Query syntax
Learn how to use query syntax
Basic syntax
You can use simple syntax for complex queries using these rules:
-
Exact phrases are wrapped in quotes, for example,
"hello world". -
Multiword phrases are lists of tokens, for example,
foo bar baz, and imply intersection (AND) of the terms. -
ORunions are expressed with a pipe (|) character, for example,hello|hallo|shalom|hola.Notes:
Consider the differences in parser behavior in example
hello world | "goodbye" moon:- In DIALECT 1, this query is interpreted as searching for
(hello world | "goodbye") moon. - In DIALECT 2 or greater, this query is interpreted as searching for either
hello worldOR"goodbye" moon.
- In DIALECT 1, this query is interpreted as searching for
-
NOTnegation of expressions or subqueries is expressed with a subtraction symbol (-), for example,hello -world. Purely negative queries such as-fooand-@title:(foo|bar)are also supported.Notes:
Consider a simple query with negation
-hello world:- In DIALECT 1, this query is interpreted as "find values in any field that does not contain
helloAND does not containworld". The equivalent is-(hello world)or-hello -world. - In DIALECT 2 or greater, this query is interpreted
as -helloANDworld(onlyhellois negated). - In DIALECT 2 or greater, to achieve the default behavior of DIALECT 1, update your query to
-(hello world).
- In DIALECT 1, this query is interpreted as "find values in any field that does not contain
-
Prefix/infix/suffix matches (all terms starting/containing/ending with a term) are expressed with an asterisk
*. For performance reasons, a minimum term length is enforced. The default is 2, but it's configurable. -
In DIALECT 2 or greater, wildcard pattern matches are expressed as
"w'foo*bar?'". Note the use of double quotes to contain the w pattern. -
A special wildcard query that returns all results in the index is just the asterisk
*. This cannot be combined with other options. -
As of v2.6.1,
DIALECT 3returns JSON rather than scalars from multivalue attributes. -
Selection of specific fields using the syntax
hello @field:world. -
Numeric range matches on numeric fields with the syntax
@field:[{min} {max}]. -
Georadius matches on geo fields with the syntax
@field:[{lon} {lat} {radius} {m|km|mi|ft}]. -
As of 2.6, range queries on vector fields with the syntax
@field:[VECTOR_RANGE {radius} $query_vec], wherequery_vecis given as a query parameter. -
As of v2.4, k-nearest neighbors (KNN) queries on vector fields with or without pre-filtering with the syntax
{filter_query}=>[KNN {num} @field $query_vec]. -
Tag field filters with the syntax
@field:{tag | tag | ...}. See the full documentation on tags. -
Optional terms or clauses:
foo ~barmeans bar is optional but documents containingbarwill rank higher. -
Fuzzy matching on terms:
%hello%means all terms with Levenshtein distance of 1 from it. Use multiple pairs of '%' brackets, up to three deep, to increase the Levenshtein distance. -
An expression in a query can be wrapped in parentheses to disambiguate, for example,
(hello|hella) (world|werld). -
Query attributes can be applied to individual clauses, for example,
(foo bar) => { $weight: 2.0; $slop: 1; $inorder: false; }. -
Combinations of the above can be used together, for example,
hello (world|foo) "bar baz" bbbb.
Pure negative queries
As of v0.19.3, it is possible to have a query consisting of just a negative expression. For example -hello or -(@title:(foo|bar)). The results are all the documents not containing the query terms.
Field modifiers
You can specify field modifiers in a query, and not just by using the INFIELDS global keyword.
To specify which fields the query matches, prepend the expression with the @ symbol, the field name, and a : (colon) symbol, for each expression or subexpression.
If a field modifier precedes multiple words or expressions, it applies only to the adjacent expression with DIALECT 1. With DIALECT 2 or greater, you extend the query to other fields.
Consider this simple query: @name:James Brown. Here, the field modifier @name is followed by two words: James and Brown.
- In DIALECT 1, this query would be interpreted as "find
James Brownin the@namefield". - In DIALECT 2 or greater, this query will be interpreted as "find
Jamesin the@namefield ANDBrownin ANY text field. In other words, it would be interpreted as(@name:James) Brown. - In DIALECT 2 or greater, to achieve the default behavior of DIALECT 1, update your query to
@name:(James Brown).
If a field modifier precedes an expression in parentheses, it applies only to the expression inside the parentheses. The expression should be valid for the specified field, otherwise it is skipped.
To create complex filtering on several fields, you can combine multiple modifiers. For example, if you have an index of car models, with a vehicle class, country of origin, and engine type, you can search for SUVs made in Korea with hybrid or diesel engines using the following query:
FT.SEARCH cars "@country:korea @engine:(diesel|hybrid) @class:suv"
You can apply multiple modifiers to the same term or grouped terms:
FT.SEARCH idx "@title|body:(hello world) @url|image:mydomain"
Now, you search for documents that have "hello" and "world" either in the body or the title and the term mydomain in their url or image fields.
Numeric filters in query
If a field in the schema is defined as NUMERIC, it is possible to use the FILTER argument in the Redis request or filter with it by specifying filtering rules in the query. The syntax is @field:[{min} {max}], for example, @price:[100 200].
A few notes on numeric predicates
-
It is possible to specify a numeric predicate as the entire query, whereas it is impossible to do it with the
FILTERargument. -
It is possible to intersect or union multiple numeric filters in the same query, be it for the same field or different ones.
-
-inf,infand+infare acceptable numbers in a range. Therefore, greater than 100 is expressed as[(100 inf]. -
Numeric filters are inclusive. Exclusive min or max are expressed with
(prepended to the number, for example,[(100 (200]. -
It is possible to negate a numeric filter by prepending a
-sign to the filter. For example, returning a result where price differs from 100 is expressed as:@title:foo -@price:[100 100].
Tag filters
As of v0.91, you can use a special field type called a tag field, with simpler tokenization and encoding in the index. You can't access the values in these fields using a general fieldless search. Instead, you use special syntax:
@field:{ tag | tag | ...}
Example:
@cities:{ New York | Los Angeles | Barcelona }
Tags can have multiple words or include other punctuation marks other than the field's separator (, by default). The following characters in tags should be escaped with a backslash (\): $, {, }, \, and |.
DIALECT 2 or greater you can use spaces in a tag query, even with stopwords.Notice that multiple tags in the same clause create a union of documents containing either tags. To create an intersection of documents containing all tags, you should repeat the tag filter several times. For example:
# Return all documents containing all three cities as tags
@cities:{ New York } @cities:{Los Angeles} @cities:{ Barcelona }
# Now, return all documents containing either city
@cities:{ New York | Los Angeles | Barcelona }
Tag clauses can be combined into any subclause, used as negative expressions, optional expressions, and so on.
Geo filters
As of v0.21, it is possible to add geo radius queries directly into the query language with the syntax @field:[{lon} {lat} {radius} {m|km|mi|ft}]. This filters the result to a given radius from a lon,lat point, defined in meters, kilometers, miles or feet. See Redis's own GEORADIUS command for more details.
Radius filters can be added into the query just like numeric filters. For example, in a database of businesses, looking for Chinese restaurants near San Francisco (within a 5km radius) would be expressed as: chinese restaurant @location:[-122.41 37.77 5 km].
Polygon search
Geospatial databases are essential for managing and analyzing location-based data in a variety of industries. They help organizations make data-driven decisions, optimize operations, and achieve their strategic goals more efficiently. Polygon search extends Redis's geospatial search capabilities to be able to query against a value in a GEOSHAPE attribute. This value must follow a "well-known text" (WKT) representation of geometry. Two such geometries are supported:
POINT, for examplePOINT(2 4).POLYGON, for examplePOLYGON((2 2, 2 8, 6 11, 10 8, 10 2, 2 2)).
There is a new schema field type called GEOSHAPE, which can be specified as either:
FLATfor Cartesian X Y coordinatesSPHERICALfor geographic longitude and latitude coordinates. This is the default coordinate system.
Finally, there's new FT.SEARCH syntax that allows you to query for polygons that either contain or are within a given geoshape.
@field:[{WITHIN|CONTAINS} $geometry] PARAMS 2 geometry {geometry}
Here's an example using two stacked polygons that represent a box contained within a house.
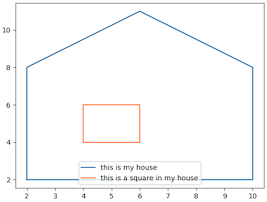
First, create an index using a FLAT GEOSHAPE, representing a 2D X Y coordinate system.
FT.CREATE polygon_idx PREFIX 1 shape: SCHEMA g GEOSHAPE FLAT t TEXT
Next, create the data structures that represent the geometries in the picture.
HSET shape:1 t "this is my house" g "POLYGON((2 2, 2 8, 6 11, 10 8, 10 2, 2 2))"
HSET shape:2 t "this is a square in my house" g "POLYGON((4 4, 4 6, 6 6, 6 4, 4 4))"
Finally, use FT.SEARCH to query the geometries. Note the use of DIALECT 3, which is required. Here are a few examples.
Search for a polygon that contains a specified point:
FT.SEARCH polygon_idx "@g:[CONTAINS $point]" PARAMS 2 point 'POINT(8 8)' DIALECT 3
1) (integer) 1
2) "shape:1"
3) 1) "t"
2) "this is my house"
3) "g"
4) "POLYGON((2 2, 2 8, 6 11, 10 8, 10 2, 2 2))"
Search for geometries contained in a specified polygon:
FT.SEARCH polygon_idx "@g:[WITHIN $poly]" PARAMS 2 poly 'POLYGON((0 0, 0 100, 100 100, 100 0, 0 0))' DIALECT 3
1) (integer) 2
2) "shape:2"
3) 1) "t"
2) "this is a square in my house"
3) "g"
4) "POLYGON((4 4, 4 6, 6 6, 6 4, 4 4))"
4) "shape:1"
5) 1) "t"
2) "this is my house"
3) "g"
4) "POLYGON((2 2, 2 8, 6 11, 10 8, 10 2, 2 2))"
Search for a polygon that is not contained in the indexed geometries:
FT.SEARCH polygon_idx "@g:[CONTAINS $poly]" PARAMS 2 poly 'POLYGON((14 4, 14 6, 16 6, 16 4, 14 4))' DIALECT 3
1) (integer) 0
Search for a polygon that is known to be contained within the geometries (the box):
FT.SEARCH polygon_idx "@g:[CONTAINS $poly]" PARAMS 2 poly 'POLYGON((4 4, 4 6, 6 6, 6 4, 4 4))' DIALECT 3
1) (integer) 2
2) "shape:1"
3) 1) "t"
2) "this is my house"
3) "g"
4) "POLYGON((2 2, 2 8, 6 11, 10 8, 10 2, 2 2))"
4) "shape:2"
5) 1) "t"
2) "this is a square in my house"
3) "g"
4) "POLYGON((4 4, 4 6, 6 6, 6 4, 4 4))"
Note that both the house and box shapes were returned.
For more examples, see the FT.CREATE and FT.SEARCH command pages.
Vector search
You can add vector similarity queries directly into the query language by:
-
Using a range query with the syntax of
@vector:[VECTOR_RANGE {radius} $query_vec], which filters the results to a given radius from a given query vector. The distance metric derives from the definition of a @vector field in the index schema, for example, Cosine or L2 (as of v2.6.1). -
Running a k nearest neighbors (KNN) query on a @vector field. The basic syntax is
"*=>[ KNN {num|$num} @vector $query_vec ]". It is also possible to run a hybrid query on filtered results. A hybrid query allows the user to specify a filter criteria that all results in a KNN query must satisfy. The filter criteria can include any type of field (i.e., indexes created on both vectors and other values, such as TEXT, PHONETIC, NUMERIC, GEO, etc.). The general syntax for hybrid query is{some filter query}=>[ KNN {num|$num} @vector $query_vec], where=>separates the filter query from the vector KNN query.
Examples:
-
Return 10 nearest neighbors entities in which
query_vecis closest to the vector stored in@vector_field:*=>[KNN 10 @vector_field $query_vec] -
Among entities published between 2020 and 2022, return 10 nearest neighbors entities in which
query_vecis closest to the vector stored in@vector_field:@published_year:[2020 2022]=>[KNN 10 @vector_field $query_vec] -
Return every entity for which the distance between the vector stored under its @vector_field and
query_vecis at most 0.5, in terms of the @vector_field distance metric:@vector_field:[VECTOR_RANGE 0.5 $query_vec]
As of v2.4, the KNN vector search can be used at most once in a query, while, as of v2.6, the vector range filter can be used multiple times in a query. For more information on vector similarity syntax, see Querying vector fields, and Vector search examples sections.
Prefix matching
When indexes are updated, Redis maintains a dictionary of all terms in the index. This can be used to match all terms starting with a given prefix. Selecting prefix matches is done by appending * to a prefix token. For example:
hel* world
Will be expanded to cover (hello|help|helm|...) world.
A few notes on prefix searches
-
As prefixes can be expanded into many terms, use them with caution. The expansion will create a Union operation of all suffixes.
-
As a protective measure to avoid selecting too many terms, blocking Redis, which is single threaded, there are two limitations on prefix matching:
-
Prefixes are limited to 2 letters or more. You can change this number by using the
MINPREFIXsetting on the module command line. -
The minimum word length to stem is 4 letters or more. You can change this number by using the
MINSTEMLENsetting on the module command line. -
Expansion is limited to 200 terms or less. You can change this number by using the
MAXEXPANSIONSsetting on the module command line.
-
Prefix matching fully supports Unicode and is case insensitive.
-
Currently, there is no sorting or bias based on suffix popularity.
Infix/suffix matching
As of v2.6.0, the dictionary can be used for infix (contains) or suffix queries by appending * to the token. For example:
*sun* *ing
These queries are CPU intensive because they require iteration over the whole dictionary.
Using a suffix trie
A suffix trie maintains a list of terms that match the suffix. If you add a suffix trie to a field using the WITHSUFFIXTRIE keyword, you can create more efficient infix and suffix queries because it eliminates the need to iterate over the whole dictionary. However, the iteration on the union does not change.
Suffix queries create a union of the list of terms from the suffix term node. Infix queries use the suffix terms as prefixes to the trie and create a union of all terms from all matching nodes.
Wildcard matching
As of v2.6.0, you can use the dictionary for wildcard matching queries with these parameters.
?- for any single character*- for any character repeating zero or more times- ' and \ - for escaping; other special characters are ignored
An example of the syntax is "w'foo*bar?'".
Using a suffix trie
A suffix trie maintains a list of terms which match the suffix. If you add a suffix trie to a field using the WITHSUFFIXTRIE keyword, you can create more efficient wildcard matching queries because it eliminates the need to iterate over the whole dictionary. However, the iteration on the union does not change.
With a suffix trie, the wildcard pattern is broken into tokens at every * character. A heuristic is used to choose the token with the least terms, and each term is matched with the wildcard pattern.
Fuzzy matching
As of v1.2.0, the dictionary of all terms in the index can also be used to perform fuzzy matching. Fuzzy matches are performed based on Levenshtein distance (LD). Fuzzy matching on a term is performed by surrounding the term with '%', for example:
%hello% world
This performs fuzzy matching on hello for all terms where LD is 1.
As of v1.4.0, the LD of the fuzzy match can be set by the number of '%' characters surrounding it, so that %%hello%% will perform fuzzy matching on 'hello' for all terms where LD is 2.
The maximum LD for fuzzy matching is 3.
Wildcard queries
As of v1.1.0, you can use a special query to retrieve all the documents in an index. This is meant mostly for the aggregation engine. You can call it by specifying only a single star sign as the query string, in other words, FT.SEARCH myIndex *.
You can't combine this with any other filters, field modifiers, or anything inside the query. It is technically possible to use the deprecated FILTER and GEOFILTER request parameters outside the query string in conjunction with a wildcard, but this makes the wildcard meaningless and only hurts performance.
Query attributes
As of v1.2.0, you can apply specific query modifying attributes to specific clauses of the query.
The syntax is (foo bar) => { $attribute: value; $attribute:value; ...}:
(foo bar) => { $weight: 2.0; $slop: 1; $inorder: true; }
~(bar baz) => { $weight: 0.5; }
The supported attributes are:
- $weight: determines the weight of the sub-query or token in the overall ranking on the result (default: 1.0).
- $slop: determines the maximum allowed slop (space between terms) in the query clause (default: 0).
- $inorder: whether or not the terms in a query clause must appear in the same order as in the query. This is usually set alongside with
$slop(default: false). - $phonetic: whether or not to perform phonetic matching (default: true). Note: setting this attribute to true for fields which were not created as
PHONETICwill produce an error.
As of v2.6.1, the query attributes syntax supports these additional attributes:
- $yield_distance_as: specifies the distance field name, used for later sorting and/or returning, for clauses that yield some distance metric. It is currently supported for vector queries only (both KNN and range).
- vector query params: pass optional parameters for vector queries in key-value format.
A few query examples
-
Simple phrase query -
helloANDworld:hello world -
Exact phrase query -
helloFOLLOWED BYworld:"hello world" -
Union - documents containing either
helloORworld:hello|world -
Not - documents containing
helloBUT NOTworld:hello -world -
Intersection of unions:
(hello|halo) (world|werld) -
Negation of union:
hello -(world|werld) -
Union inside phrase:
(barack|barrack) obama -
Optional terms with higher priority to ones containing more matches:
obama ~barack ~michelle -
Exact phrase in one field, one word in another field:
@title:"barack obama" @job:president -
Combined AND, OR with field specifiers:
@title:"hello world" @body:(foo bar) @category:(articles|biographies) -
Prefix/infix/suffix queries:
hello worl* hel* *worl hello -*worl* -
Wildcard matching queries:
"w'foo??bar??baz'" "w'???????'" "w'hello*world'" -
Numeric filtering - products named
tvwith a price range of 200 to 500:@name:tv @price:[200 500] -
Numeric filtering - users with age greater than 18:
@age:[(18 +inf]
Mapping common SQL predicates to Redis Query Engine
| SQL Condition | Redis Query Engine Equivalent | Comments |
|---|---|---|
| WHERE x='foo' AND y='bar' | @x:foo @y:bar | for less ambiguity use (@x:foo) (@y:bar) |
| WHERE x='foo' AND y!='bar' | @x:foo -@y:bar | |
| WHERE x='foo' OR y='bar' | (@x:foo)|(@y:bar) | |
| WHERE x IN ('foo', 'bar','hello world') | @x:(foo|bar|"hello world") | quotes mean exact phrase |
| WHERE y='foo' AND x NOT IN ('foo','bar') | @y:foo (-@x:foo) (-@x:bar) | |
| WHERE x NOT IN ('foo','bar') | -@x:(foo|bar) | |
| WHERE num BETWEEN 10 AND 20 | @num:[10 20] | |
| WHERE num >= 10 | @num:[10 +inf] | |
| WHERE num > 10 | @num:[(10 +inf] | |
| WHERE num < 10 | @num:[-inf (10] | |
| WHERE num <= 10 | @num:[-inf 10] | |
| WHERE num < 10 OR num > 20 | @num:[-inf (10] | @num:[(20 +inf] | |
| WHERE name LIKE 'john%' | @name:john* |
Technical notes
The query parser is built using the Lemon Parser Generator and a Ragel based lexer. You can see the DIALECT 2 grammar definition at this git repo.
You can also see the search-default-dialect configuration parameter.