
This post is part five of a series of posts examining the features of the Redis-ML module. The first post in the series can be found here. The sample code included in this post requires several Python libraries and a Redis instance with the Redis-ML module loaded. Detailed setup instructions for the runtime environment are provided in both part one and part two of the series.
Decision Trees
Decision trees are a predictive model used for classification and regression problems in machine learning. Decision trees model a sequence of rules as a binary tree. The interior nodes of the tree represent a split or a rule and the leaves represent a classification or value.
Each rule in the tree operates on a single feature of the data set. If the condition of the rule is met, move to the left child; otherwise move to the right. For a categorical feature (enumerations), the test the rule uses is membership in a particular category.
For features with continuous values the test is “less than” or “equal to.” To evaluate a data point, start at the root note and traverse the tree by evaluating the rules in the interior node, until a leaf node is reached. The leaf node is labeled with the decision to return. An example decision tree is shown below:
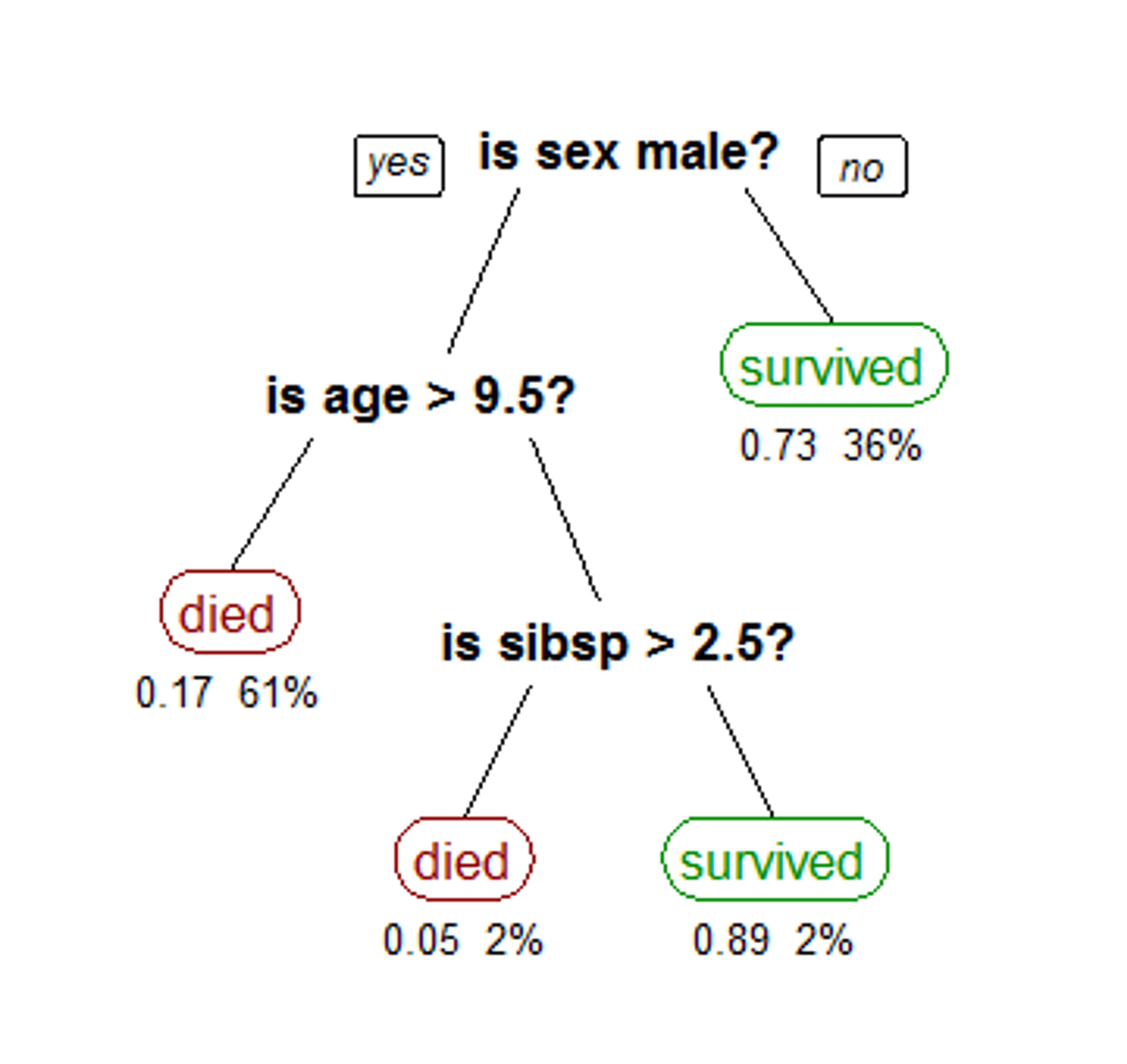
CART Tree from Wikipedia Decision Tree Learning Article
Many different algorithms (recursive partitioning, top-down induction, etc.) can be used to build a decision tree, but the evaluation procedure is always the same. To improve the accuracy of decision trees, they are often aggregated into random forests which use multiple trees to classify a datapoint and take the majority decision across the trees as a final classification.
To demonstrate how decision trees work and how a decision tree can be represented in Redis, we will build a Titanic survival predictor using the scikit-learn Python package and Redis.
Titanic Dataset
On April 15, 1912, the Titanic sank in the North Atlantic Ocean after colliding with an iceberg. More than 1500 passengers died as a result of the collision, making it one of the most deadly commercial maritime disasters in modern history. While there was some element of luck in surviving the disaster, looking at the data shows biases that made some groups of passengers more likely to survive than others.
The Titanic Dataset, a copy of which is available here, is a classic dataset used in machine learning. The copy of the dataset, from the Vanderbilt archives, which we used for this post contains records for 1309 of the passengers on the Titanic. The records consist of 14 different fields: passenger class, survived, name, sex, age, number of siblings/spouses, number of parents/children aboard, ticket number, fare, cabin, port of embarkation, life boat, body number and destination.
A cursory scan of our data in Excel shows lots of missing data in our dataset. The missing fields will impact our results, so we need to do some cleanup on our data before building our decision tree. We will use the pandas library to preprocess our data. You can install the pandas library using pip, the Python package manager:
or your prefered package manager.
Using pandas, we can get a quick breakdown of the count of values for each of the record classes in our data:
Since the cabin, boat, body and home.dest records have a large number of missing records, we are simply going to drop them from our dataset. We’re also going to drop the ticket field, since it has little predictive value. For our predictor, we end up building a feature set with the passenger class (pclass), survival status (survived), sex, age, number of siblings/spouses (sibsp), number of parents/children aboard (parch), fare and port of embarkation (“embarked”) records. Even after removing the sparsely populated columns, there are still several rows missing data, so for simplicity, we will remove those passenger records from our dataset.
The initial stage of cleaning the data is done using the following code:
The final preprocessing we need to perform on our data is to encode categorical data using integer constants. The pclass and survived columns are already encoded as integer constants, but the sex column records the string values male or female and the embarked column uses letter codes to represent each port. The scikit package provides utilities in the preprocessing subpackage to perform the data encoding.
The second stage of cleaning the data, transforming non-integer encoded categorical features, is accomplished with the following code:
Now that we have cleaned our data, we can compute the mean value for several of our feature columns grouped by passenger class (pclass) and sex.
Notice the significant differences in the survival rate between men and women based on passenger class. Our algorithm for building a decision tree will discover these statistical differences and use them to choose features to split on.
Building a Decision Tree
We will use scikit-learn to build a decision tree classifier over our data. We start by splitting our cleaned data into a training and a test set. Using the following code, we split out the label column of our data (survived) from the feature set and reserve the last 20 records of our data for a test set.
Once we have our training and test sets, we can create a decision tree with a maximum depth of 10.
Our depth-10 decision tree is difficult to visualize in a blog post, so to visualize the structure of the decision tree, we created a second tree and limited the tree’s depth to 3. The image below shows the structure of the decision tree, learned by the classifier:
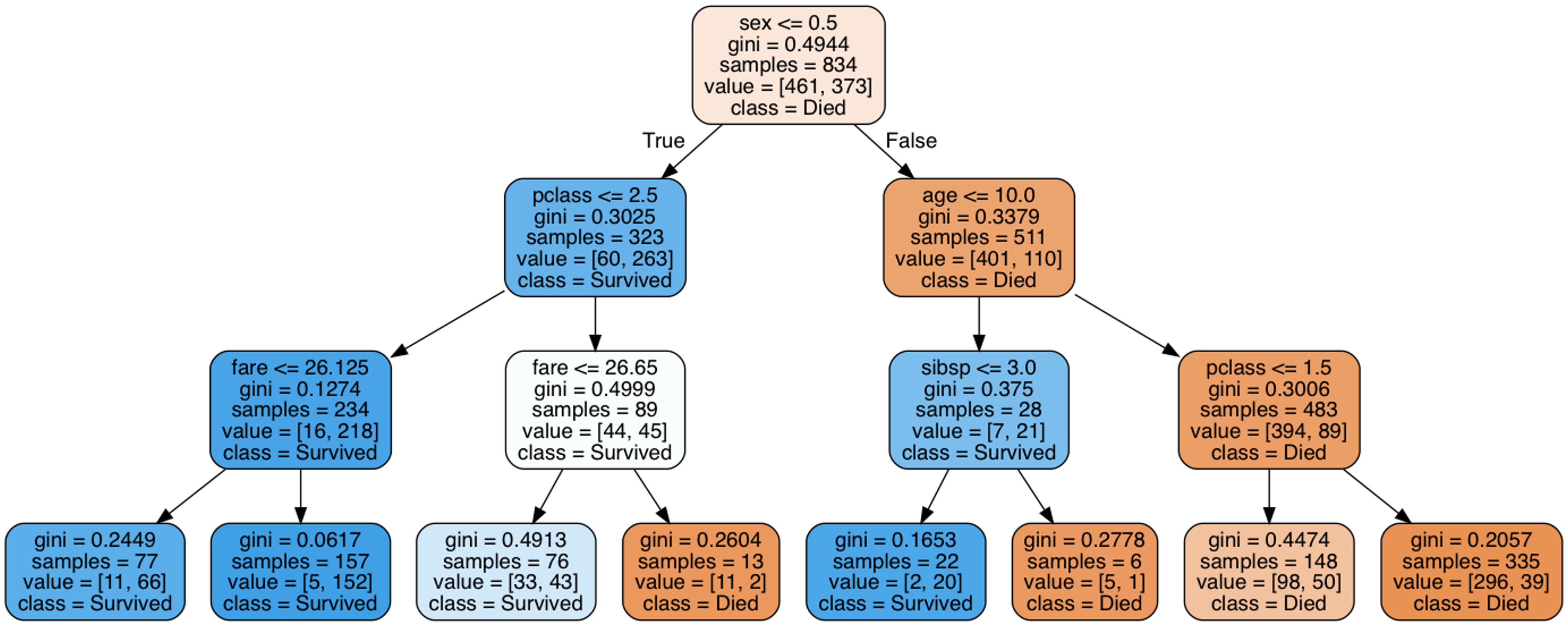
Titanic Decision Tree learned by Scikit
Loading the Redis Predictor
The Redis-ML module provides two commands for working with random forests: ML.FOREST.ADD to create a decision tree within the context of a forest and ML.FOREST.RUN to evaluate a data point using a random forest. The ML.FOREST commands have the following syntax:
Each decision tree in Redis-ML must be loaded using a single ML.FOREST.ADD command. The ML.FOREST.ADD command consists of a Redis key, followed by an integer tree id, followed by node specifications. Node specifications consist of a path, a sequence of . (root), l and r, representing the path to the node in a tree. Interior nodes are splitter or rule nodes and use either the NUMERIC or CATEGORIC keyword to specify the rule type, the attribute to test against and the value of threshold to split. For NUMERIC nodes, the attribute is tested against the threshold and if it is less than or equal to it, the left path is taken; otherwise the right path is taken. For CATEGORIC nodes, the test is equality. Equal values take the left path and unequal values take the right path.
The decision tree algorithm in scikit-learn treats categoric attributes as numeric, so when we represent the tree in Redis, we will only use NUMERIC node types. To load the scikit tree into Redis, we will need to implement a routine that traverses the tree. The following code performs a pre-order traversal of the scikit decision tree to generate a ML.FOREST.ADD command (since we only have a single tree, we generate a simple forest with only a single tree).
Comparing Results
With the decision tree loaded into Redis, we can create two vectors to compare the predictions of Redis with the predictions from scikit-learn:
To use the ML.FOREST.RUN command, we have to generate a feature vector consisting of a list of comma separated <feature>:<value> pairs. The <feature> portion of the vector is a string feature name that must correspond to the feature names used in the ML.FOREST.ADD command.
Comparing the r_pred and s_pred prediction values against the actual label values:
Redis’ predictions are identical to those of the scikit-learn package, including the misclassification of test items 0 and 14.
An passenger’s chance of survival was strongly correlated to class and gender, so there are several surprising cases of individuals with a high probability of survival who actually perished. Investigating some of these outliers leads to fascinating stories from that fateful voyage. There are many online resources that tell the stories of the Titanic passengers and crew, showing us the people behind the data. I’d encourage you to investigate some of the misclassified people and learn their stories.
In the next and final post we’ll tie everything together and wrap up this introduction to Redis-ML. In the meantime, if you have any questions about this or previous posts, please connect with me (@tague) on Twitter.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.