
There are several ways to classify and understand data architectures, each with its own pros and cons. They can help you make an informed decision about the best design for your needs. Here, I explain velocity-based data architectures, and where they fit in the grand scheme of things.
The two most popular velocity-based architectures are Lambda and Kappa. Data architectures are also classified based on their operational mode or topology, including data fabric, data hub, and data mesh–but I leave that explanation to a later blog post.
What is data architecture?
Data architecture is an element in enterprise architecture, inheriting its main properties: processes, strategy, change management, and evaluating trade-offs. According to the Open Group Architecture Framework, data architecture is “a description of the structure and interaction of the enterprise’s major types and sources of data, logical data assets, physical data assets, and data management resources.”
Per the Data Management Body of Knowledge, data architecture is the process of “identifying the data needs of the enterprise (regardless of structure) and designing and maintaining the master blueprints to meet those needs.” It uses master blueprints to guide data integration, control data assets, and align data investments with business strategy.
Not every process is a good one. Bad data architecture is tightly coupled, rigid, and overly centralized. It uses the wrong tools for the job, which hampers development and change management.
Velocity-based data architectures
Data velocity refers to how quickly data is generated, how quickly that data moves, and how soon it can be processed into usable insights.
Depending on the velocity of data they process, data architectures often are classified into two categories: Lambda and Kappa.
Lambda data architecture
Lambda data architectures were developed in 2011 by Nathan Marz, the creator of Apache Storm, to solve the challenges of large-scale real-time data processing.
The term Lambda, derived from lambda calculus (λ), describes a function that runs in distributed computing on multiple nodes in parallel. Lambda data architecture provides a scalable, fault-tolerant, and flexible system for processing large amounts of data. It allows access to batch-processing and stream-processing methods in a hybrid way.
The Lambda architecture is ideal when you have a variety of workloads and velocities. Because it can handle large volumes of data and provide low-latency query results, it is suitable for real-time analytics applications such as dashboards and reporting. The architecture is useful for batch processing (cleansing, transforming, data aggregation), for stream processing tasks ( event handling, developing machine learning models, anomaly detection, fraud prevention), and for building centralized repositories (known as “data lakes”) to store structured and unstructured information.
Lambda architecture’s critical distinction is that it uses two separate processing systems to handle different types of data processing workloads. The first is a batch processing system that stores the results in a centralized data store (such as a data warehouse or a data lake). The second system in a Lambda architecture is a stream processing system, which processes data in real-time as it arrives and stores the results in a distributed data store.
Lambda architecture solves the problem of computing arbitrary functions, whereby the system has to evaluate the data processing function for any given input (whether in slow motion or in real-time). Furthermore, it provides fault tolerance by ensuring that the results from either system can be used as input into the other if one fails or becomes unavailable. The efficiency of this architecture becomes evident in high throughput, low latency, and near-real-time applications.
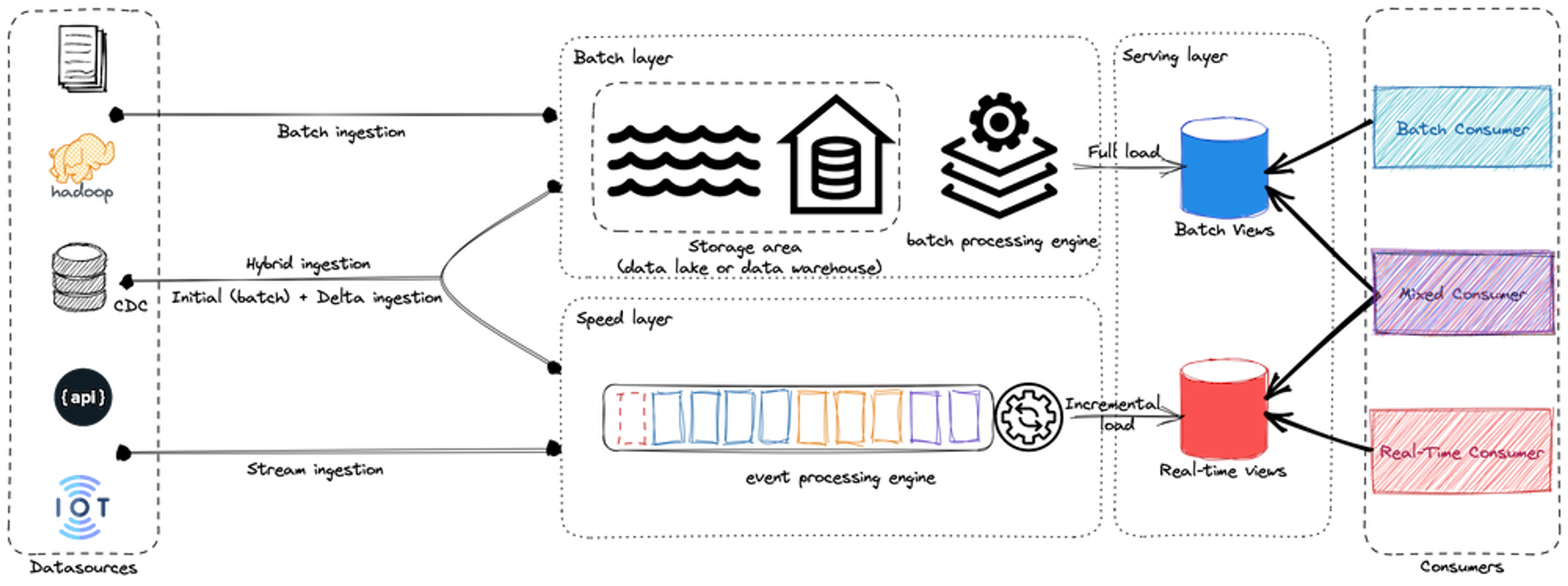
Lambda architecture
Lambda architecture consists of an ingestion layer, a batch layer, a speed layer (or stream layer), and a serving layer.
- Batch layer: The batch processing layer handles large volumes of historical data and stores the results in a centralized data store, such as a data warehouse or distributed file system. This layer uses frameworks like Hadoop or Spark for efficient information processing, allowing it to provide an overall view of all available data.
- Speed layer: The speed layer handles high-velocity data streams and provides up-to-date information views using event processing engines such as Apache Flink or Apache Storm. This layer processes incoming real-time data and stores the results in a distributed data store such as a message queue or a NoSQL database.
- Serving layer: The Lambda architecture serving layer is essential for providing users with consistent and seamless access to data, regardless of the underlying processing system. It plays an important role in enabling real-time applications that need rapid access to current information, such as dashboards and analytics.
Lambda architectures offer many advantages, such as scalability, fault tolerance, and the flexibility to handle a wide range of data processing workloads (batches and streams). But it also has drawbacks:
- Lambda architecture is complex. It uses multiple technology stacks to process and store data.
- It can be challenging to set up and maintain, especially in organizations with limited resources.
- The underlying logic is duplicated in the batch and the speed layers for every stage. This duplication has a cost: data discrepancy as although having the same logic, the implementation is different from one layer to another. Thus, the error/bug probability is higher, and you may encounter different results from batch and speed layers.
Kappa data architecture
In 2014, when he was still working at LinkedIn, Jay Kreps pointed out some Lambda architecture drawbacks. The discussion led the Big Data community to an alternative that uses fewer code resources.
The principal idea behind Kappa (named after the Greek letter ϰ, used in mathematics to represent a loop or cycle) is that a single technology stack can be used for both real-time and batch data processing. The name reflects the architecture’s emphasis on continuous data processing or reprocessing in contrast to a batch-based approach.
At its core, Kappa relies on streaming architecture. Incoming data is first stored in an event streaming log. It then is processed continuously by a stream processing engine ( Kafka, for instance) either in real-time or ingested into another analytics database or business application. Doing so uses various communication paradigms such as real-time, near real-time, batch, micro-batch, and request response.
Kappa architecture is designed to provide a scalable, fault-tolerant, and flexible system for processing large amounts of data in real-time. The Kappa architecture is considered a simpler alternative to the Lambda architecture; it uses a single technology stack to handle both real-time and historical workloads, and it treats everything as streams. The primary motivation for the Kappa architecture was to avoid maintaining two separate code bases (pipelines) for the batch and speed layers. This allows it to provide a more streamlined and simplified data processing pipeline while still providing fast and reliable access to query results.
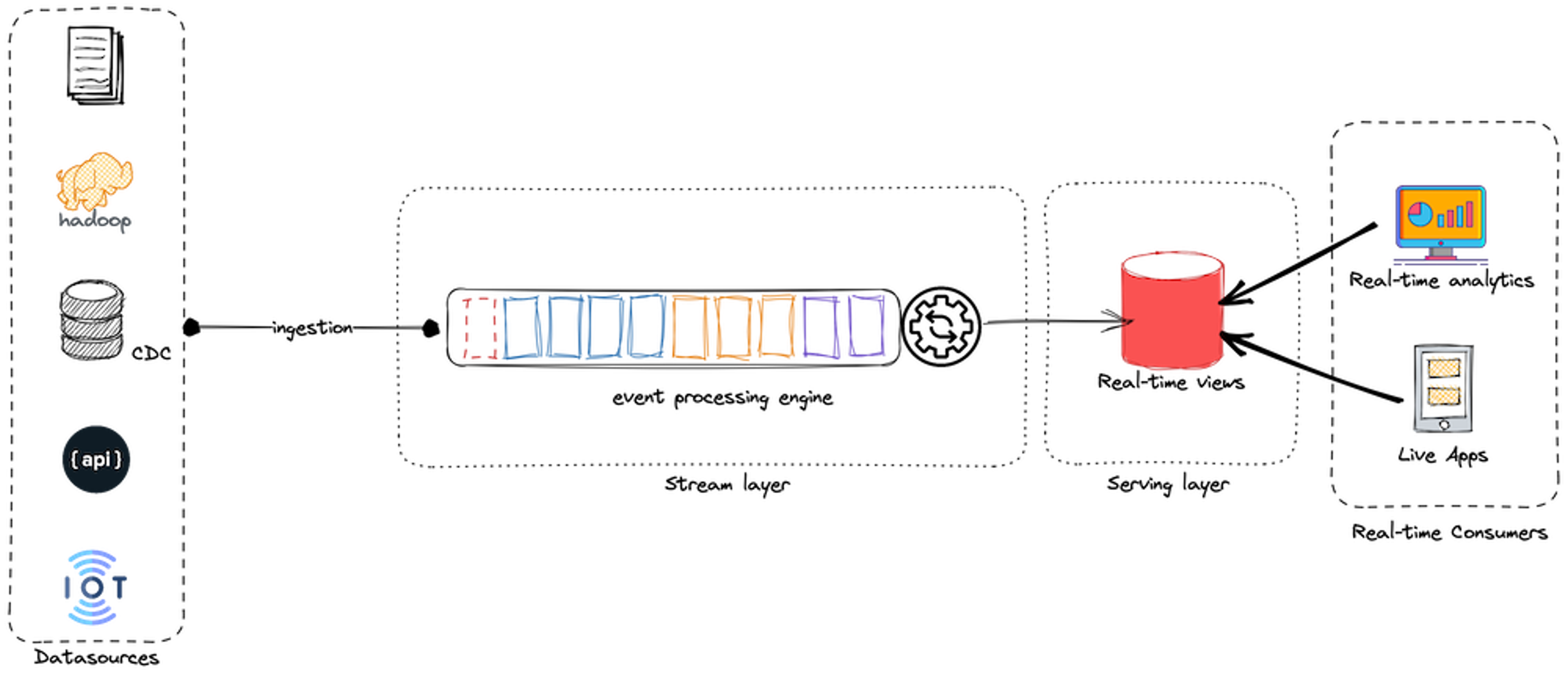
Kappa architecture
Data reprocessing is a key requirement of Kappa, making visible the effects of any changes in the source side on the outcomes. Consequently, the Kappa architecture is composed of only two layers: the stream layer and the serving one.
In Kappa architecture, there is only one processing layer: the stream processing layer. This layer is responsible for collecting, processing, and storing live-streaming data. This approach eliminates the need for batch-processing systems. Instead, it uses an advanced stream processing engine (such as Apache Flink, Apache Storm, Apache Kafka, or Apache Kinesis) to handle high volumes of data streams and to provide fast, reliable access to query results.
The stream processing layer has two components:
- Ingestion component: This layer collects incoming data from various sources, such as logs, database transactions, sensors, and APIs. The data is ingested in real-time and stored in a distributed data store, such as a message queue or a NoSQL database.
- Processing component: This component handles high-volume data streams and provides fast and reliable access to query results. It uses event processing engines, such as Apache Flink or Apache Storm, to process both incoming data in real-time, and historical data (coming from a storage area) before storing information in a distributed data store.
For almost every use case, real-time data beats slow data. Nevertheless, Kappa architecture should not be taken as a substitute for Lambda architecture. On the contrary, you should consider Kappa architecture in circumstances where the batch layer’s active performance is not necessary to meet the standard quality of service.
Kappa architectures promise scalability, fault tolerance, and streamlined management. However, it also has disadvantages. For instance, Kappa architecture is theoretically simpler than Lambda but it can still be technically complex for businesses unfamiliar with stream processing frameworks.
The major drawback of Kappa, from my point of view, is the cost of infrastructure while scaling the event streaming platform. Storing high volumes of data in an event streaming platform can be costly and raise other scalability issues, especially when the data volume is measured in terabytes or petabytes.
Moreover, the lag between event time and processing time inevitably generates late-arriving data as a side effect. Kappa architecture will need, thus, a set of mechanisms, such as watermarking, state management, reprocessing, or backfilling, to overcome this issue.
Exploring the dataflow model
Lambda and Kappa were attempts to overcome the shortcomings of the Hadoop ecosystem in the 2010s by trying to integrate complex tools that were not inherently compatible. Both approaches struggle to resolve the fundamental challenge of reconciling batch and streaming data. Yet, Lambda and Kappa have provided inspiration and a foundation for further advancements.
Unifying multiple code paths is a significant challenge in managing batch and stream processing. Even with the Kappa architecture’s unified queuing and storage layer, developers need to use different tools to collect real-time statistics and run batch aggregation jobs. Today, they are working to address this challenge. For instance, Google has made significant progress by developing the dataflow model and its implementation, the Apache Beam framework.
The fundamental premise of the dataflow model is to treat all data as events and perform aggregations over different types of windows. Real-time event streams are unbounded data, while data batches are bounded event streams that have natural windows.
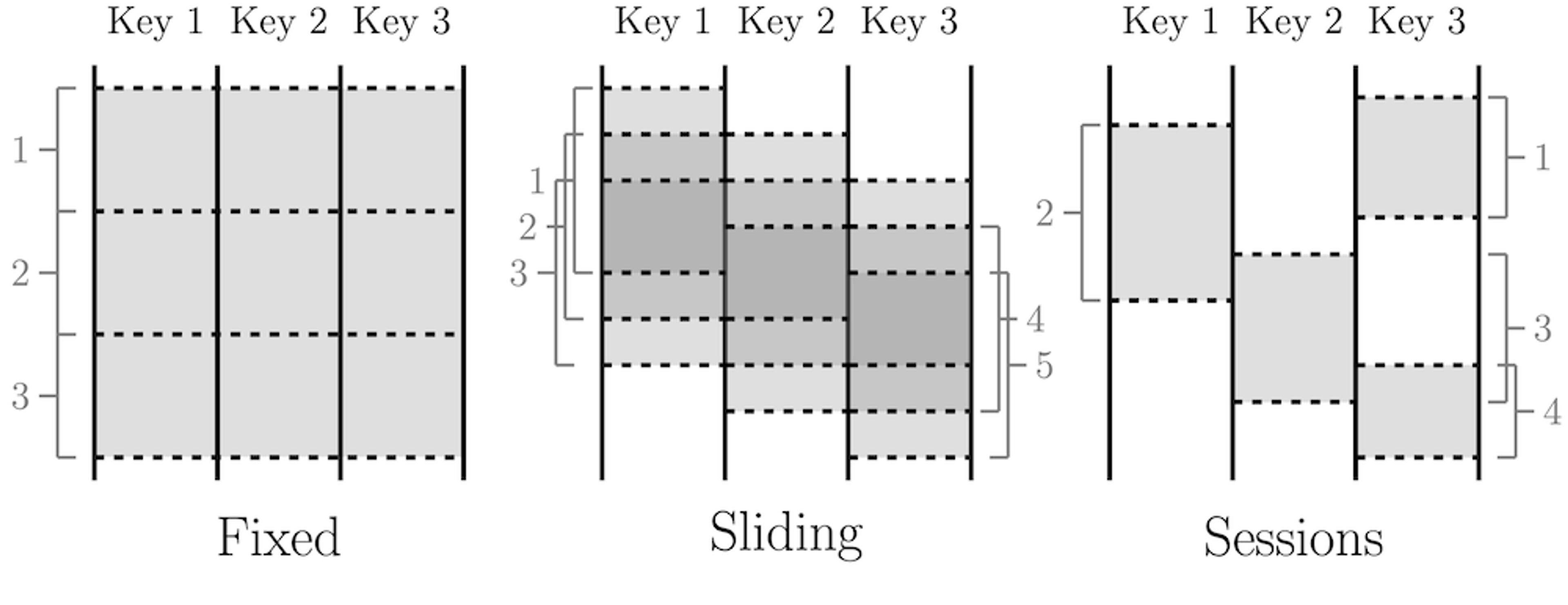
Windowing patterns
Data engineers can choose from different windows, such as sliding or tumbling, for real-time aggregation. The dataflow model enables real-time and batch processing to occur within the same system, using almost identical code.
The idea of “batch as a special case of streaming” has become increasingly widespread, with frameworks like Flink and Spark adopting similar approaches.
There’s another twist on the data architecture discussion in regard to velocity models: the suitable design choices for working with the Internet of Things (IoT). But I’ll leave that for a separate discussion.
It’s clear that the debate over how best to structure our approach to handling data is far from over. We’re just getting started! Consult our white paper, Best Practices for a Modern Data Layer in Financial Services, on the best ways to modernize a rigid and slow IT legacy system and turn it into a modern data architecture.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.