
Semantic caching is a powerful idea, but most of the tools we’ve been using for it were never really built for the job.
Until now, we’ve mostly relied on generic “RAG” embedding models – the kind used to help chatbots search through large document collections. They’re great when you’re trying to find the right paragraph in a huge knowledge base.
But caching is a very different problem.
With caching, you’re not trying to search through millions of documents. You’re trying to answer a much simpler but stricter question:
“Is this new question’s answer the same as the answer of a previously seen question?”
That might sound easy, but it isn’t. Two questions can look almost identical and mean very different things. Or they can be worded completely differently and still mean exactly the same thing. Most standard models are not tuned to handle that subtlety.
Today, we’re changing that.
We’re introducing langcache-embed-v3-small: a compact, highly specialized embedding model built specifically for low latency semantic caching.
It’s smaller. It’s faster. And it’s much better at understanding what people actually mean when they ask a question.
Why regular models fall short for caching
Most off-the-shelf embedding models are designed for a classic RAG search scenario:
- You have a short, messy user query
- You have a long, detailed document
- The model tries to match the query to the right part of the document
That’s perfect for “find me a needle in a haystack” tasks.
Caching is not that. In semantic caching we’re comparing question to question, not question to document.
We need to know when two questions are truly equivalent, not just similar on the surface. Generic models often confuse:
- Questions that sound alike but ask for different things
- Questions that sound different but are really asking the same thing
For instance:
- "How do I reset my password?" vs. "How can I change my password?" — These are essentially the same question, just worded differently.
- "How do I reset my password?" vs. "How do I recover my account if I forgot my password?" — These sound similar but may require different actions: one is about changing a known password, the other about account recovery when the password is forgotten.
langcache-embed-v3-small is designed to fix that. It’s trained specifically to understand when two short pieces of text carry the same intent.
From prototype to production: How v3 Is different
Our earlier model, langcache-embed-v1, was a useful first step. It proved that specialized caching models are worth pursuing, but it had limits:
- It was based on a heavier, general-purpose architecture
- It was trained on a relatively small dataset
- It often struggled to beat open source baselines such as gte-modernbert-base
For v3, we rebuilt almost everything: the data, the training setup, and the underlying model.
1. A massive upgrade in training data
Specialized behavior needs specialized data.
- v1 learned from around 323,000 question pairs
- v3 is trained on over 8 million labeled pairs (sentencepairs-v2)
This new training set pulls from large paraphrase collections. These examples teach the model all the subtle ways two questions can:
- Look different but mean the same thing
- Look similar but actually ask something different
In other words, we trained it to pay attention to meaning, not just wording.
2. Smarter training, not just more training
We didn’t just feed the model more data; we changed how it learns from it.
Instead of only showing it one “matching” pair at a time, we trained it to make fine-grained distinctions across many examples at once. Each training step forces the model to:
- Pull truly equivalent questions closer together
- Push unrelated or misleadingly similar questions apart
To support this, we dramatically increased the number of examples the model sees at once during training, giving it enough context to learn these nuances reliably.
The result: the model becomes much more confident and accurate about what actually “belongs together” in its internal space.
Why “small” is an advantage
In caching, accuracy at speed is everything.
To efficiently handle a high volume of queries, it’s essential to minimize inference time, memory footprint, and storage requirements. Optimizing these factors not only accelerates response times where every millisecond matters, especially with semantic cache look-ups ahead of costly downstream systems but also reduces database and compute expenses. By streamlining your model and infrastructure, you achieve faster performance and significant cost savings on both storage and compute resources.
So we built langcache-embed-v3-small to be:
- Lightweight—It’s based on an efficient architecture with only about 20 million parameters, instead of the ~149 million in v1.
- Right-sized for queries—We trimmed the maximum text length it handles to 128 tokens, which is more than enough for typical user questions, but much cheaper to run than a huge context window designed for full documents.
This makes v3-small:
- Faster to run
- Cheaper to scale
- Easier to deploy in latency-sensitive systems
“Small” here doesn’t mean weak. It means purpose-built.
How it performs
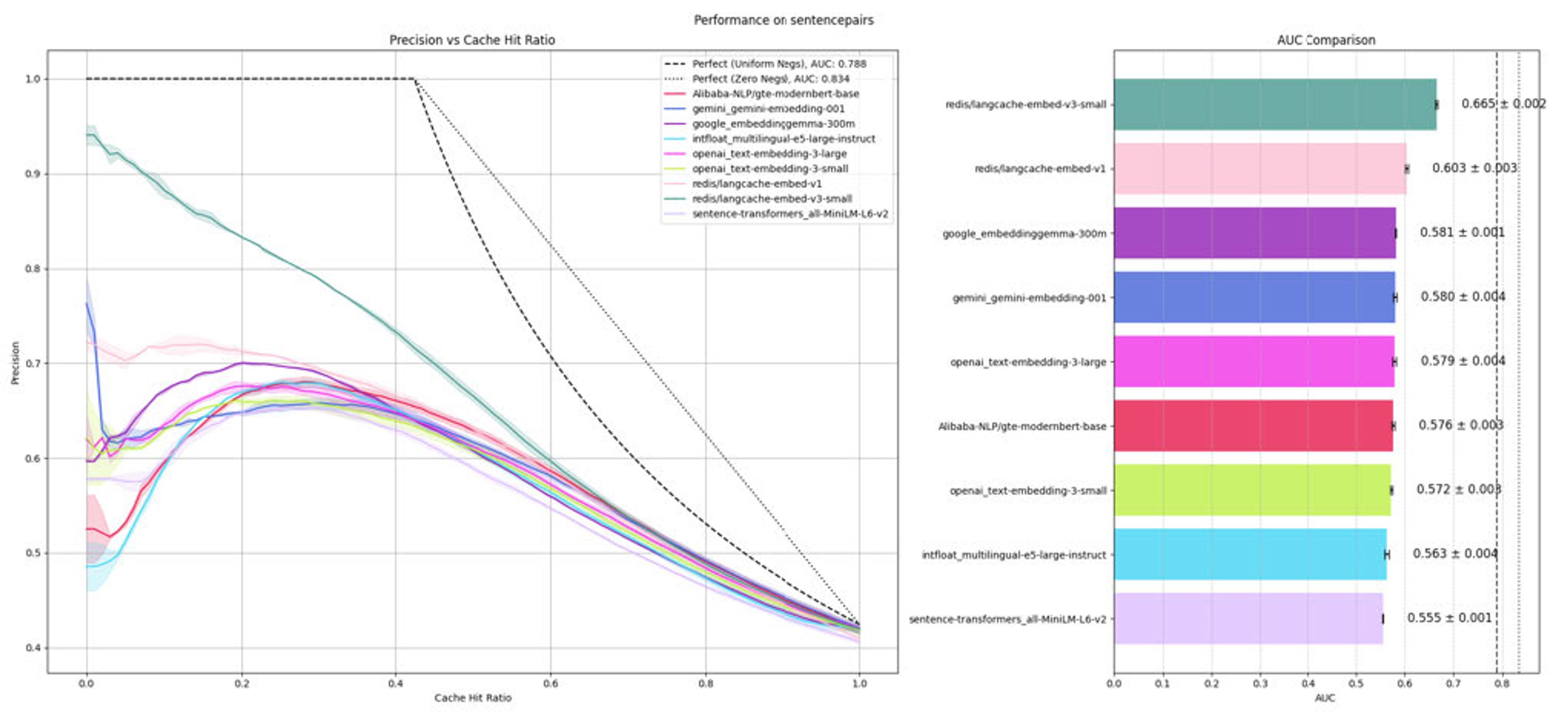
In internal tests focused on ranking and comparison quality, langcache-embed-v3-small is consistently better at:
- Grouping together queries that truly mean the same thing
- Separating out queries that look alike but are actually different
In practice, that means:
- Fewer cache misses when the answer is already known
- Fewer incorrect cache hits where a “similar-looking” but wrong answer is reused.
What’s next?
langcache-embed-v3-small is now ready for real-world trials.
It’s a key step in our shift from generic, one-size-fits-all models to specialized models, tuned for specific tasks like semantic caching.
If you’re building systems where:
- You answer a lot of similar questions repeatedly
- Latency and cost really matter
- You care about correctness
then v3-small is designed for you.
This is our new foundation for semantic caching—and just the beginning of what specialized models can do in this space.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.