
Your transactions live in one database, your clickstream events land in another, and your analytics team is waiting on a CSV someone forgot to export. Data pipelines exist to fix exactly this: they collect raw data from one or more sources, process or transform it, and deliver it to a destination (such as a data warehouse, data lake, or operational cache) for storage, analysis, or real-time use.
Through 2026, organizations are projected to abandon 60% of AI projects unsupported by AI-ready data, which makes pipelines important infrastructure for both analytics and AI. This guide covers what data pipelines are, how they compare to extract, transform, load (ETL), and why in-memory infrastructure matters for real-time pipeline architectures.
Benefits of a data pipeline
A data pipeline helps teams move data automatically so it arrives faster, with less manual work and fewer avoidable errors. Those benefits matter more as data volume and complexity grow.
- Automation: Pipelines remove manual triggers and human bottlenecks from routine data movement, which lowers the chance of avoidable errors and speeds up delivery.
- Efficiency at scale: A single pipeline can transfer and process large volumes of data in short timeframes while supporting multiple parallel data streams.
- Flexibility: Pipelines work with structured, semi-structured, and unstructured data from different source systems without forcing every input into the same format first.
- Analytical readiness: Data reaches analytics tools in a structured, queryable state rather than as raw, disconnected records.
- AI support: AI workflows depend on fresh, organized inputs. Whether you're feeding a retrieval-augmented generation (RAG) pipeline, running vector search, or serving an AI agent, a data pipeline is what keeps that data current and accessible.
These benefits compound as systems grow, but getting them right starts with understanding how pipelines actually work.
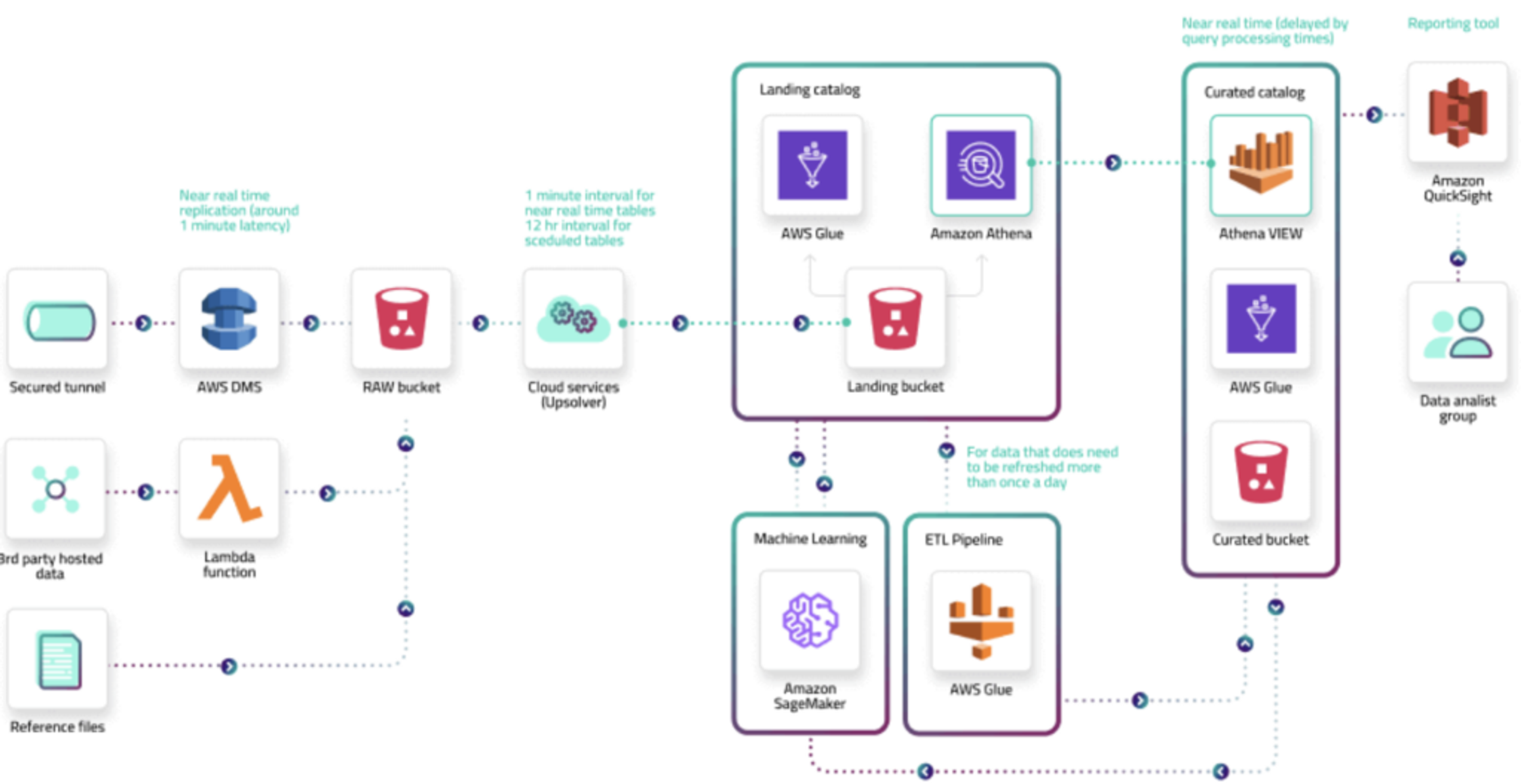
How a data pipeline works
A data pipeline works by moving data through three stages: collection, processing, and delivery. Each stage prepares data for the next one so it reaches the destination in a usable form.
1. Sources
A source is the system where raw pipeline data begins. Common sources include relational database management systems, customer relationship management (CRM) platforms, enterprise resource planning (ERP) systems, social media platforms, event streams, and app logs.
In modern architectures, a single pipeline may draw from dozens of disparate sources at the same time, with each one producing data in different formats and at different rates.
2. Processing steps
Processing steps prepare raw data for use in the destination system. This stage transforms, filters, enriches, and normalizes data to match the requirements of the system receiving it.
This can include converting formats, removing duplicates, joining datasets, or computing aggregations before data moves forward in the pipeline.
3. Destination
A destination is the system where processed data is stored or used. Common targets include data lakes, data warehouses, analytics platforms, and operational databases.
In real-time architectures, the destination may also be an in-memory store with optional disk persistence that serves data directly to apps with low latency.
Types of data pipelines
The two main types of data pipelines are batch pipelines and streaming pipelines. The right choice depends on how fresh the data needs to be for your use case.
Batch data pipelines
Batch data pipelines process data in discrete chunks, either on a fixed schedule or triggered manually. Each run completes once all data in the set has been processed, with run times ranging from minutes to hours depending on data volume.
Because batch jobs can put higher load on source systems, organizations often schedule them during off-peak hours. They work well when freshness isn't the main requirement: payroll processing, billing and invoicing, and historical reporting.
Batch pipelines are also simpler to build and operate than streaming alternatives, which makes them a practical starting point for straightforward data movement needs.

Streaming data pipelines
Streaming data pipelines process data continuously as events occur. Instead of waiting for a batch window to close, they react to data as it arrives.
That makes streaming a good fit when stale data creates business risk. Common use cases include fraud detection and risk scoring, real-time monitoring and alerting, click-stream analysis, and personalization engines.
Batch vs. streaming
Batch and streaming pipelines differ most in timing, freshness, and operational complexity. The differences are easiest to see side by side.
| Characteristic | Batch pipelines | Streaming pipelines |
|---|---|---|
| Processing model | Periodic, scheduled runs | Continuous, event-driven |
| Data freshness | Minutes to hours old | Near real-time |
| Complexity | Lower | Higher |
| Compute pattern | High compute for short bursts | Sustained, lower compute |
| Best for | Payroll, billing, historical reporting | Fraud detection, monitoring, personalization |
Data pipeline vs. ETL
ETL is a subset of data pipelines, not a separate category. It follows a fixed sequence: extract data from sources, transform it to match a target schema, then load it into a database or warehouse. All data pipelines move data between systems, but ETL enforces transformation as a required middle step.
Three differences matter in practice:
- Scope: ETL pipelines end when data lands in a destination. Data pipelines can trigger downstream processes, including activating webhooks, feeding machine learning (ML) models, or routing to multiple systems after loading.
- Transformation: ETL always transforms data before loading. Data pipelines don’t require transformation at all. Some pass raw data through unchanged or defer transformation to the destination (an approach called extract, load, transform, or ELT).
- Timing: ETL pipelines traditionally run in batches, though modern ETL tools increasingly support streaming and micro-batch as well. Data pipelines can do either.
Data pipeline architecture
Beyond the basic stages, data pipeline architecture is the full system that collects, ingests, prepares, and delivers data across connected components. It covers not just where data goes, but how the surrounding systems work together to keep it reliable and usable.
A typical architecture involves four stages:
- Collection: Gathers data from disparate sources and makes it available through APIs or event streams.
- Ingestion: Transfers that data into a storage layer (often a relational database, message queue, or in-memory store) where it can be prepared further. Redis, for example, supports fast data ingest for high-throughput ingestion workloads.
- Preparation: Converts data into a form suitable for analysis, including format conversions, compression, deduplication, and record enrichment.
- Consumption: Delivers prepared data to production systems such as analytics platforms, visualization tools, machine learning models, or app layers that serve end users directly.
A metadata layer also connects these stages, tracking lineage, schema changes, and data quality across the pipeline. That layer becomes especially important as organizations build data platforms for autonomous, AI-driven workflows, where trust and transparency in data movement are harder to maintain manually.
Why real-time pipelines need in-memory infrastructure
As pipelines shift from scheduled runs to continuous processing, infrastructure latency becomes more important. Real-time pipelines work best with low-latency infrastructure because delays in storage and retrieval can slow the whole system down.
Batch pipelines can handle delays measured in minutes or hours. Real-time pipelines can't, especially for use cases like fraud detection, real-time bidding, or live personalization.
Disk-based systems typically add I/O overhead at each stage of the pipeline. In-memory architectures reduce that overhead by keeping data in RAM, which supports fast access across the read and write cycle.
Redis Streams is a data structure that acts like an append-only log, designed for real-time event processing. Redis Streams supports delivery to multiple consumers and scales for high message volumes. Like all Redis data structures, streams can be persisted through Redis Database (RDB) snapshots or append-only file (AOF) logging, making them a fit for event-driven workloads where you need low latency and consumer group semantics.
How Redis supports data pipelines
Within that broader real-time architecture, Redis can support the parts of a pipeline where low latency and high throughput matter most: ingestion, streaming, and serving layers.
- In-memory speed: In one benchmark, enterprise-grade Redis reported more than 200 million operations per second with sub-millisecond latency on a 40-node AWS cluster, making it a fit for ingestion-heavy stages where data arrives faster than disk-based systems can absorb it.
- Cost-efficient storage: Redis Flex combines RAM with solid-state drive (SSD) storage for tiered access, which can cut memory costs by up to 80% in benchmarks, while maintaining fast read performance for large datasets depending on hot/cold data distribution.
- Data-type flexibility: Redis includes data structures that fit common pipeline patterns: Redis Streams for append-only event logs, pub/sub messaging for lightweight event distribution and pipeline decoupling, and hashes, sorted sets, and JSON for structured operational data.
- Deployment options: Redis is available as Redis Cloud (fully managed), Redis Software (self-managed), and Redis Open Source, so pipeline infrastructure can run in whatever operational environment your team needs.
For AI-focused workloads, Redis also supports vector search, semantic caching, and agent memory, so your data pipeline infrastructure and AI infrastructure can run on the same platform.
Real-time data starts with the right infrastructure
Data pipelines move raw information from where it's generated to where it becomes useful. Batch pipelines fit scheduled, high-volume workloads, while streaming pipelines fit use cases that depend on fresh data.
As AI and operational systems put more pressure on latency, the infrastructure underneath your pipelines matters more. Redis keeps data in memory for sub-millisecond access and supports multiple data structures and streaming patterns in one platform, so teams that already use Redis for caching and operational data can add lightweight messaging and vector search without spinning up separate infrastructure.
Try Redis free to see how it fits your pipeline workload, or talk to our team about real-time data infrastructure at scale.
Frequently asked questions (FAQs) about data pipelines
What is the difference between a data pipeline & ETL, & when should I use each?
ETL is a specific subset of data pipelines that enforces transformation before loading. Use ETL when data quality and schema consistency matter more than speed: end-of-day sales consolidation, regulatory compliance reporting, or pre-modeled datasets your analysts expect to query directly.
Choose a broader pipeline architecture when you need operational flexibility: feeding raw data to ML models, supporting ELT patterns where transformation happens inside the destination, or routing the same source to multiple consumers with different transformation needs. If your use case tolerates hours-old data, ETL works well. If you need subsecond freshness or diverse consumption patterns, you need more than ETL can offer.
How do streaming data pipelines compare to batch pipelines in terms of latency, complexity, & cost?
Streaming pipelines can typically deliver sub-second to few-second latency but require sustained, always-on infrastructure. Batch pipelines concentrate resource usage into periodic windows, making them more cost-effective when immediate data access isn't needed. The cost gap narrows when organizations already maintain always-on infrastructure or when the business impact of stale data (undetected fraud, missed personalization) outweighs the incremental expense.
The bigger difference is operational. Streaming systems demand more sophisticated error handling, state management, and backpressure controls because failures can't simply be retried in the next scheduled run. Many teams start with batch and move specific use cases to streaming as latency requirements tighten.
Why is in-memory infrastructure like Redis important for real-time data pipelines?
In-memory infrastructure like Redis reduces the I/O bottleneck that disk-based systems create at each processing stage. When pipelines run continuously, even small storage delays compound across collection, transformation, and delivery steps, degrading end-to-end latency beyond acceptable thresholds. RAM-based systems bypass disk access patterns, enabling low-latency operations that keep pace with high-velocity event streams.
This becomes especially important when business logic depends on immediate action: blocking fraudulent transactions, adjusting ad bids within auction windows, or updating recommendations while users actively browse. The tradeoff involves higher cost per gigabyte and volatility management, but for workloads where staleness creates measurable business risk, keeping active pipeline data in memory shifts from optimization to requirement.
What are the key stages of a data pipeline architecture & how do they work together?
The four stages (collection, ingestion, preparation, and consumption) form a dependency chain. If ingestion can't keep up with collection throughput, data backs up. If preparation introduces latency, consumption delivers stale results.
A metadata layer ties them together by tracking data lineage, schema versions, and quality metrics across the flow. That layer is what lets teams trace issues back to their origin when something breaks downstream. It becomes harder to maintain as organizations add more sources, destinations, and real-time requirements.
What are common use cases where batch pipelines are better suited than streaming pipelines?
Batch pipelines work best when data can age several hours without business consequences. Common examples include end-of-day financial reconciliation, monthly churn analysis, regulatory compliance reporting that requires complete period snapshots, ML model training on historical datasets, and bulk data migrations. Batch pipelines can also optimize costs by running compute-intensive transformations during off-peak hours.
For teams with limited engineering resources, batch is especially pragmatic because it doesn't require backpressure handling, state management, or always-on monitoring. As long as business requirements permit delayed data availability, the simpler operational model makes batch the more efficient starting point.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.