropped from 23,000 to 450tokens per request, response times fell from 3.4 seconds to under 400ms, and accuracy jumped from 42% to 85%.
Intelligent filtering isn't optional. It's how agents scale.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.