Tutorial
Building a Two Tower Recommendation System with RedisVL
February 26, 202633 minute read
TL;DR:A two-tower recommendation system uses separate neural networks for users and items, training on interaction data to produce embedding vectors. Once trained, you store those embeddings in Redis and use vector similarity search for real-time, personalized recommendations — no model inference at query time. This tutorial walks through building one with PyTorch and RedisVL, including location-aware filtering.
Recommendation systems are a common application of machine learning and are widely used across industries, from e-commerce to music streaming platforms.
#What will you learn?
- What the two-tower recommendation architecture is and why it outperforms content-based and collaborative filtering alone
- How to build and train a two-tower model using PyTorch
- How to generate user and item embeddings from raw features
- How to store embeddings in Redis and use RedisVL for vector similarity search
- How to apply geo, time, and attribute filters on top of vector search for location-aware recommendations
- How to visualize recommendations on an interactive map
#What is the two-tower architecture?
A two-tower model (also called a dual-encoder model) is a deep learning architecture for recommendation systems. It uses two separate neural networks — one "tower" for users and one for items — that each learn to map raw features into a shared embedding space. During training, the model learns from user-item interaction data (views, purchases, ratings) so that users and items likely to interact end up with similar embeddings. At inference time, finding recommendations is just a nearest-neighbor vector search — which is exactly what Redis excels at.
The key advantage over simpler approaches: the model can generate embeddings for brand-new users or items using only their raw features, without retraining.
#Prerequisites
- Python 3.9+ with PyTorch, scikit-learn, pandas, and Faker
- RedisVL Python client (
pip install redisvl) - A running Redis instance (local or Redis Cloud)
- Familiarity with vector search concepts
There are several architectures for building recommendation systems. In our previous blog posts we showed how to build two popular approaches that use different techniques. The first went over content filtering with RedisVL, where recommendations are based on an item's underlying features. Next, we showed how RedisVL can be applied to build a collaborative filtering recommender, which uses user ratings to create personalized suggestions. If you haven't checked those out yet they're great places to start your journey into building recommender systems.
#What are the drawbacks of content filtering and collaborative filtering?
Content filtering is perhaps the most straightforward recommender architecture to get started with as all that is needed is data of the products you want to recommend. This means you can get started quickly, and results will be mostly what you expect. Users will be recommended items similar to what they've consumed before. The problem is that with this approach users can get trapped in content silos. In our previous example of using IMDB movies this means that once someone watches one action movie they may only be shown other action movies. They may have really enjoyed a good classic horror film too, but they'll never be recommended it until after they watch something similar. This chicken-and-egg problem is hard for content filtering systems to escape from.
Collaborative systems don't have this silo problem as they leverage other users' behaviors to make personalized recommendations. But they suffer from a different challenge, and that is, 'How do you recommend items to new users, or how do you consider new items that no one has seen yet?' Collaborative filters rely on existing user-item interactions to generate features for users and items, which means they can't naturally handle new entries. With each new interaction their ground truth interaction data changes so model retraining is needed often.
What we want is a way to simultaneously learn from existing user behaviors, but still be able to handle new users and items being added to the system. Two tower models can do just this.
In this post we 'll cover how to build a two-tower recommendation system and compare it to other methods. We'll cover its strengths and how it solves the shortcomings of other approaches. To mix things up a bit, instead of using our movies dataset like the previous two examples, we'll look at brick & mortar restaurants in San Francisco as our items to recommend.
#How do you prepare the restaurant data?
This tutorial walks through how to build this architecture. You can check out a notebook with these steps here. Be sure to have your Redis instance running. First, define some constants and helper methods to load our restaurant data into a pandas DataFrame. We'll be using a set of restaurant reviews in San Francisco. See the original dataset.
Here's a peak at the data we're working with.
| name | address | locality | latitude | longitude | cuisine | price | rating |
|---|---|---|---|---|---|---|---|
| 21st Amendment Brewery & Restaurant | 563 2nd St | San Francisco | 37.782448 | -122.392576 | [Cafe, Pub Food, American, Burgers, Pizza] | 2 | 4.0 |
| Absinthe Brasserie & Bar | 398 Hayes St | San Francisco | 37.777083 | -122.422882 | [French, Californian, Mediterranean, Cafe, Ame... | 3 | 4.0 |
| Amber India Restaurant | 25 Yerba Buena Ln | San Francisco | 37.785772 | -122.404401 | [Indian, Chinese, Vegetarian, Asian, Pakistani] | 2 | 4.5 |
| Americano | 8 Mission St | San Francisco | 37.793620 | -122.392915 | [Italian, American, Californian, Pub Food, Cafe] | 3 | 3.5 |
| Anchor & Hope | 83 Minna St | San Francisco | 37.787848 | -122.398812 | [Seafood, American, Cafe, Chowder, Californian] | 3 | 4.0 |
If you wanted to build a content filtering system now would be a good time to extract the text from the reviews, join them together and generate semantic embeddings from them like we did in our previous post.
This would be a great approach, but to demonstrate the two tower architecture we won't use a pre-trained embedding model like we did with content filtering. Instead we'll use the other columns as our raw features — but first we will extract the numerical ratings from the reviews.
We now have feature vectors with 30 features for each restaurant. The next step is to construct our raw feature vectors for our users.
#How do you generate user features and interaction data?
We don't have publicly available user data to correspond with this list of restaurants, so instead we'll generate some using the popular testing tool Faker.
| user_id | name | username | address | phone_number | birthdate | likes | account_created_on | price_bracket | newsletter | notifications | profile_visibility | data_sharing | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2d72a59b-5b12-430f-a5c3-49f8b093cb3d | Kayla Clark | debbie11 | teresa54@example.net | 8873 Thompson Cape Osborneport, NV 34895 | 231.228.4452x008 | 1982-06-10 | [pizza, pasta, shakes, brunch, bbq, ethiopian,... | 2017-04-18 | middle | True | True | public | True |
| 034b2b2f-1949-478d-abd6-add4b3275efe | Leah Hopkins | williamsanchez | darryl77@example.net | 353 Kimberly Green Roachfort, FM 34385 | 4669094632 | 1999-03-07 | [brunch, ethiopian, breweries] | 1970-06-21 | low | False | True | public | False |
| 5d674492-3026-4cc9-b216-be675cf8d360 | Mason Patterson | jamescurtis | lopezchristopher@example.com | 945 Bryan Locks Suite 200 Valenzuelaburgh, MI... | 885-983-4573 | 1914-02-14 | [cocktails, fine dining, pizza, shakes, ethiop... | 2013-03-10 | high | False | False | friends-only | False |
| 61e17d13-9e18-431f-8f06-208bd0469892 | Aaron Dixon | marshallkristen | becky20@example.org | 42388 Russell Harbors Suite 340 North Andrewc... | 448.270.3034x583 | 1959-05-01 | [breweries, cocktails, fine dining] | 1973-12-11 | middle | False | True | private | True |
| 8cc208b6-0f4f-459c-a8f5-31d3ca6deca6 | Loretta Eaton | phatfield | aaustin@example.org | PSC 2899, Box 5115 APO AE 79916 | 663-371-4597x72295 | 1923-07-02 | [brunch, italian, bbq, mexican, burgers, pizza] | 2023-04-29 | high | True | True | private | True |
Now, create our raw user feature vectors.
Because two tower models are also trained on interaction data like our SVD collaborative filtering model we need to generate some purchases. This will be a 1 or -1 to indicate if a user has eaten at this restaurant before. Once again we're generating random labels for this example to go along with our random users.
Now we have all of our data. The next steps are to define the model and train it.
#How does a two-tower model work?
Two tower models consider the item features as well as user features to make recommendations. They also are trained on user/item interactions like views, likes, or purchases, but once trained are still able to make personalized recommendations to brand new users and with brand new items. They can do this because they are deep learning models that learn embedding representations of users and content by being trained on a subsample of data. They are inductive ML models, which means they can form general rules from samples of data and apply those rules to never-before-seen data. With a trained model you can take a brand new set of users and a brand new set of items and predict their likelihood of interaction. It doesn't matter if your model has seen this exact user or item before.
A typical two tower model architecture can look like this:
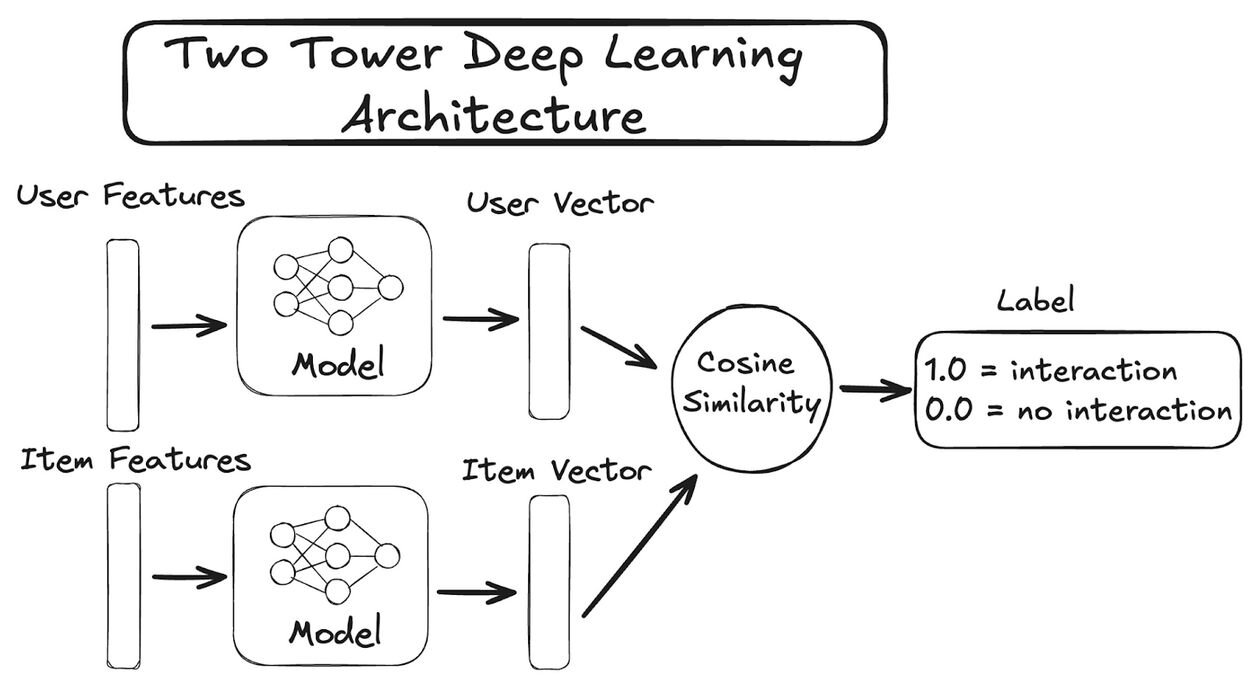
Now that we're familiar with the ideas behind two tower modes we can build our model using Pytorch. We'll start by defining a custom data loader which we'll use during training. This just packages our user and item features together with our label inside of a torch tensor ready for use. Our model definition will include the required
forward(...) method and also two helper methods, get_user_embedding(...) and get_item_embedding(...) so that we can generate new embeddings after training.With our model defined the next step is to prepare our dataset and pass it to our data loader class.
#How do you train the two-tower model?
At last we're ready to train our model. We'll train it via back propagation like any other deep learning model. We've chosen cosine as our loss criteria to match with our architecture diagram and Adam as our optimizer. We've chosen some reasonable defaults for the training steps and model hidden dimensions. Given the randomization of our data your mileage may differ.
#Why use two towers instead of content or collaborative filtering?
This all seems rather complicated compared to other recommender system architectures, so why go through with all of this effort? The best way to answer this is to compare with other recommendation system approaches.
#What are the shortcomings of content filtering?
The simplest machine learning approach to recommendations is content filtering. It's also an approach that doesn't take into account user behaviors beyond finding similar content. This may not sound too bad, but can quickly lead to users getting trapped into content bubbles, where once they interact with a certain item - even if it was just randomly - they only see similar items.
#What are the shortcomings of collaborative filtering?
Collaborative filtering approaches like Singular Value Decomposition (SVD) take the opposite approach and only consider user behaviors to make recommendations. This has clear advantages, but one major drawback; SVD can't handle brand new users or brand new content. Each time a new user joins, or a new content is added to your library they won't have associated vectors. There also won't be meaningful new interaction data to re-train a model and generate vectors. It can be bad enough that a model needs frequent re-training; it can be an even bigger issue if you can't make recommendations for new users and content.
#How do two towers separate training, embedding creation, and inference?
Once we have a trained model we can use each tower in our two tower model to generate embeddings for users and items. Unlike SVD, we don't have to retrain our model to get these vectors. We also don't need new interaction data for new users or content. Even the step of embedding creation only needs to happen once.
#How does the two-tower model combine the best of both worlds?
Two tower models are a triple whammy when it comes to solving the above problems:
- They are trained on interaction data, aka our labels, so learn not to fall into content bubbles
- They directly consider the user features and content features to create personalized recommendations
- they can handle brand new users and content that don't yet have interaction data. No retraining necessary
While we need some interaction data to train our model initially, it's totally fine if not all users or restaurants are included in our labeled data. Only a sample is needed. This is why we can handle new users and content without retraining. Only their raw features are needed to generate embeddings.
#How do you load embeddings into Redis?
With two sets of vectors we'll load the restaurant metadata into a Redis vector store to search over, and the user vectors into a regular key look up for quick access. We'll want to include our restaurants' opening and closing hours, as well as their location in longitude and latitude in our schema so transform them into a usable format. This requires some data transformations. These steps and a sample of the transformed data are shown below.
Here's one sample restaurant record ready to be loaded into our Redis vector store.
The schema we're using to index our restaurant embeddings will also include location and opening and closing times so that we can use them in our search filters. We'll define it from a dictionary, create the index in Redis, and load our restaurant data into it. We'll get back a list of keys.
With our search index created and the restaurant data loaded it's time to load the user vectors into a regular redis space. Our user vectors are the ones used to search with so they don't need an index like our restaurant vectors do. Just keep the user_key handy.
#Why is Redis fast enough for real-time recommendations?
I can hear you say it, "deep learning is cool and all, but I need my system to be fast. I don't want to call a deep neural network to get recommendations."
Well not to fear my friend, you won't have to! While training our model may take a while, you won't need to do this often. And if you look closely you'll see that both the user and content embedding vectors can be generated once and reused again and again. Only the vector search is happening when generating recommendations. These embeddings will only change if your user or content features change and if you select your features wisely this won't be often.
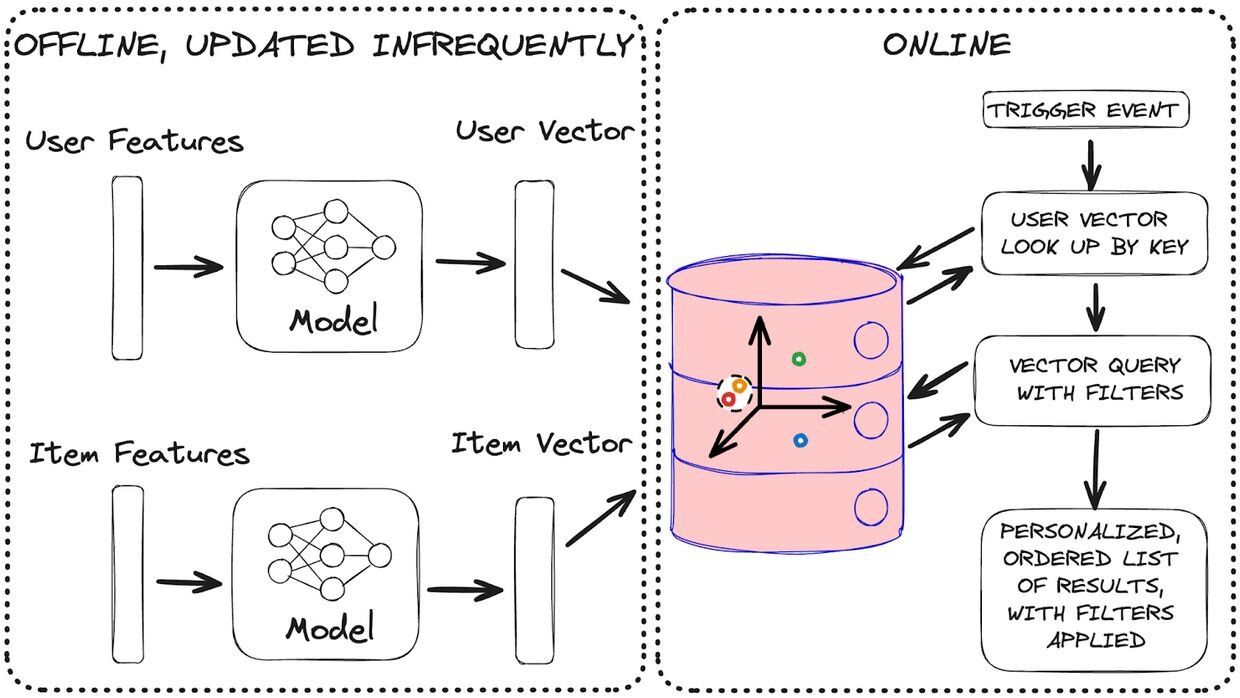
Redis is operating both as a feature store for your user and content embeddings, and also as the final inference layer for lightning fast real time recommendations. This means all the heavy lifting of storing embeddings and performing vector comparisons is handled by your Redis DB and not your app. We used Pytorch to train our embedding model and we need it to generate new embeddings from time to time, but when it comes time to get recommendations all that we need are the user and item vectors. This is why you can have as deep of a neural network as you like when training and generating embeddings and it won't impact inference. We've replaced the last layer of our Pytorch model with Redis vector search.
#How do you add location-aware recommendations?
We've shown how Redis can apply filters on top of vector similarity search to further refine results, but did you know it can also refine search results by location? Using the
Geo field type on our index definition we can apply a GeoRadius filter to find only places nearby, which seems mighty useful for a restaurant recommendation system.Combining
GeoRadius with Num tags we can find places that are personally relevant to us, nearby and open for business right now. We have all our data and vectors ready to go. Now let's put it all together with query logic.#How do you visualize the recommendations on a map?
With our vectors loaded and helper functions defined we can get some nearby recommendations. That's all well and good, but don't you wish you could see these recommendations? I sure do. So let's visualize them on an interactive map.
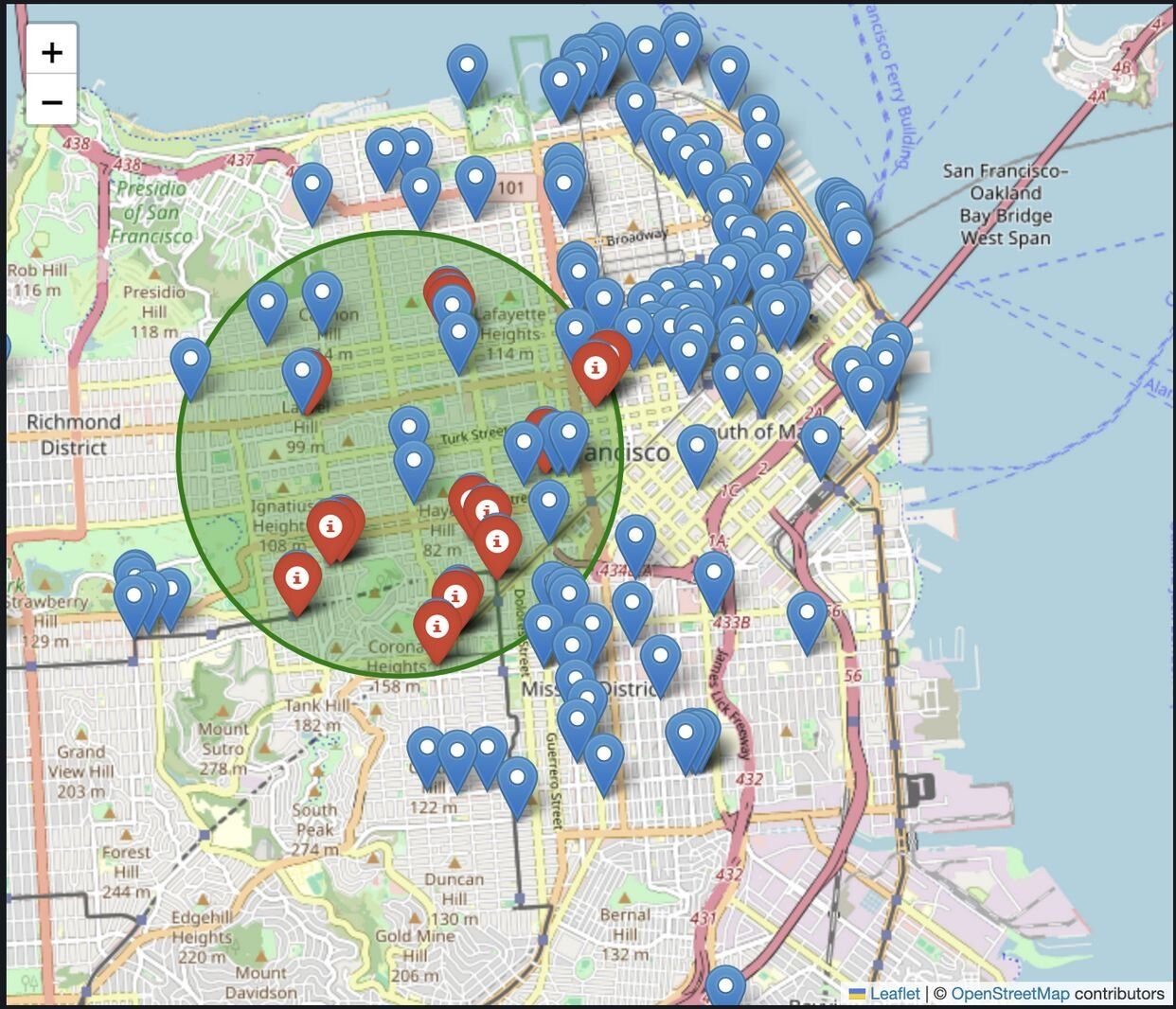
Here you can see all the restaurants in our San Francisco dataset. The points in red are our personalized recommendations for our user. They're also narrowed down to being open right now and within our set maximum radius of 2km. Just what you want when you need a quick late night bite or are desperate for an early morning coffee.
#Summary
That's it! You've built a deep learning restaurant recommendation system with Redis. It's personalized, location aware, adaptable, and fast. Redis handles the scale and speed so you can focus on everything else.
And that concludes our three part series on building recommendation systems with Redis and RedisVL. Along the way we've explored vector search, different similarity metrics - cosine and inner product - different ways to generate user and content embeddings, crafting filters, adding location and time awareness, separating training from inference, and even some deep learning mixed in for good measure.
#Next steps
- Get started with vector search in Redis if you're new to vector similarity search
- Try semantic text search with Redis for another vector search use case
- Build a generative AI chatbot with Redis using vector search for retrieval-augmented generation
- Explore image search with Redis for multimodal vector similarity
- Browse RedisVL on GitHub for the full client library documentation
- See our other AI resources and recipes for more recommendation system examples