Blog
Throughput-optimizing Redis for L2 KV Cache Reuse



In July, we added Redis to LMCache's southbound tree: Get faster LLM inference and cheaper responses with LMCache and Redis | Redis
We're back to discuss a series of optimizations that we've done in the last few months and what lies ahead for Redis and LMCache.
Why Redis?
LMCache manages a three-tier memory hierarchy for LLM KV cache: L0 (VRAM), L1 (Host RAM), and L2 (external storage — disk, RDMA, databases, object stores).
Redis is one of the most appealing L2 backends due to:
- Cross-cloud portability: Unlike vendor-specific object stores, Redis runs everywhere — AWS, GCP, Azure, on-prem, or at the edge.
- Widespread adoption: Redis is one of the most widely deployed data stores in production. Teams already know how to run, monitor, and scale it.
KV Cache is an unorthodox workload for Redis
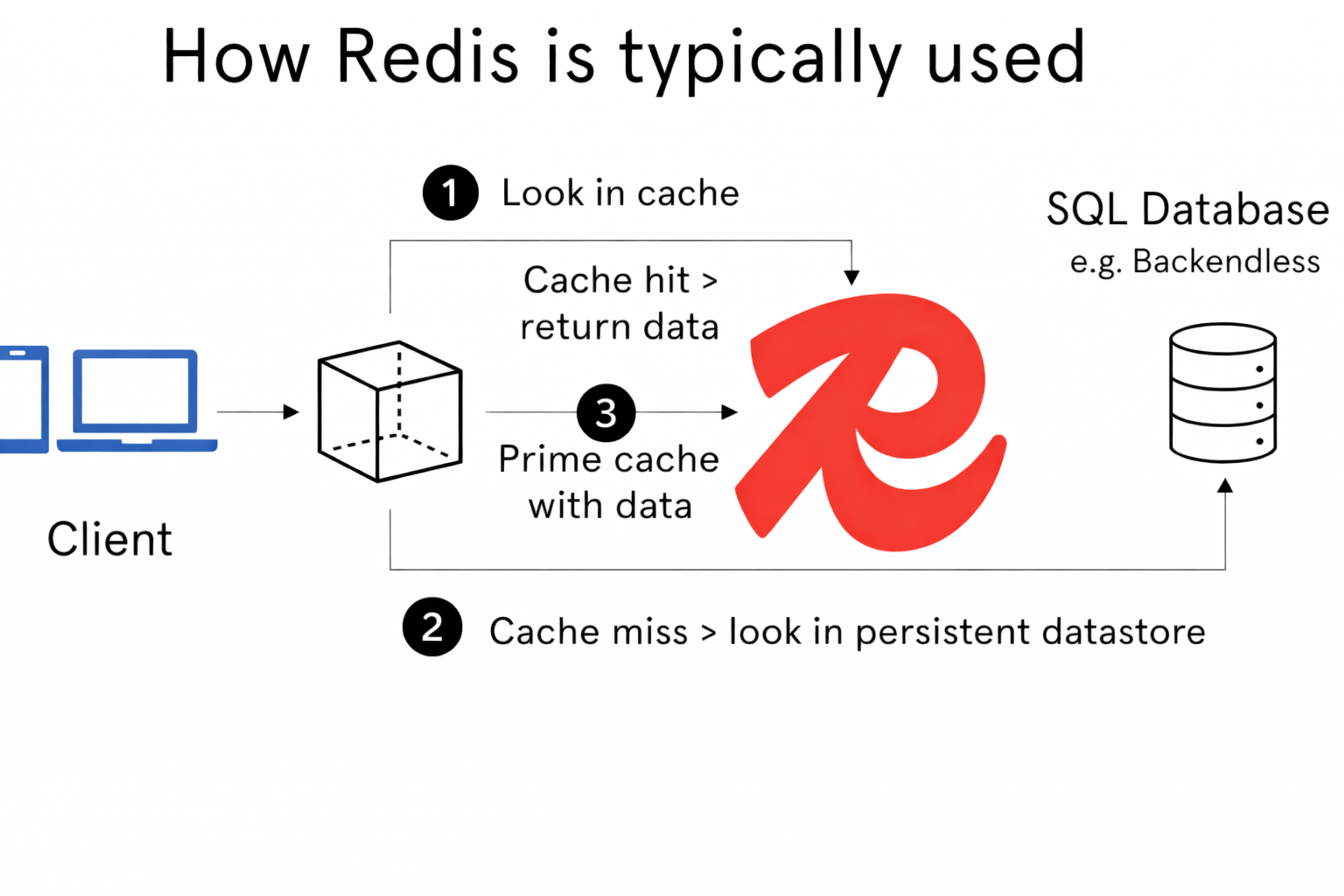
Redis is typically used as a cache for small metadata payloads (1–10 KB) sitting in front of a SQL database. KV cache workloads look nothing like this. Each chunk is 500 KB to 40 MB. For Llama 3.1 8B with a single 10,000 token request, that's 1.2 GB of KV cache data. Even 256 tokens is 31 MB.
The optimization target is different too. Traditional Redis cares about latency and ops/s. For KV cache offloading, what matters is tail latency (every chunk must arrive before inference can continue) and throughput in GB/s (loading has to outrun prefill, or there's no point). The priority ordering for KV operations is: Lookup > Retrieve > Store (since Store is asynchronous). Lookup is generally cheap so what we're really trying to optimize is Redis' retrieval throughput.
We started with the standard Python Redis SDK (redis-py) and measured 0.278 GB/s:
For reference, we need a 2 GB/s SLO for LMCache L2 backends to "outrun" prefill on most modern datacenter GPUs (how this SLO is obtained has to do with the complexity of attention vs loading and could be the topic for another blog post).
Our first break-through
Before writing a single line of optimization code, we needed to know: is this problem even solvable? We played around with the number of tcp streams and pipelining with memtier_benchmark — Redis's optimized benchmarking tool built with C — and ended up seeing the best throughput with 4 MB payloads against a local Redis 8.2 instance:
5.85 GB/s on GET. There exists some Redis client that reaches past the 2 GB/s SLO. The client is the initial bottleneck. We started a standalone benchmarking playground to isolate the client optimizations.
Our subsequent work in optimizing Redis for inference-time KV Cache can be split into 3 phases:
1. The standalone phase: 0.3 GB/s to 5 GB/s
The goal of this phase was to push a pure-Python Redis client as far as it could go, without touching LMCache or vLLM at all.
Eliminate user-space copies (0.3 -> 2 GB/s)
We wrote a custom RESP protocol parser to enforce zero copy on receive and send (scatter-gather).
On reads, recv_exactly_into writes directly into the caller's buffer. No intermediate copies or extra allocations. This immediately brought us to 2 GB/s (retrieve) — a 7x improvement.
KV Cache workload invariant -- fixed size chunks (2 -> 4-5 GB/s)
LMCache chunks KV cache along the token dimension. Normally the last chunk in a sequence can be shorter, so every chunk carries metadata recording its actual length. This seems minor, but it has two compounding costs:
First, every chunk needs two Redis operations — one for the payload, one for the metadata. Dropping metadata halves the quantity of reads and writes.
Second, when the parser knows the payload size in advance, it doesn't need to scan for RESP delimiters across megabytes of data. We called this "abusive parsing": read the size header, assert it matches our known chunk size, then read exactly that many bytes straight into the receive buffer.
The last partial chunk in a sequence gets dropped, making all chunks a uniform fixed size. With these two gains, we're at 4–5 GB/s.
At this point we'd pushed a pure-Python client to the level that memtier_benchmark (in C) was at. This was great news since we haven't descended into GIL-free land yet and so we can do even better.
2. The Integration Phase: Carefully crafting the Python-C++ Boundary (5 -> 10 GB/s)
vLLM and LMCache are both written in python so this forces our hand in the top level interface being python. This phase was about building a C++ client core (csrc/redis/*) and designing the synchronization boundary so that Python level minimizes scheduling on task submission and on gathering completions.
The GIL matters on I/O-bound workloads too
Intuitively, the GIL only matters for compute-bound work but profiling revealed that even with 8+ threads all doing socket operations, the GIL still caused implicit serialization. For example, if two IO completions call back at once, only one of them can schedule and no jobs can dispatch.
The pybind11 layer releases the GIL on the very first line of every call. From that point on, C++ threads run with true concurrency on multiple cores:
Batching and tiling
KV cache retrieval is all-or-nothing: all chunks for a request must arrive before inference can continue. So the client only exposes batched operations (BATCH_TILE_GET, BATCH_TILE_SET, BATCH_TILE_EXISTS), never individual key access. This is useful because if you schedule multiple coroutines in python to dispatch individual GET or SET operations, you never know when your event loop will actually schedule these coroutines. Again, this was revealed by our profiling.
Within a batch, work is divided across threads by tiling (the other way to tile is by request but you need # requests > # threads for this to be efficient) — each thread gets a contiguous slice of the key range, and they cooperate to complete one batch. Threads coordinate through shared atomic state:
Non-polling completion via eventfd
The hardest design problem was getting results back to Python without Python having to poll or block. Our solution uses Linux's eventfd: when the last tile finishes, the C++ worker writes to an event file descriptor. Python's event loop has a reader registered on that fd, so the kernel becomes the one responsible for waking up Python when the C++ side has finished work (implicilty relying on the system clock) — no busy-waiting or polling. Furthermore, multiple tile completions coalesce into a single event, so Python sees one completion per batch regardless of thread count.
This also creates an interface (this could be ugly depending on your opinion) that is compatible with both asyncio.future.Future and concurrent.future.Future and we support both types of futures.
Standalone result: 9–10 GB/s on a 128-vCPU bare-metal node with ConnectX-7 NICs. 30x over the original redis-py client. With the full LMCache integration (E2E Inference) running locally, throughput reached 7 GB/s (a loss of 2-3 GB/s partially due to GPU <-> DRAM transfer as well)
All of these optimizations can be found in: https://github.com/LMCache/LMCache/pull/2541/
3. The Cloud tuning phase: Minimizing network losses
Local throughput doesn't matter if it falls apart over the network. This phase was about getting real inference speedups on cloud-deployed Redis.
Moving to GCP introduced a new set of bottlenecks. Same AZ + VPC is non-negotiable — cross-AZ drops bandwidth 5-10x. TCP stream count matters: on GCP VMs, bandwidth converges around 64 parallel streams at ~40 Gbps, and matching client worker count to that achieves >90% of raw iperf3 throughput. Default TCP buffer sizes on GCP (~212 KB) are also too small for multi-MB transfers.
All of these machine specific characteristics can also be discovered in the “spiky” throughput graph that has a different shape depending on the machine:
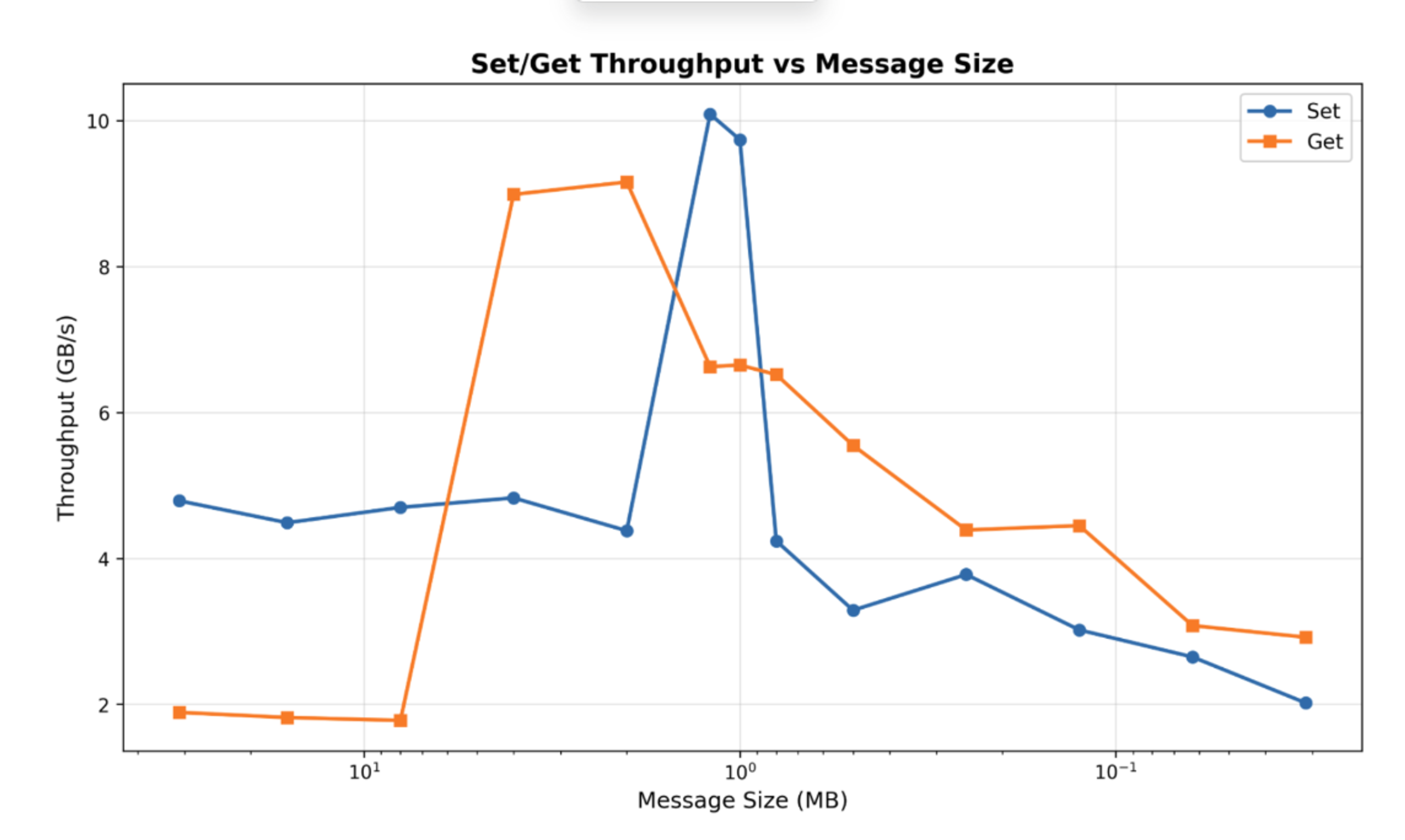
After tuning, self-hosted Redis on a GCP VM in the same AZ and VPC reaches 6 GB/s standalone. Redis Cloud is currently at ~2.6 GB/s — there's more cloud tuning to be done on GCP (e.g. High Tier Networking) and AWS (Placement Groups and Bring Your Own Cloud).
End-to-end inference results
The real test: does retrieving KV cache from Redis over the network beat recomputing it on the GPU? We ran a long-document QA workload (https://github.com/LMCache/LMCache/blob/dev/benchmarks/long_doc_qa/long_doc_qa.py) across two GCP VMs in the same VPC — 8x A100 GPU node and a c2d-standard-112 Redis node — with 40 documents at 40,000 input tokens each, 100 output tokens, 66.7% cache hit rate (every third request has no KV Cache reuse):
| Configuration | Mean TTFT | Total Round Time |
|---|---|---|
| vLLM baseline (no prefix caching) | 32.883 s | 393.485 s |
| LMCache + Redis | 21.517 s | 235.072 s |
| Improvement | 34.6% | 40.3% |
What we’ve learned (so far):
- Isolate phases. Don't conflate bottlenecks. The standalone client, the Python-C++ integration, and cloud networking are three separate problems.
- Define the right metric. Tail latency, not average latency. Throughput in GB/s, not ops/s.
- Exploit workload invariants. KV cache chunks have a known, fixed size per batch. This one property unlocked aggressive parsing, eliminated metadata, and simplified the entire protocol.
- The GIL matters for I/O-bound workloads too. Usually discoverable via profiling.
- Don't assume monotonicity. Throughput vs. chunk size is non-monotonic and machine-specific. Always sweep on target hardware.
- General systems toolkit: batching, zero-copy, non-blocking, non-polling, tiling. We're generalizing optimizations with a new native southbound protocol in LMCache: https://github.com/LMCache/LMCache/pull/2642
Conclusion
Tensormesh and Redis are continuing to work closely together to make Redis a strong backend for KV cache workloads. We’ll keep co-developing high-performance clients and integrations that improve end-to-end throughput and latency for storing and reusing KV cache at scale, helping speed up inference and reduce cost. This partnership will further enable agentic workflows by making cached context and intermediate artifacts easier to reuse across runs, improving responsiveness and scalability in production.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.