Blog
Redis 8.4, the fastest, simplest, and most powerful Redis yet–now GA in Redis Open Source


Redis 8.4 continues our mission to make Redis faster, simpler, and more powerful, with major upgrades to performance and the dev experience, as well as new hybrid search capabilities that make building AI apps faster and easier.
Redis 8.4 introduces hybrid search—combining full-text and vector search—for more flexible and intelligent querying, while bringing substantial performance and memory utilization improvements. It also makes Redis easier and more reliable to operate at scale through updates to Redis streams logic and a series of new atomic operations that simplify building with Redis.
Introducing hybrid search
Every intelligent agent, from retrieval-augmented generation (RAG) systems to autonomous assistants, depends on the quality of its context. The real challenge isn’t finding data, but understanding it by distinguishing between what’s relevant now, what’s stored in its memory, and what provides the reasoning backbone for a decision. Agents need to search their “memories” semantically, not just recall them literally, and combine symbolic reasoning with semantic similarity. Redis has always been at the center of real-time decisioning and contextual retrieval, with devs already using its hybrid policy to pre-filter candidates and narrow the search space for vectors at blazing speed.
However, previous methods for merging full-text and vector similarity were complex, required multiple steps, and traded precision for performance. This ultimately led to increased latency and a fragmented retrieval experience.
Redis 8.4 addresses these challenges with the new FT.HYBRID command, a unified in-engine hybrid retrieval API. This command merges full-text and vector similarity results through score fusion (using Reciprocal Rank Fusion or Linear Combination) to deliver a single ranked list that captures both meaning and match, all within one query execution. This means no trade-off between precision and performance, and no external score merging. FT.HYBRID allows you to express contextual intent directly in the query, easily prioritizing recent memories, regionalizing context with GEO and GEOSHAPE, and mixing semantic, fuzzy, and exact matches, providing a consistent, fast, and semantically aware retrieval pipeline ready for the next generation of intelligent agents.
The fastest, most resource-efficient Redis yet
With Redis 8.4, we continue to deliver on our commitment to continuous performance improvement. The chart below shows the steady increase in Redis throughput (operations per second) for a typical caching workload across successive releases of Redis.
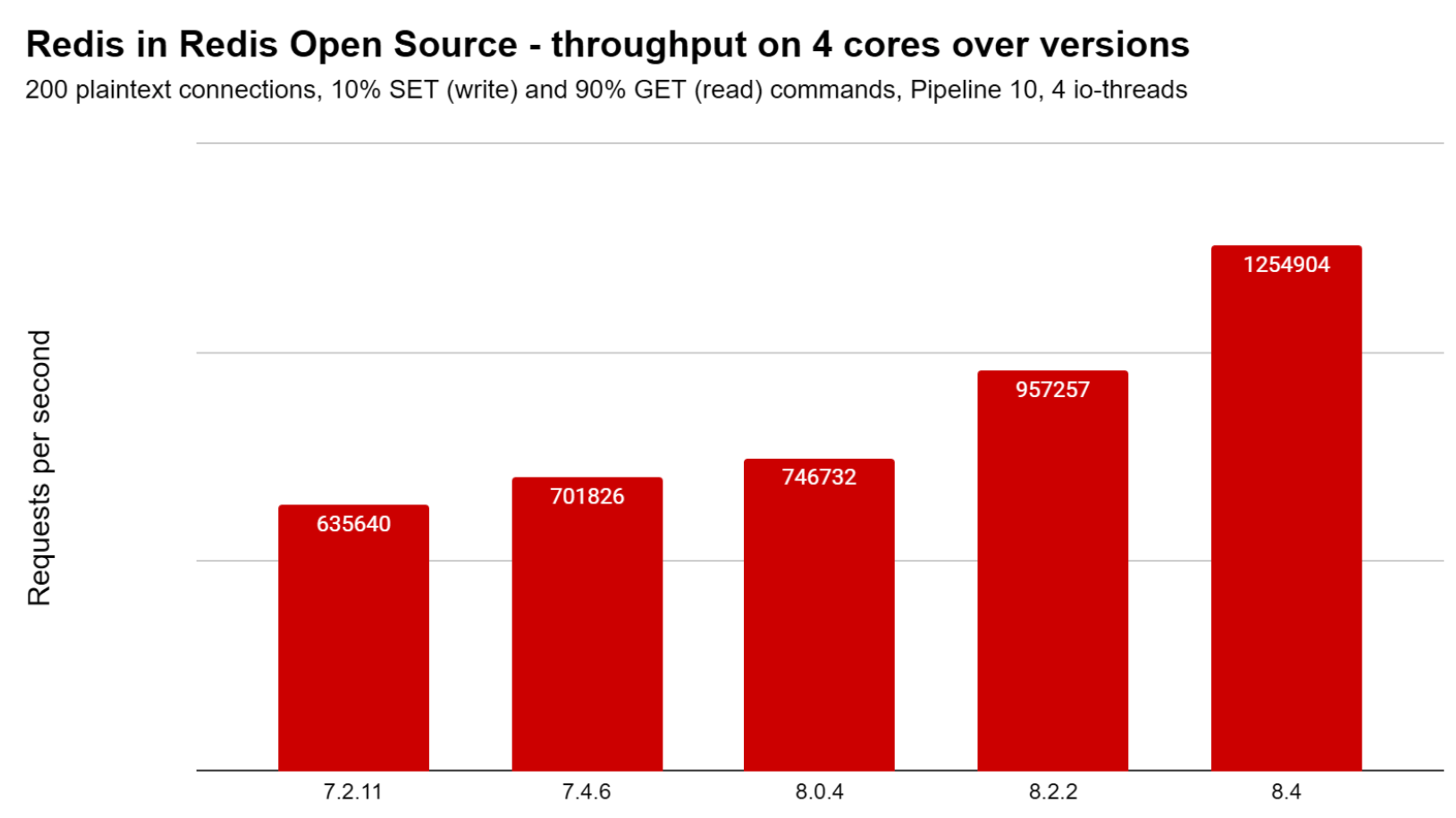
10% writes and 90% reads with 1 KB string values.
8.4 continues on this trend, offering an over 30% throughput increase for caching use cases (90% `GET`, 10% `SET`) compared to Redis 8.2.
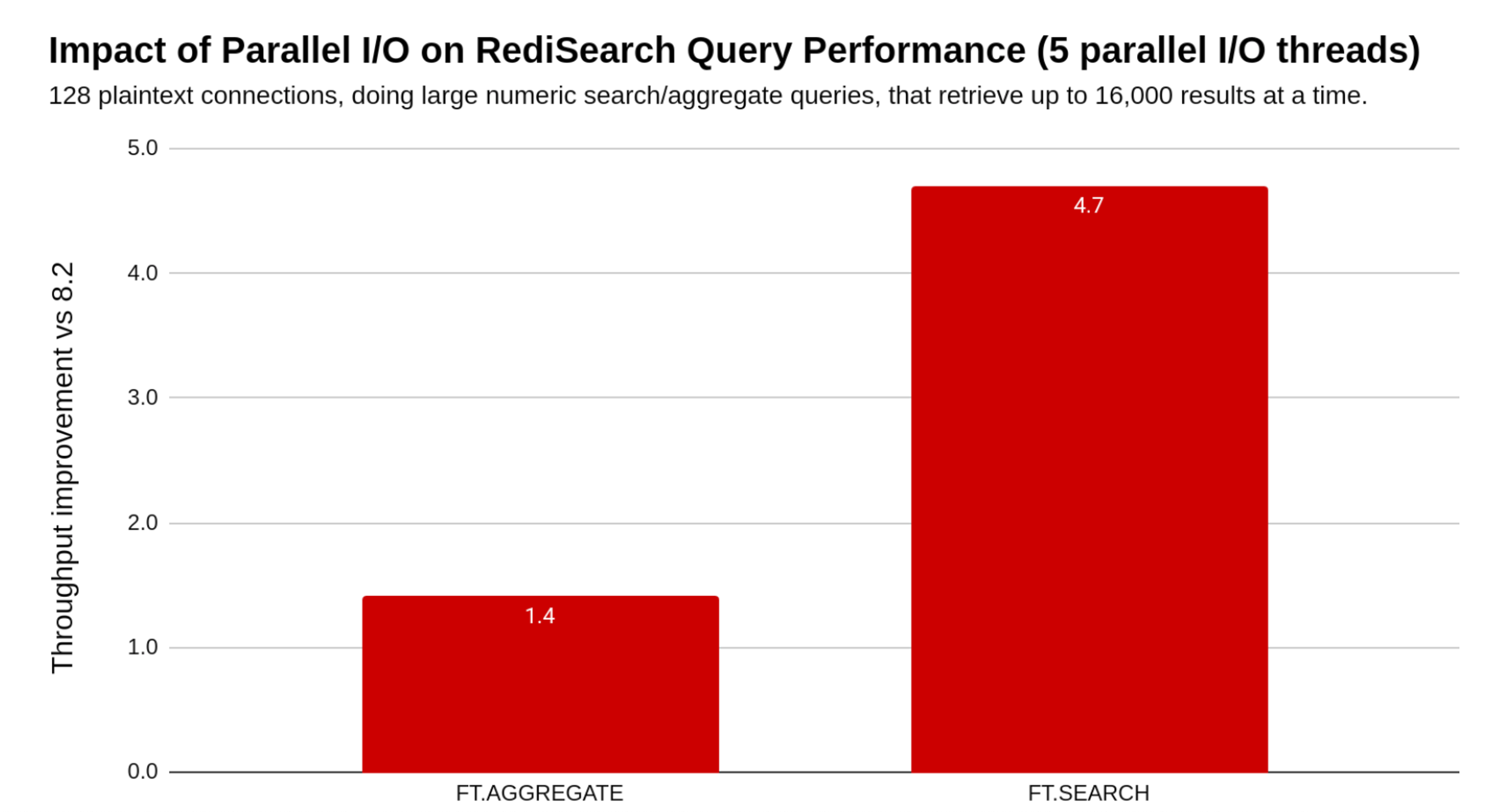
With the introduction of multi-threaded I/O handling for distributed queries, the Redis Query Engine achieves significant performance gains under high-load. In scenarios where large result sets are retrieved from multiple shards, concurrent I/O threads now process shard responses in parallel rather than sequentially. This eliminates the previous single-thread bottleneck that could saturate CPU usage and limit throughput, creating a long-waiting queue in large clusters. As a result, the system can fully utilize available compute resources across shards, reducing contention and enabling smoother query fan-out and result aggregation.
Benchmarking shows that these changes deliver substantial end-to-end improvements for both FT.SEARCH and FT.AGGREGATE operations, and of course the newly FT.HYBRID benefits from this as well. For large-scale search workloads, parallel I/O processing yields up to a 4.7x increase in throughput and lowers query latency at the same rate. Aggregate operations, which involve additional post-processing, also benefit, achieving around a 1.4× throughput improvement while reducing response times under concurrent load. In both cases, multi-threaded I/O unlocks more headroom for worker threads to perform the actual search or aggregation logic, ensuring a more balanced utilization of cluster resources and faster responses across search and vector workloads
We've also enhanced memory allocation management for query execution, making the Redis Query Engine more robust. Devs can now choose the expected behavior in out-of-memory (OOM) events. A new configuration search-on-oom can now be defined, allowing full manageability for the memory consumed and how the engine should behave.
We also continue to invest in reducing the memory consumption of the JSON data type. In Redis 8.2, we introduced a substantial reduction by inlining numeric values. In Redis 8.4, we also inline short strings (up to 7 bytes). For example, a JSON array with 500 key-value elements, where all keys and values are short strings, would now require 37% less memory:
| Map key and values | Redis 8.2 memory | Redis 8.4 memory | Benefit |
|---|---|---|---|
| Short string (up to 7 bytes) | 64,512 bytes | 40,624 bytes | 37% less memory |
But more importantly, we now store homogeneous JSON numeric arrays much more efficiently. Previous to 8.4, for each element in a JSON array, we stored the element’s type and the element’s value. Now, when the array is homogeneous (or in other words—when all the array elements are of the same data type), we store the elements data type just once for the whole array. For an array of numeric values, Redis now automatically determines the most efficient element type (I8, U8, I16, U16, I32, U32, I64, I64, BF16, FP16, FP32, or FP64) that ensures that all the values are within range and can be stored with no loss of accuracy. For example, a JSON array with 1 million numeric values would now require between 50% to 92% less memory:
| Array elements | Redis 8.2 memory | Redis 8.4 memory | Benefit |
|---|---|---|---|
| signed integers [-2^7 .. 2^7) or unsigned integers [0 .. 2^8) | 8.42 MB | 1.14 MB | 87% less memory |
| signed integers [-2^15 .. 2^15) or unsigned integers [0 .. 2^16) | 8.43 MB | 2.19 MB | 74% less memory |
| signed integers [-2^31 .. 2^31) or unsigned integers [0 .. 2^32) | 8.46 MB | 4.26 MB | 50% less memory |
| signed integers [-2^63 .. 2^63) or unsigned integers [0 .. 2^64) | 24.46 MB | 8.43 MB | 66% less memory |
| BF16-representable FP values | 24.43 MB | 2.16 MB | 92% less memory |
| FP16-representable FP values | 24.43 MB | 2.19 MB | 92% less memory |
| FP32-representable FP values | 24.46 MB | 4.26 MB | 83% less memory |
| FP64-representable FP values | 24.46 MB | 8.43 MB | 66% less memory |
Simplified streams processing consumes both idle pending and incoming messages in one command
In Redis streams, pending messages refer to messages that have been delivered to a consumer in a consumer group but not yet acknowledged. Pending messages are kept until they are acknowledged or deleted. When a message is pending for a long time, it usually means something went wrong. Either the client that consumed this message crashed (while handling the message or before acknowledging it) or because this message is “problematic” - e.g., causing a deadlock or taking a very long time to handle. It can also be because of communications problems between the consuming client and Redis.
Under a normal flow, apps expect each message to be acknowledged within a given time since it was consumed. If not acknowledged, we call it an idle pending message, and can try to deliver it again.
Since stream message processing can go wrong, a simple and robust recovery logic is required. That’s why consumers need to both (1) monitor the pending messages list and claim idle pending messages and handle them, and (2) handle new incoming entries.
Before Redis 8.4, clients had to implement a complex logic to consume both idle pending and incoming messages.
With Redis 8.4 we introduce a simple yet powerful extension to the XREADGROUP command, that allows clients to consume both idle pending and incoming messages in a single command.
New atomic compare-and-set and compare-and-delete commands for string keys
Compare-and-set (AKA check-and-set, compare-and-swap) and compare-and-delete are atomic methods which are often used for implementing single-key optimistic concurrency control. With compare-and-set, a client can:
- Fetch a value from the server, and keep it as “old value” on the app side.
- Manipulate the local copy of the value.
- Compare-and-set: Apply the local changes to the server, but only if the server’s value hasn’t changed by another client (i.e., the value on the server is still equal to the old value).
Suppose you have a Product:Description string key, and you want to allow users to edit the description (e.g., via a web form). Because each product description is rarely edited, you may want to use optimistic concurrency control. In simpler terms, you want to set the new value only if it hasn’t changed by another client since it was fetched.
In previous Redis versions, to execute step 3 atomically, you’d have to implement a custom Lua script.
Starting with Redis 8.4, clients can use a single command (SET with the new IFEQ/IFNE/IFDEQ/IFDNE options) to update a string key only if its value hasn’t changed by another client since it was fetched. This is much simpler and faster. Similarly, we introduced a single command, XDELEX, for compare-and-delete: Atomically deleting a string key if its value hasn't changed since it was fetched.
New command to atomically set multiple string keys and update their expiration
Setting multiple keys, and optionally setting a common expiration, is a common use case. Often, it is also required to set the values and expiration only if all the specified keys already exist, or alternatively, only if none of the specified keys exist.
Before Redis 8.4, a custom Lua script was required to support this common use case.
Redis 8.4 introduces a simpler and faster approach. A new single command, MSETEX, can now be used to conditionally set or update the values and the expiration of multiple string keys.
Simpler clustering with Atomic Slot Migration
A Redis Cluster is a distributed setup of Redis designed to achieve high-availability, scalability, and fault tolerance. Instead of running a single Redis instance, Redis Cluster connects multiple Redis nodes together so that data and traffic can be spread across them. Redis Cluster uses 16,384 hash slots to automatically split and distribute data across different nodes. Each node in the cluster holds a subset of the hash slots. This allows Redis to handle much larger datasets than a single machine could.
There are two main scenarios where the mapping between slots and nodes needs to change, and that’s when keys must be migrated between nodes:
- Rebalancing the cluster: After you add a new node, the cluster needs to move some hash slots (and the keys inside them) to the new node so the data is spread more evenly. Similarly, before you remove a node, its slots need to be reassigned to other nodes.
- Handling overloaded nodes: Sometimes, due to key content and access patterns, a specific slot or node can require more resources than others. It could be more memory, more processing power, more operations per second, or more network throughput. When a node is overloaded, you may rebalance its slots across nodes for better performance and resource utilization. This requires migrating slots from overloaded nodes to less loaded ones.
Previously, slots were migrated in a non-atomic way. During a slot migration, keys were moved one by one to the destination node and then deleted from the source node. This led to several potential problems during the migration process:
- Redirects and client complexity: While a slot is being migrated, some of the keys may have already been moved, while others haven’t. If a client is trying to access a key that was already moved, it will get an -ASK reply and it will have to retry fetching the key from the destination node. This increased the complexity and the network latency. It also breaks naive pipelines.
- Multi-key operations become unreliable during resharding: In a multi-key command (e.g., MGET key1, key2), if some of the keys were already moved, the client will get a TRYAGAIN reply. The client can’t complete this command until the whole slot is migrated.
- Failures during slot migration may lead to problematic states: When some of the keys are moved, but Redis fails to remove the additional keys (e.g., due to limited available memory on the destination node), Redis is left in a problematic state that needs to be resolved manually, and often leads to data loss.
- Replication issues: Replicas don’t always know a slot was migrating, so they could reply as if a key was simply deleted instead of issuing an -ASK redirect.
- Performance: Key-by-key migration is slow. In the legacy approach, keys are moved effectively one by one, which is inherently slow because of the extra lookups and network round-trips.
Redis 8.4 introduces Atomic Slot Migration (ASM) to solve all these operation problems. ASM is similar to full sync replication at the slot level. With ASM, the complete slot’s content is replicated to the destination node, plus a live delta (like the replication backlog). Only upon completion of the replication, Redis performs a single atomic handoff of ownership. Clients keep talking to the source during the copy and don’t experience any of the problems described above mid-migration. Thus, drastically increasing the manageability of operating Redis Open Source at scale.
Getting started with Redis 8.4 today
All these enhancements are generally available on Redis 8.4 in Redis Open Source today.
- Get started now by downloading Redis 8.4.
- Have feedback or questions? Join the discussion on our Discord server.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.