Data structures
A data structure is an organized collection of data. It is a unique format for storing data to serve a particular purpose. It is used to access the data and manage it easily. Data structures are a technological means of organizing and storing data in computers so that we can perform operations on the stored data more efficiently. Data structures have a broad and diverse scope of usage across Computer Science and Software Engineering fields.

Strings
Redis Strings is one of the most versatile of Redis’ building blocks, a binary-safe data structure. Strings is an array data structure of bytes (or words) that stores a sequence of elements, typically characters, using some character encoding. It can store any data-a string, integer, floating point value, JPEG image, serialized Ruby object, or anything else you want it to carry. Operate on a whole string or parts, and increment or decrement integers and floats.

Sets
Redis Sets data structure stores a unique set of members. With Sets, you can add, fetch, or remove members, check membership, or retrieve a random member. With the sorting algorithm, you can also perform set operations such as intersection, union, and set difference and compute set cardinality.

Sorted Sets
Redis Sorted Sets contain a unique set of members ordered by floating-point scores. As with Sets, you can add, fetch, or remove individual members and perform set operations such as union, intersection, set difference, and compute cardinality. Furthermore, you can also query the set based on score or member value, aggregate, filter, and order results.

Lists
Redis Lists holds collections of string elements sorted according to their order of insertion. Push or pop items from both ends, trim based on offsets, read individual or multiple items, or find or remove items by value and position. You can also make blocking calls for asynchronous message transfers.

Hashes
A Redis hash is a data type that represents a mapping between a string field and a string value. Redis Hashes structure stores a set of field-value pairs designed not to take up much space, making them ideal for representing data objects. It provides the ability to add, fetch, or remove individual items, fetch the entire hash, or use one or more fields in the hash as a counter.

Bitmaps
Redis Bitmaps is a compact data structure to store binary logic and states. It provides commands to fetch and set a bit value at a given position, and perform AND, OR, XOR, and NOT operations between multiple bitmap keys.
Bitfields
Bitfields offer an efficient, compact way to implement multiple counters in a single array. It allows incrementing and decrementing counters at a given position, and flags overflow when the counter reaches its upper limit.
HyperLogLog
Redis HyperLogLog is a probabilistic data structure used to count unique values (set cardinality) at a constant memory size. You can add and count a large number of unique items with memory efficiency, and merge two or more HyperLogLog data structures into one.
Geospatial indexes
Geospatial indexes provide an extremely efficient and simple way to manage and use geospatial data in Redis. You can add unique items with latitude and longitude, compute the distance between objects, and find members within a given radius range from a location.
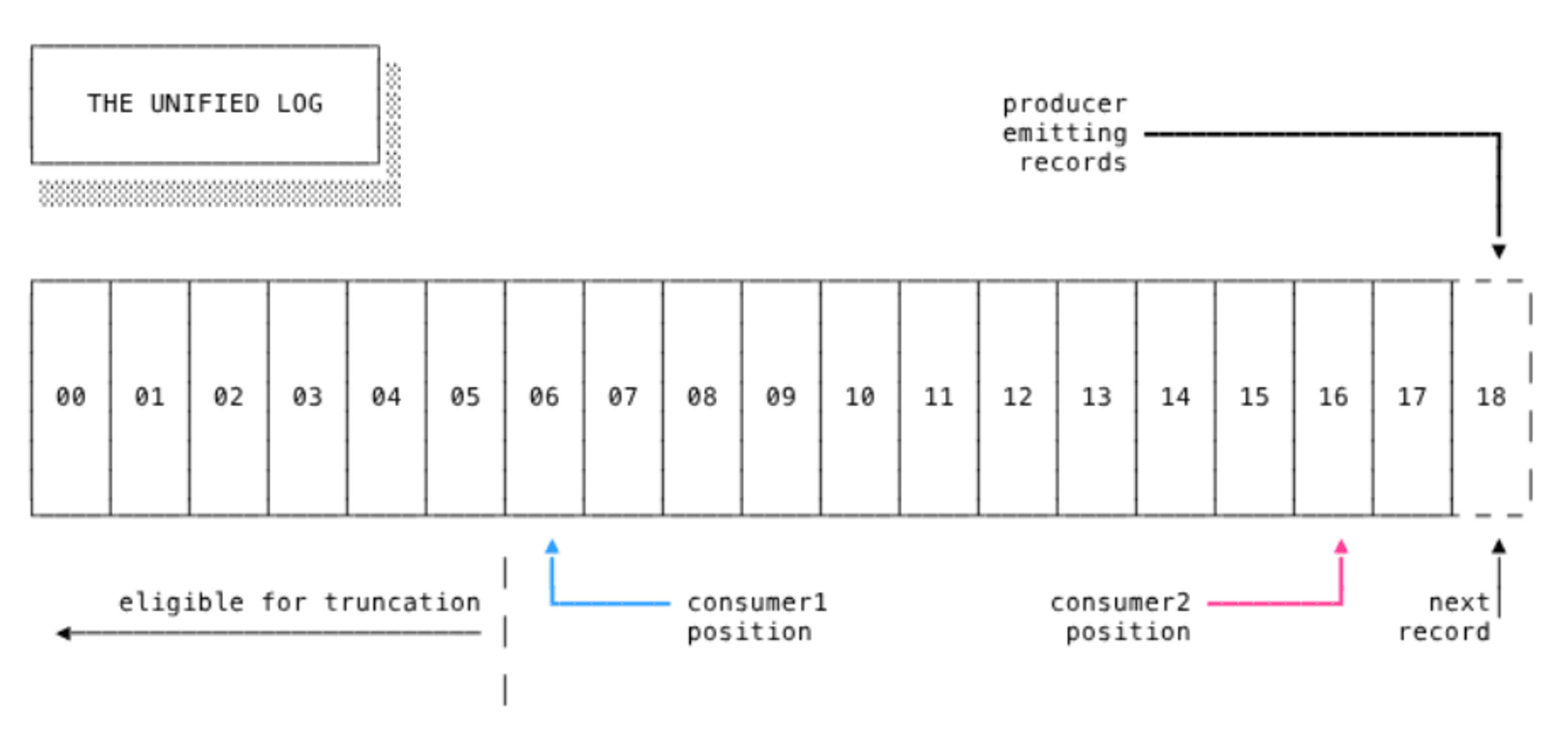
Streams
Redis Streams is an incredibly powerful data structure for managing high-velocity data streams (like a message queue). With out-of-the-box partitioning, replication, and persistence, it can capture and process millions of data points per second at sub-millisecond latency. Redis Streams is based on an efficient radix-tree implementation (an algorithm where each node that is the only child is merged with the parent), which makes the range and lookup queries extremely fast. It connects producers and consumers with asynchronous calls and supports consumer groups.
FAQs
A tree can be represented using Redis HASH and LIST data structures. Redis doesn’t support nested data structures, so you need to represent data and parent attributes as Redis HASH and children as Redis LIST.
In general, a List is just a sequence of ordered elements: 10,20,1,2,3 is a list. But the properties of a List implemented using an Array are very different from the properties of a List implemented using a Linked List. Redis Lists are implemented via Linked Lists, which means that even if you have millions of elements inside a list, the operation of adding a new element in the head or tail of the list is performed in constant time. Accessing an element by an index is very fast in lists implemented with an Array (constant time indexed access) and not so fast in lists implemented by linked lists (where the operation requires an amount of work proportional to the index of the accessed element).
Redis Lists are implemented with linked lists because, for a database system, it is crucial to be able to quickly add a data element to a very long list.
When handling requests from web clients, sometimes operations take more time to execute than we want to spend at that moment. Redis can defer those operations by putting information about our task to be performed inside a queue, which can be processed later. This method of deferring work to a task processor is called a task queue.
Redis can support “first in, first out” (FIFO), “last in, first out” (LIFO), and priority queues. With list-based queues, Redis can handle single-call per queue, multiple callbacks per queue, and simple priorities.
Vector fields allow you to use vector similarity queries in the search command. Vector similarity enables you to load, index, and query vectors stored as fields in Redis hashes.
The linked list provides efficient node rearrangement capabilities and sequential node access methods, and the length of the linked list can be flexibly adjusted by adding and deleting nodes. Linked lists are widely used in Redis. For example, the underlying implementation of a List is a linked list. When a List contains a large number of elements, or the elements in the list are all relatively long strings, Redis will use the linked list.
Redis supports strings, hashes, lists, sets, and sorted sets.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.