
If you're running LLMs in production, you already know the bill adds up fast. In talking with one of our enterprise RAG customers, they shared that they spend over $80k per quarter on their OpenAI bill for text generation alone (on input and output tokens). They estimate that somewhere around 30-40% of their calls are similar to previously asked questions.
Vector databases became the default solution for RAG systems because they power semantic search between user questions and document chunks. But retrieval is only one piece of the puzzle. Production AI systems also need session management, semantic caching, security, and increasingly, agent memory—none of which pure vector databases provide.
This article covers the infrastructure that actually reduces LLM costs: semantic caching, session management, and the patterns production AI systems need beyond vector search.
Information retrieval is not new
Long before the hype around LLMs and vector search, the information retrieval (IR) community spent decades making sense of vast amounts of text and unstructured data. Algorithms like TF-IDF and BM25 still power world-class search engines. These methods generate scores based on how often words appear in a document and how rare they are across the entire corpus, highlighting terms that best characterize a document.
Though the spotlight shifted to vectors, vector database offerings are scrambling to catch up with lexical search—like it's 1990 all over again.
Why? The most effective retrieval solutions don't choose one over the other. Instead, they often implement some form of hybrid search that combines signals from both vector and lexical search. Vectors might be the hot topic today, but they're building on decades of innovation—standing on the shoulders of giants.
Hybrid search is also about efficiency. Combining vector and lexical signals improves retrieval precision, which means fewer irrelevant results passed to the LLM and fewer follow-up calls to get the right answer.
How vector search works
Vectors aren't magic. They're numerical fingerprints of data—lists of numbers that represent meaning in high-dimensional space. The math behind vector search (dot product, cosine similarity, euclidean distance) has been well understood for decades. Advanced indexing techniques like HNSW and Microsoft's DiskANN are now standard across vector databases.
Top tech companies like Google, Amazon, and Meta have used embeddings for recommendations and personalization for years. Redis has been the data layer behind many of those systems: recommendation engines at Netflix, real-time fraud detection for major credit card providers, and personalization pipelines across financial services and e-commerce.
When vector search became a category, Redis added native vector indexing to infrastructure that was already handling these workloads. And the barrier to entry has dropped for everyone: you can generate quality embeddings on-demand with APIs from HuggingFace, Cohere, and OpenAI instead of training models from scratch.
With over 40 vector database options available, the retrieval layer has become standardized. Most teams can get vector search running in days. The operational challenges—scaling, reliability, cost management—take longer to solve.
What vector databases don't handle
In practice, the hardest parts of bringing a RAG system to production aren't related to vector math at all. Complexity arises from managing real-time updates, dynamic re-indexing, large data volumes, fluctuating query loads, disaster prevention and recovery. These are the operational challenges that determine whether your platform can deliver consistent performance at scale. Redis, for instance, has long offered multi-tenancy, high availability, active-active replication, and durability—capabilities that pure vector database vendors are now scrambling to implement.
As Chip Huyen (famous ML researcher and founder) notes, the ambiguity of LLM responses, the need for prompt versioning and evaluation, and the careful consideration of cost and latency all illustrate that success comes from mastering more than just retrieval. While I won't detail an entire LLMOps framework here, let's highlight a few key considerations that underscore why you need more than a vector database.
Managing access: security and governance
The very first hurdle you will likely encounter is protecting your most valuable assets: your proprietary data and your customers' sensitive information. Unfortunately, it's all too easy to pass the wrong pieces of information over the web to a third party model. This introduces new requirements in the development lifecycle.
Financial service companies that we work with heavily invest in model risk management (MRM) processes to mitigate potential for harm. Other companies introduce strict document governance to ensure users only gain access to docs according to their roles.
While necessary, these processes introduce added complexity and slowdowns in delivery timelines.
Managing state: session management
LLMs don't retain memory between inference calls. Secondly, any distributed app needs a "session." So, if you're building a conversational app or a multi-step LLM workflow, you will need a data layer to store and retrieve session context and chat history in real time. Relying on in-process app memory is wrought with peril as soon as you scale beyond a single user.
Patterns for production AI
As apps grow in complexity, you'll likely need additional patterns to manage cost, latency, and reliability.
- AI gateways centrally manage access to LLMs and enforce rate limits across teams. Gateways like Kong or LiteLLM control the flow of requests to different models—essential when multiple teams are hitting the same APIs. This pattern shows up heavily in financial institutions where governance and cost allocation matter.
- Semantic routing routes queries based on meaning, not keywords. Product support questions go to one pipeline, HR questions to another. You can also use this for model cascading: send simple queries to cheaper models and reserve expensive reasoning models for complex tasks.
- Embedding caching avoids re-embedding the same chunk data repeatedly. If your document corpus is stable, there's no reason to pay for the same embedding twice.
- Agent checkpointing and memory saves intermediate states so agents can resume without replaying entire reasoning chains.
- Message streaming orchestrates multi-step LLM pipelines and handles real-time updates. Redis Streams lets you build event-driven architectures where each step can process, checkpoint, and hand off to the next—without losing state if something fails.
Below is an example architecture based on Redis that includes many of these components in an end-to-end flow.
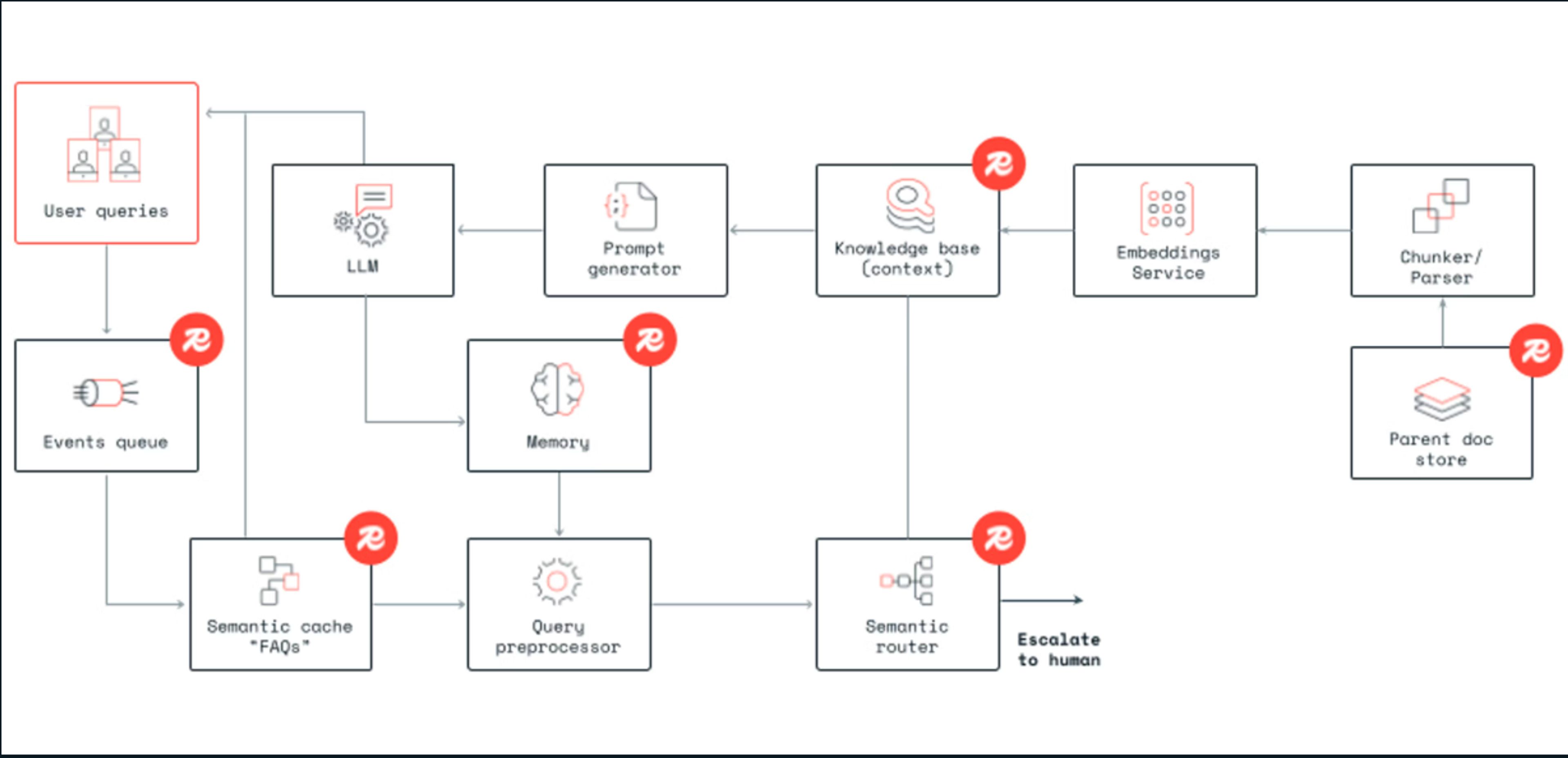
Dell AI Factory built a reference architecture using Redis that demonstrates a similar end-to-end flow.
Controlling cost with caching
Third-party LLMs are expensive. Enterprise RAG customers report that 30-40% of their LLM calls are semantically similar to previous queries, which aligns with academic research on the topic. That means you're paying for the same answer multiple times.
Traditional caching doesn't help here. "What's your return policy?" and "How do I return something?" are different strings but identical intent. Exact-match cache keys miss these duplicates entirely.
How semantic caching works
Semantic caching solves this by embedding queries into vector space and returning cached results when similarity exceeds a threshold. Instead of matching strings, it matches meaning. When a user asks a question that's semantically equivalent to one you've already answered, you serve the cached response instead of making another LLM call.
Tuning your similarity threshold
The threshold matters. Set it too low and you return wrong answers; set it too high and you miss valid cache hits. Production systems commonly tune between 0.85-0.95, with precision-critical workloads using 0.92 or higher. Getting it right requires testing, because certain query types need special handling:
- Contextually different queries that look semantically similar (e.g., "What's my balance?" from two different users)
- Time-sensitive queries that need fresh responses (e.g., "What's the current price?")
- Conversational queries where meaning depends on chat history
Without proper tuning, these can return incorrect cached responses.
What kind of savings to expect
The results can be significant. Teams report 30-50% LLM cost reductions in high-repetition workloads, though results vary by query distribution. Applications with diverse, unique queries see lower cache hit rates; applications with repeated question patterns see higher savings. Redis LangCache is a fully managed semantic caching service that handles embedding generation and similarity matching, so you can reduce LLM spend without building the infrastructure yourself.
Build with Redis
Vector search is one piece of the puzzle. Production AI systems need the rest: semantic caching, session management, agent memory, and real-time coordination.
Redis handles all of it in one platform. Redis LangCache cuts LLM costs through semantic caching. Redis vector search delivers sub-millisecond retrieval for RAG. Redis Streams orchestrates multi-step agent workflows. And it all runs on infrastructure that's powered mission-critical apps at enterprise scale for over a decade.
Ready to build? Explore Redis for AI to see how it fits together, or check out the docs to get started.
FAQ about vector databases
What is semantic caching for LLMs?
Semantic caching stores LLM responses keyed by query meaning rather than exact text. When a user asks "Can I get a refund?" and someone else asks "I want my money back," traditional caches treat these as separate queries and make two LLM calls. Semantic caching embeds both into vector space, recognizes they're asking the same thing, and returns the cached response for the second query.
How do I reduce LLM API costs?
The most effective techniques are semantic caching, model routing, and session management. Semantic caching eliminates redundant calls for similar queries: teams typically see 30-50% cost reductions. Model routing sends simple queries to cheaper models and reserves expensive ones for complex reasoning tasks, delivering 35-85% cost savings depending on workload complexity. Session management avoids replaying full conversation history on every call, reducing token usage by 60-80%. Combining these approaches yields the biggest savings.
Is a vector database enough for production AI?
For prototypes, often yes. For production, no. Vector databases handle retrieval, but production AI systems also need session management to maintain conversation state, semantic caching to reduce redundant LLM calls, security and governance to control data access, and increasingly, agent memory to support multi-step workflows. Pure vector databases don't provide these capabilities, which is why teams end up stitching together multiple tools, or choosing a unified platform that handles all of it.
What's the difference between a vector database and Redis?
A vector database specializes in storing and querying embeddings. Redis is a real-time data platform that includes vector search alongside caching, session management, pub/sub messaging, and streams. For AI workloads, this means you can handle RAG retrieval, semantic caching, agent state, and real-time coordination in one system instead of integrating separate tools for each capability.
How does semantic caching differ from traditional caching?
Traditional caching requires exact string matches—if the cache key doesn't match character-for-character, it's a miss. Semantic caching compares query embeddings in vector space, so "How do I reset my password?" and "I forgot my login" can return the same cached response. This catches the duplicate queries that traditional caching misses entirely.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.