Blog
Announcing Redis 8.6: Performance improvements, streams enhancements, new eviction policies, & more

Redis 8.6 in Redis Open Source is now available. This release delivers performance and resource utilization improvements, plus a set of community-requested updates that make day-to-day development and operations smoother. It includes new Streams safeguards, more eviction control, better hotkey visibility, simpler TLS auth, and more flexible time series handling.
- Performance and resource utilization improvements in Redis 8.6
- New features explained:
With Redis 8.6 in Redis Open Source, we continue to deliver on our commitment to continuous performance improvement. The chart below shows our steady throughput increase (operations per second) for a typical caching workload use case across successive releases of Redis.
Redis 8.6 in Redis Open Source: More than 5x throughput compared to Redis 7.2
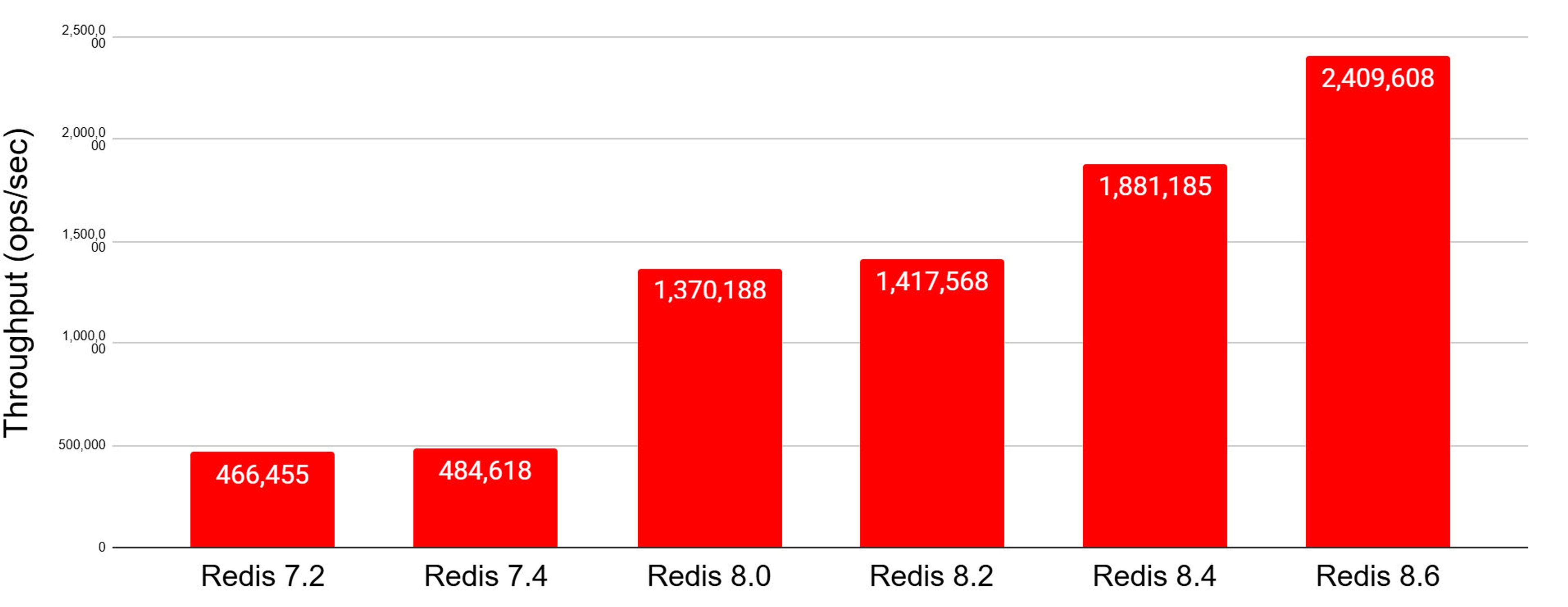
Single node; using only 16 cores on an m8g.24xlarge instance (ARM, Graviton4); 11 io-threads; Pipeline size: 1; 2000 clients Caching use case: 1:10 SET : GET ratio; 1M keys; 1K string values
With pipeline size set to 16, Redis 8.6 reaches 3.5M ops/sec.
Redis performance improvements are not limited to better multithreading. We continuously reduce the latency of many commands. Compared to Redis 8.4, in Redis 8.6, we achieved:
- Up to 35% lower latency for sorted set commands
- Up to 15% lower latency for GET command on short strings
- Up to 11% lower latency on list commands
- Up to 7% lower latency on hash commands
Redis 8.6 max latency improvement compared to Redis 8.4 (single core)
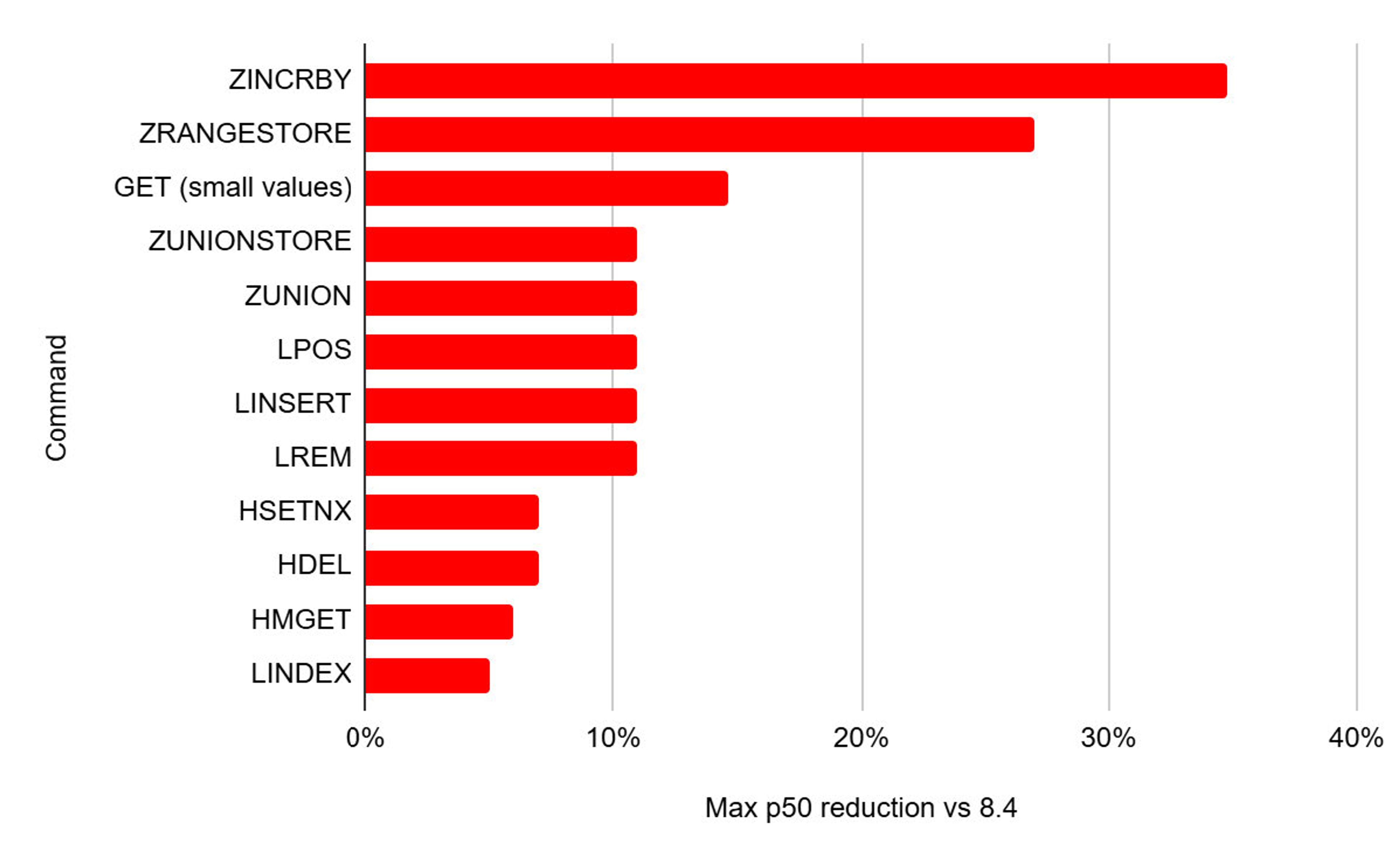
Single node; using a single thread on a m8g.24xlarge instance (ARM, Graviton4)
The throughput and latency improvements are similar on Intel and AMD processors.
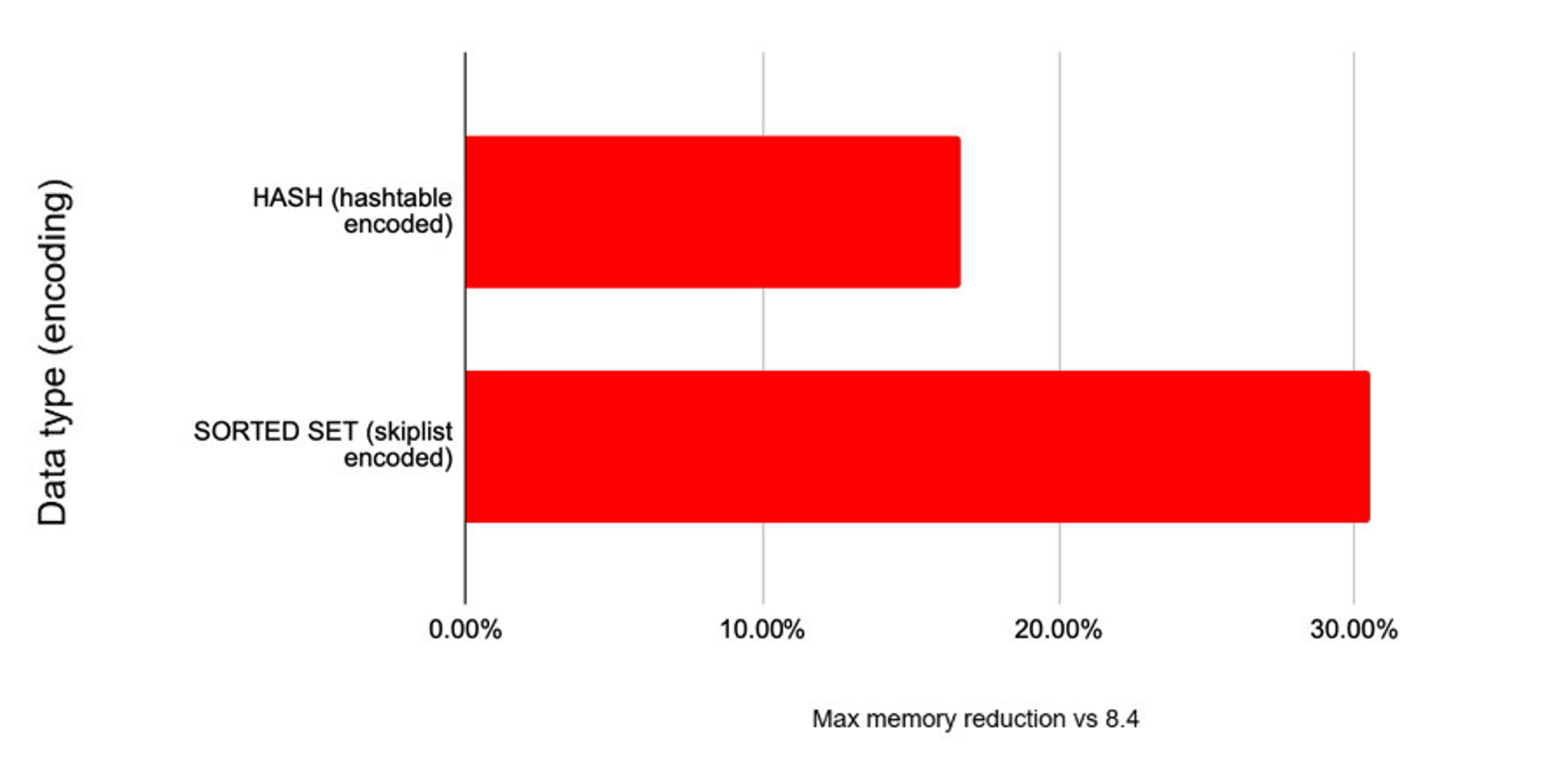
In addition, in 8.6 we achieved a tremendous reduction in the memory footprint of hashes and sorted sets - up to 16.7% and 30.5% respectively.
Redis 8.6 max memory reduction by data type compared to Redis 8.4
Compared to Redis 8.4, in Redis 8.6, we improve vector sets vector insertion performance by up to 43% and querying performance by up to 58%.
VADD improvements on binary and 8-bit quantization for x86-64 architecture
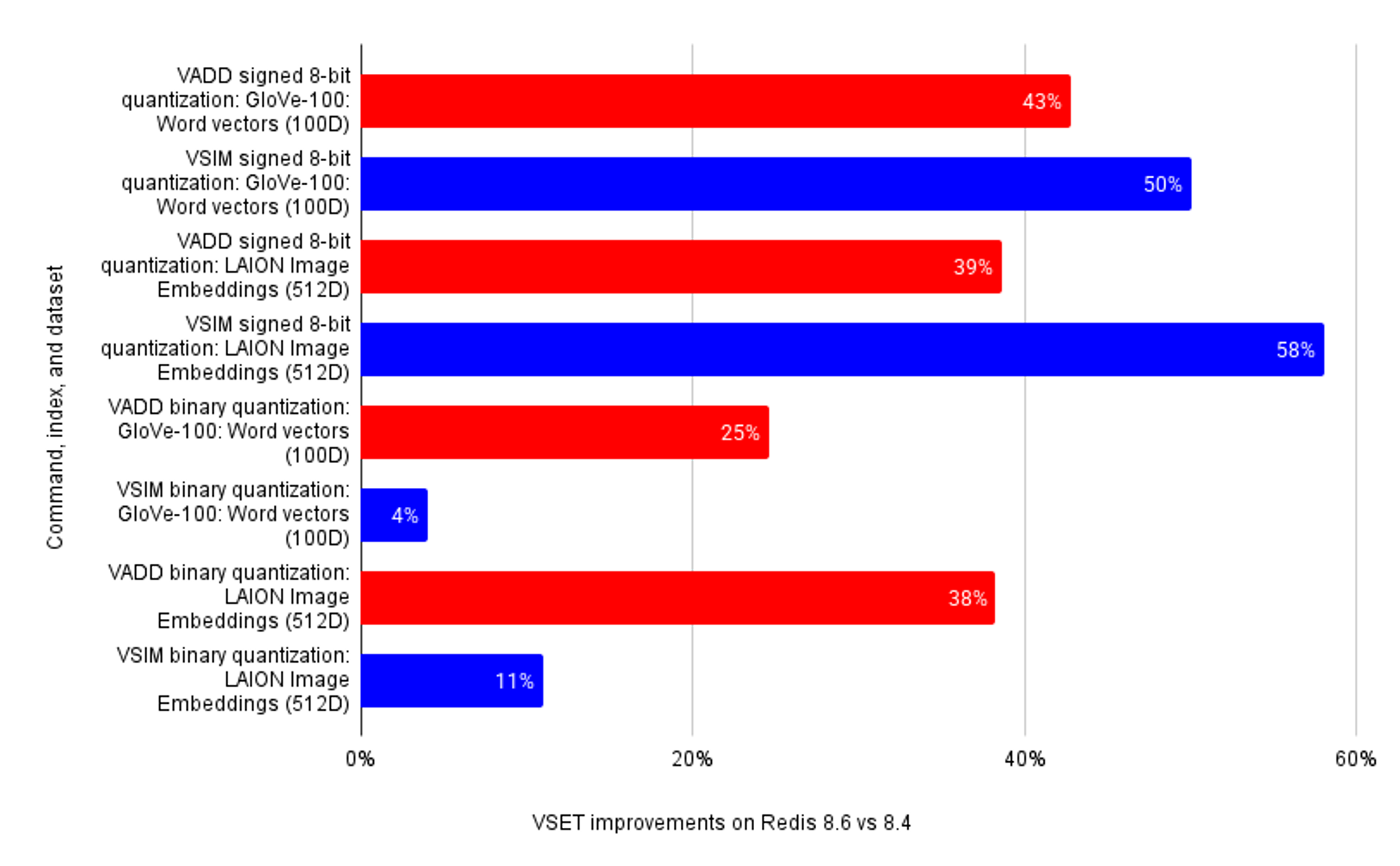
Single node; m8i.24xlarge machine (Intel)
Summary of new features in 8.6
Our investment in improving Redis Streams continues. Redis 8.2 simplified message acknowledgment and deletion across multiple consumer groups, and Redis 8.4 made it much easier for consumers to read both new messages and idle pending ones. In Redis 8.6, we take another step forward by introducing idempotent production: a new guarantee that a message will be added to a stream at most once, even if producers need to resend messages following app crashes or network failures.
Redis has two eviction policies for evicting the least-recently used keys first (either all keys or only volatile keys). In the same spirit, we introduce in 8.6 two new eviction policies for least-recently modified keys. These policies better match AI and other use cases which are explained below.
Optimizing a Redis cluster often requires detecting and handling hot nodes, hot slots, and hot keys, where “hot” means a node, slot, or key that requires an inappropriate amount of CPU or network resources. In 8.2 we introduced CLUSTER SLOT-STATS to detect hot slots, and in 8.4 we introduced Atomic Slot Migration to migrate them. In 8.6, we introduce a new command, HOTKEYS, to allow detection of hot keys as well.
Redis supports both one-way TLS and mutual TLS (mTLS). Prior to Redis 8.6, mTLS clients still had to authenticate at the application layer using AUTH. Starting with Redis 8.6, Redis can automatically authenticate mTLS clients to an ACL user based on the certificate Common Name (CN). When enabled, clients no longer need to issue AUTH, and certificate possession becomes the sole credential, simplifying authentication and eliminating the need to manage ACL passwords.
Time series users often need to mark measurements as “unavailable” at the time of insertion, and fill the data later. In Redis 8.6 we added support for NaN values as a way to mark unavailable data, and extended existing commands to better support such usage.
The new features explained
Streams: At-most-once production guarantee
In Redis 8.6, we introduce idempotent production. Streams now provide a way to ensure that adding the same message to a stream multiple times has the same behavior as adding it only once. This is often called an at-most-once production guarantee meaning Redis will add the same message to a stream only once, even if a producer retries after a crash or network failure.
Why is this guarantee needed?
Imagine a food delivery order. Each message is consumed by multiple consumer groups: the kitchen (for preparation), the inventory management system (for ordering supplies), the delivery company (for physically delivering the order), accounting (for bookkeeping), as well as other services. Adding the same message multiple times to the stream may lead to financial loss, incorrect inventory, and confusion.
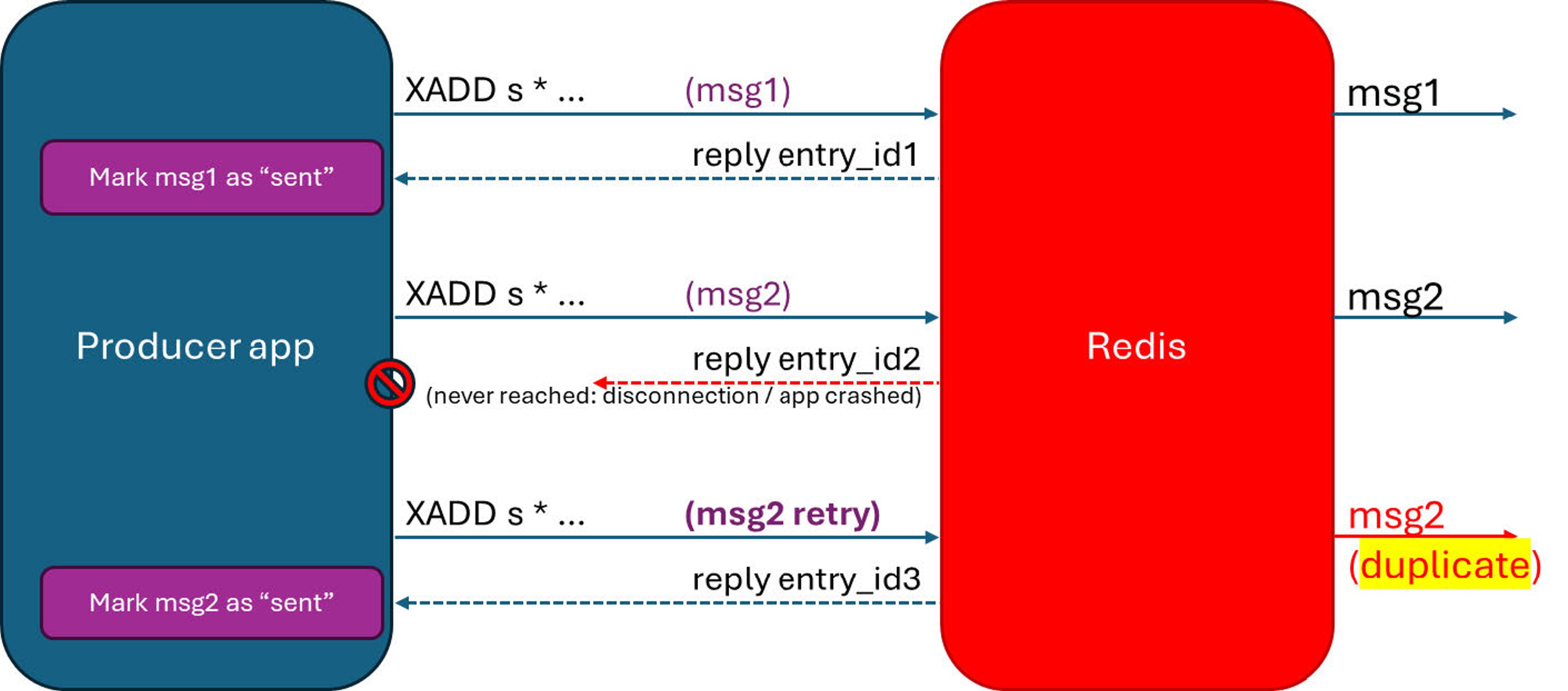
Before Redis 8.6, if a disconnection occurs after the producer calls XADD but before it receives the reply, the producer has no way of knowing if that message was delivered. This can happen in two situations:
- If a disconnection occurs after the producer executes
XADDbut before it receives the reply. - If the producer crashes after calling
XADDbut before receiving the reply and marking a message as delivered.
In both cases, to guarantee that the message is added to the stream, the producer must call XADD again with the same message. Without idempotent production, resending may result in a message being delivered twice. With idempotent message processing, producers can guarantee at-most-once production even under such scenarios.
Behavior without at-most-once production guarantee
Why entry IDs cannot be used as idempotent IDs?
In XADD key .. <id|*> field value [field value ...]Each message has an entry ID which is either timestamp-seq or auto-generated. The entry IDs must be monotonically increasing. Generating monotonically increasing IDs is straightforward when there is a single producer, but with multiple producers, it can be very challenging and often impossible. Therefore, multiple producers are usually forced to use auto-generated entry IDs (‘*’). XADD replies with the auto-generated entry ID, but here is the problem: if the app doesn’t receive the reply, it can’t resend this message with the same ID. And therefore, if a message is re-sent, there is no identifier by which Redis can detect it as a duplicate.
To summarize, we want to allow multiple producers to add entries to a stream in an idempotent way: we want to ensure that Redis adds duplicate entries to the stream at most once, even ifXADD is called multiple times with the same message. We need this guarantee to hold even when facing network disconnections and reconnections, and when producer apps crash and recover.
Introducing idempotent IDs
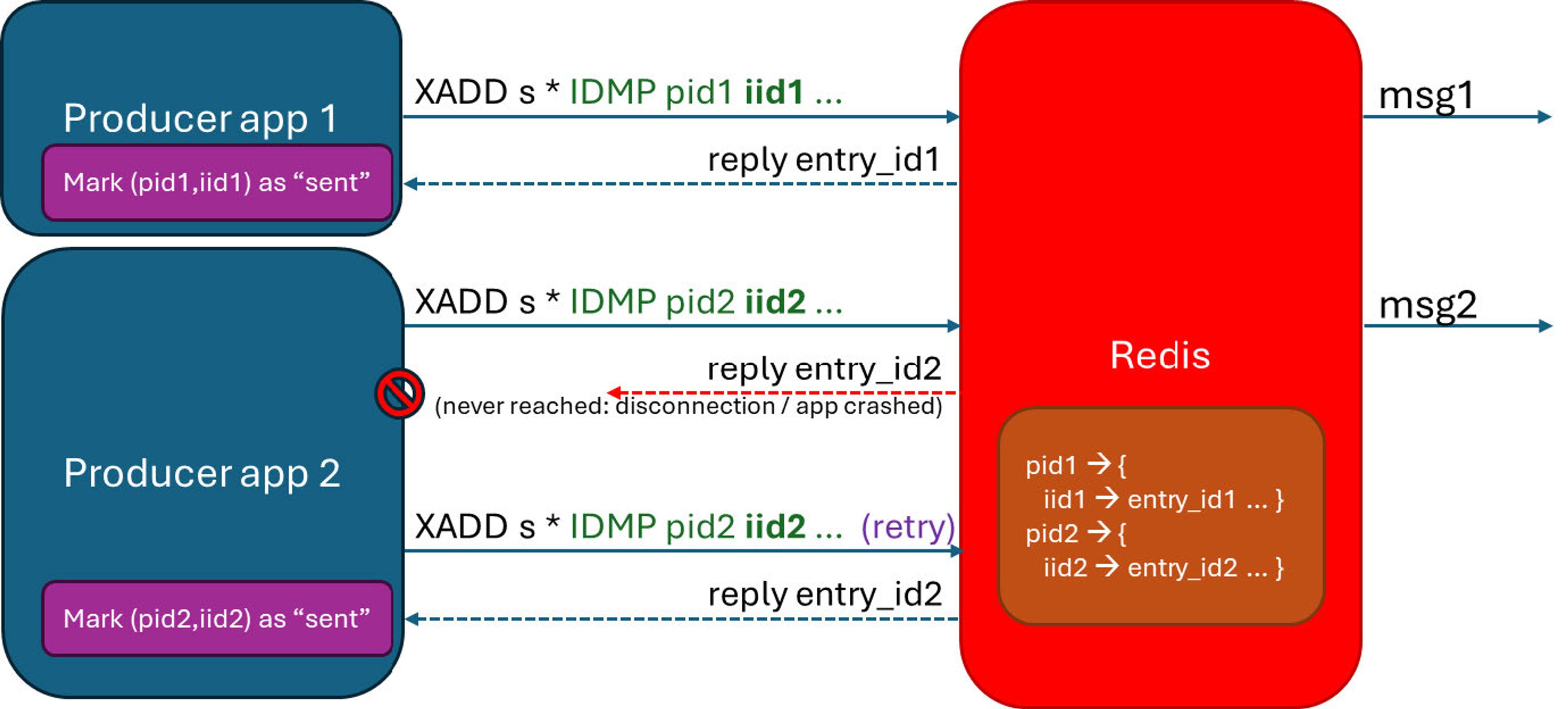
Providing at-most-once production guarantee requires coordination between Redis and producers. Starting with Redis 8.6, producers can associate a unique, idempotent ID, with each message they add to the stream:
There are two ways to assign idempotent ids:
IDMP pid iid- producers need to provide a unique producer id (pid) for each producer and a unique idempotent id (iid) for each message. The iid can be a counter (per producer), some identifier that is already associated with this message (e.g., a transaction id), or a universally unique identifier (UUID).IDMPAUTO pid- producers need to provide only a unique producer id (pid) for each producer. Redis generates an iid based on the message’s content.
The most important point is that if a message is added to a stream more than once – the same pid and iid must be used. Therefore, the application should ensure that:
- pid is unique for each producer and consistent across application restarts
- iid is unique for each message (per pid) and consistent across resends
When XADD is called, Redis checks if the (pid, iid) pair is identical to a recently-added (pid, iid). If so, the message is assumed to be identical, a duplicate message is not added to the stream, and the reply is the same entry id as before.
Note that if the message content in different messages can be identical, apps should avoid IDMPAUTO pid and use IDMP pid iid.
Idempotence configuration
In order to detect duplicate messages, Redis needs to keep the recently seen iids per pid. Keeping more iids than necessary requires more memory and may also slower ingestion through XADD. Therefore, it is important to determine the optimal configuration values.
In Redis 8.6, we introduced a new command for Setting a stream’s duration and maxsize:
When XCFGSET is called with different duration or maxsize values than the current, Redis updates the values and clears the IDMP map for the given key (i.e., discards all tracked pids and iids).
Two idempotence configuration parameters are associated with each stream:
- maxsize is the maximum number of most recent iids that Redis keeps per pid
- duration is the duration, in seconds, that Redis keeps each iid (but note that Redis never keeps more than maxsize iids per pid).
duration is an operational guarantee: Redis will not discard a previously seen iid for that duration (unless reaching maxsize iids for a pid). If a producer app crashes and stops sending messages to Redis, Redis will keep each iid for duration seconds, and then will discard it. You should set this value based on how long it may take your producer app to recover from a crash and start resending messages. If set too high, Redis will waste memory bykeeping iids for a longer duration than necessary.
Example: If it can take up to 1000 seconds for a producer to recover and restart sending messages, duration should be set to 1000 seconds.
When a producer app retrieves an XADD reply from Redis, it usually marks the message as “delivered” (e.g., in some transactions log) or deletes it (e.g., from a transactions table). If a producer app crashes, after restarting, the app sends messages that are not marked as “delivered”. Since a few messages may have not been marked as “delivered” as a result of the crash, the app may resend these messages. This is exactly why we need idempotent IDs: to allow Redis to detect such messages as duplicates and filter them.
Setting maxsize correctly ensures that Redis keeps enough iids. If set too high, Redis will waste memory by keeping too many iids. Usually this number can be small. If your app marks messages as “delivered” (or deletes them) upon retrieval of XADD replies from Redis (it should, to support messaging resending after recovering from a crash), then you should set maxsize based on how long it may take from the time the app retrieves an XADDreply from Redis till this message is marked as “delivered” or deleted. Let’s name this period mark-delay. maxsize should be set to mark-delay [in msec] * (messages/msec from one producer) + some margin.
Example: A producer is sending 1000 msgs/sec (1 msg/msec), and takes up to 80 msec to mark a message as “delivered” or delete it. maxsize should be set to 1*80 + margin = 100 iids.
We also introduced two new global configuration parameters:
stream-idmp-duration - the default idempotence duration (in seconds)
stream-idmp-maxsize - the default idempotence maxsize (number of iids for each pid)
These default values apply to each new stream for which XCFGSET is not called.
New eviction policies: Least recently modified
Redis eviction policies define how Redis frees memory when it reaches the maximum memory limit. Redis supports multiple eviction policies. Applications may choose the policy that best suits their use case. For example, for pure caching use cases, allkeys-lru or allkeys-lfu are often used, while volatile-lru is often used when there are keys with no associated expiration that you don’t want to evict.
In 8.6, we introduce two new least recently modified (LRM) eviction policies: volatile-lrm and allkeys-lrm. These eviction policies are useful for evicting keys that haven't been modified recently, regardless of how frequently they are read.
Compared to least recently used (LRU) policies:
- LRU refresh keys on both read and write operations
- LRM refresh keys only on write operations
The volatile policies evict only keys that have an associated expiration time (TTL), while the allkeys policies evict all keys.
When to use the new LRM policies?
If you have keys that are read constantly but stop being updated, LRU will keep them because reads keep refreshing recency, but the new LRM policy will evict them because reads don’t count - only writes do.
Examples:
- Cached responses that should disappear if the producer stopped refreshing them.
- Aggregated data that should be periodically refreshed
Another use case is when you have two sets of keys - short-lived (say, 1h TTL - cache) and long-lived (say, 7 days TTL - semantic cache, which are not modified), and you want to evict keys from the second group first, regardless of the current remaining TTL. By introducing an LRM eviction policy, since long-lived keys are not modified, you can ensure that these keys will be evicted first, regardless of the read patterns.
Detecting and reporting hotkeys
Hot keys are keys whose internal structure or access patterns result in a disproportionate consumption of resources - either CPU or network bandwidth.
A key may become hot not because it is accessed frequently, but because the operations performed on it are computationally expensive or because they involve transferring large volumes of data over the network.
When such resource-intensive operations are concentrated on a single node, that node can become overloaded, even if the overall request rate is relatively low. In many cases, node overload can be alleviated by redistributing slots across the cluster. Redis 8.4 introduced Atomic Slot Migration, which enables safe and efficient migration of slots to rebalance load. However, this approach assumes that resource usage within a node is reasonably distributed across its slots.
If one or more hot keys dominate the resource consumption within a node, migrating slots may simply transfer the overload to another node. In such scenarios, hot keys must be identified and examined at the per-key level within the affected slots, and mitigated directly, by optimizing command usage, reducing payload sizes, or redesigning data models and access patterns.
Redis 8.6 introduces a new mechanism for collecting and reporting hot keys within specified hash slots.
The HOTKEYS START <METRICS count [CPU] [NET]> [COUNT k] [DURATION duration] [SAMPLE ratio] [SLOTS count slot…] command starts collecting resource consumption for the specified metrics, which can include CPU consumption and network utilization.
During the collection period, Redis maintains, for each requested metric, a list of the top-k keys with the highest resource consumption:
- CPU: Redis tracks the keys with the highest CPU time consumption.
- NET: Redis tracks the keys with the highest network utilization.
Collection can be limited to specific hash slots using the SLOTS option. If no slots are specified, Redis collects data for all slots hosted on the node. The collection continues for the specified duration (in milliseconds) or until HOTKEYS STOP is called. At any point during the collection, or after it has completed, the results of the most recent collection session can be retrieved using HOTKEYS GET.
Reporting and metrics
HOTKEYS GET reports the names of the top-k keys for each requested metric. In addition:
- For
CPU, the report value represents CPU time consumed (in milliseconds) during the collection period. - For
NET,the reported value represents network utilization (in bytes) during the collection period.
Additional metrics are included to support normalization and interpretation of these values.
Performance considerations
The HOTKEYS collection process consumes system resources, and during collection Redis performance may be impacted. This impact can be reduced by increasing the SAMPLE ratio.
When a sampling ratio is set, Redis measures only one out of every ratio commands (selected randomly). A higher sampling ratio reduces overhead but may decrease accuracy. In practice, sampled measurements are often sufficiently accurate for identifying hot keys, especially over longer collection periods (for example, a sampling ratio of 100 over 24 hours).
Accuracy considerations
TheHOTKEYS implementation is based on a probabilistic top-k data structure. As a result, some inaccuracies in the reported keys or rankings are possible. These inaccuracies are generally bounded and acceptable for diagnostic and troubleshooting purposes.
TLS certificate-based automatic client authentication
Redis supports both one-way TLS (client authenticates the server) or mutual authentication (mTLS). Prior to Redis 8.6, even when mTLS was active (tls-auth-clients yes), clients still needed to authenticate at the application layer using the AUTH command with a legacy global password (requirepass) or an ACL username and password. Starting with Redis 8.6, a new feature allows the server to automatically authenticate mTLS clients to a specific ACL user based on the certificate's Common Name (CN).
When this feature is enabled (tls-auth-clients-user CN), clients no longer need to call AUTH after the TLS handshake. This eliminates the operational burden of managing and rotating separate ACL passwords. In this model, you simply define an ACL user with nopass (e.g., ACL SETUSER <CommonName> on nopass … ) and the possession of a valid, signed certificate serves as the sole, secure credential.
Time series: Support NaN values
Redis’ time series data type is often used to track prices, volumes, exchange rates, yield, etc. of financial instruments (such as stocks, commodities, currencies, etc.) Before Redis 8.6, time series values were required to be valid floating-point values. NaN was specifically disallowed.
Multiple users requested a way to mark timestamps with unknown data - often these are values that weren’t available at real-time and need to be filled later. To support such use cases, we now allow adding NaN values to mark unavailable data. We added the following to Redis 8.6:
TS.ADDandTS.MADDsupport NaN values- All raw measurement reports include NaN values
- All the existing aggregators (e.g.,
COUNT,MIN,MAX,SUM) ignore NaN values - Two new aggregators are introduced:
countNaN- counts the number of NaN valuescountAll- counts the number of values (both numeric and NaN values)
Getting started
All these enhancements are generally available on Redis 8.6 today. You can start using the new commands by downloading Redis 8.6 and experimenting with them in your existing workflows.
Have feedback or questions? Join the discussion on our Discord server or reach out to your account manager.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.