Blog
Available Now: Redis & Memcached Clouds across Multiple Availability Zones

We have just announced the launch of our Multiple Availability Zones for Garantia Data’s Redis & Memecached clouds. To learn how our Multi-AZ solution works, just keep reading. Availability Zones are used to segment the physical structure of a cloud’s data center (a.k.a. region) into independent sections in order to compartmentalize the impact of major catastrophes. Modern high availability practices use multiple availability zones from which to run several instances of the application. This is done so a failure of a single zone won’t stop the application from running from surviving zones. Depending on the actual nature of the setup that you want “zoned out,” the effort required to actually make it happen ranges from trivial to absurdly difficult. A typical application is usually a stateless engine, so running it from multiple zones requires very little effort, if any. Datastores, on the other hand, are almost always stateful and thus require some form of consistency that is harder to achieve. In the case of in-memory datastores, the challenge is greater given the main storage’s volatility and significantly higher update rates.
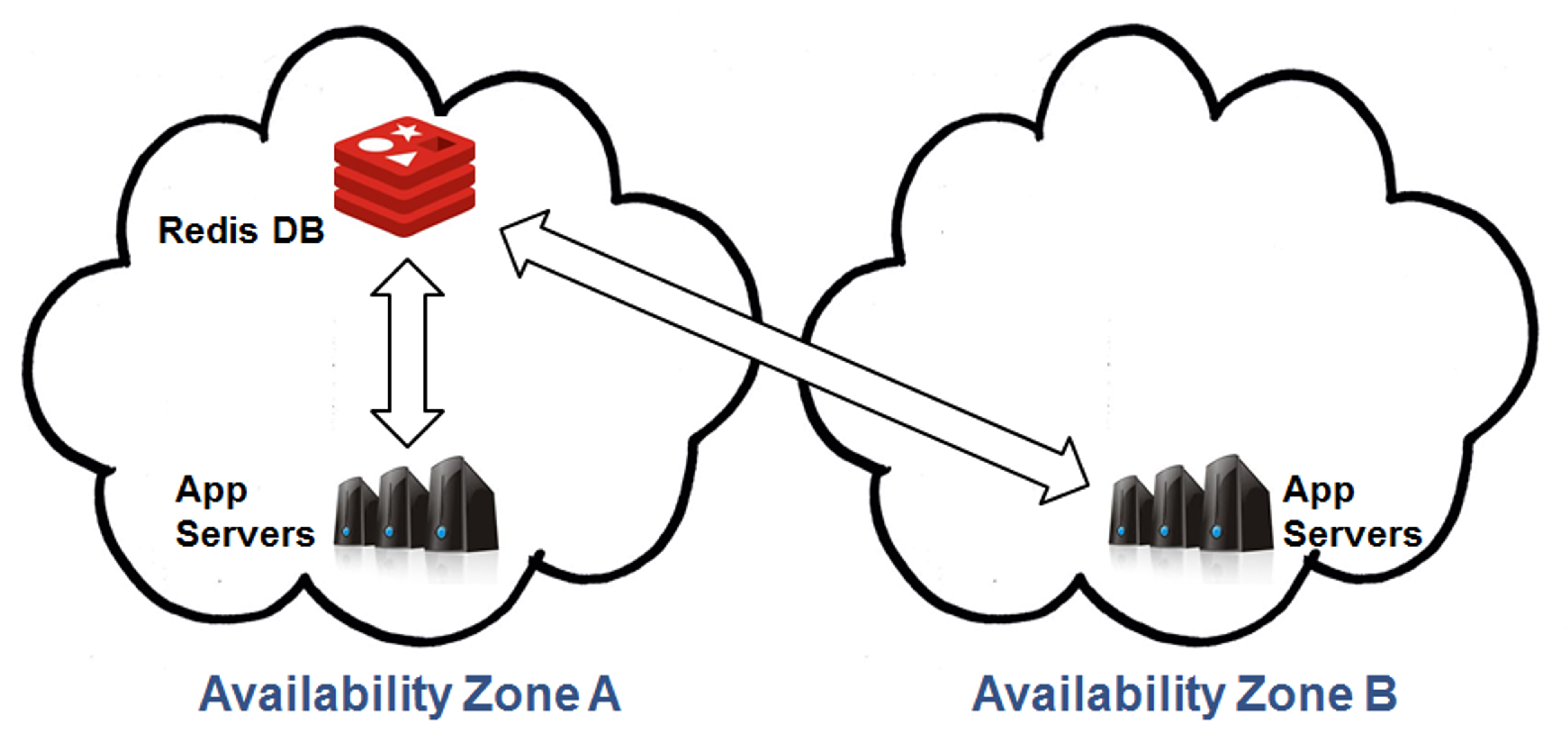
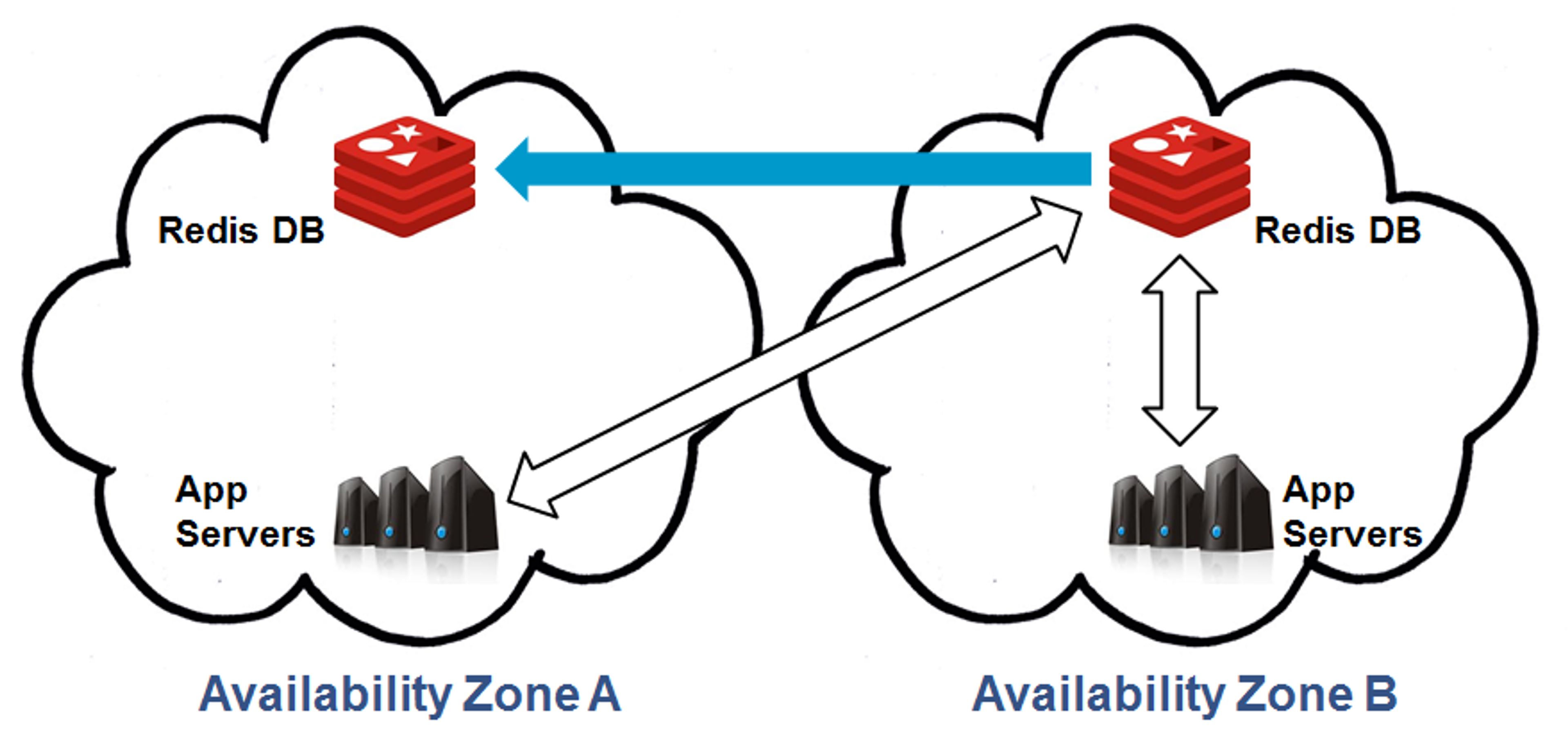
The following description relates to our Redis Multi-AZ solution, however it is also applicable to our Memcached Multi-AZ solution. A typical Multi-AZ environment is shown in the diagram below.
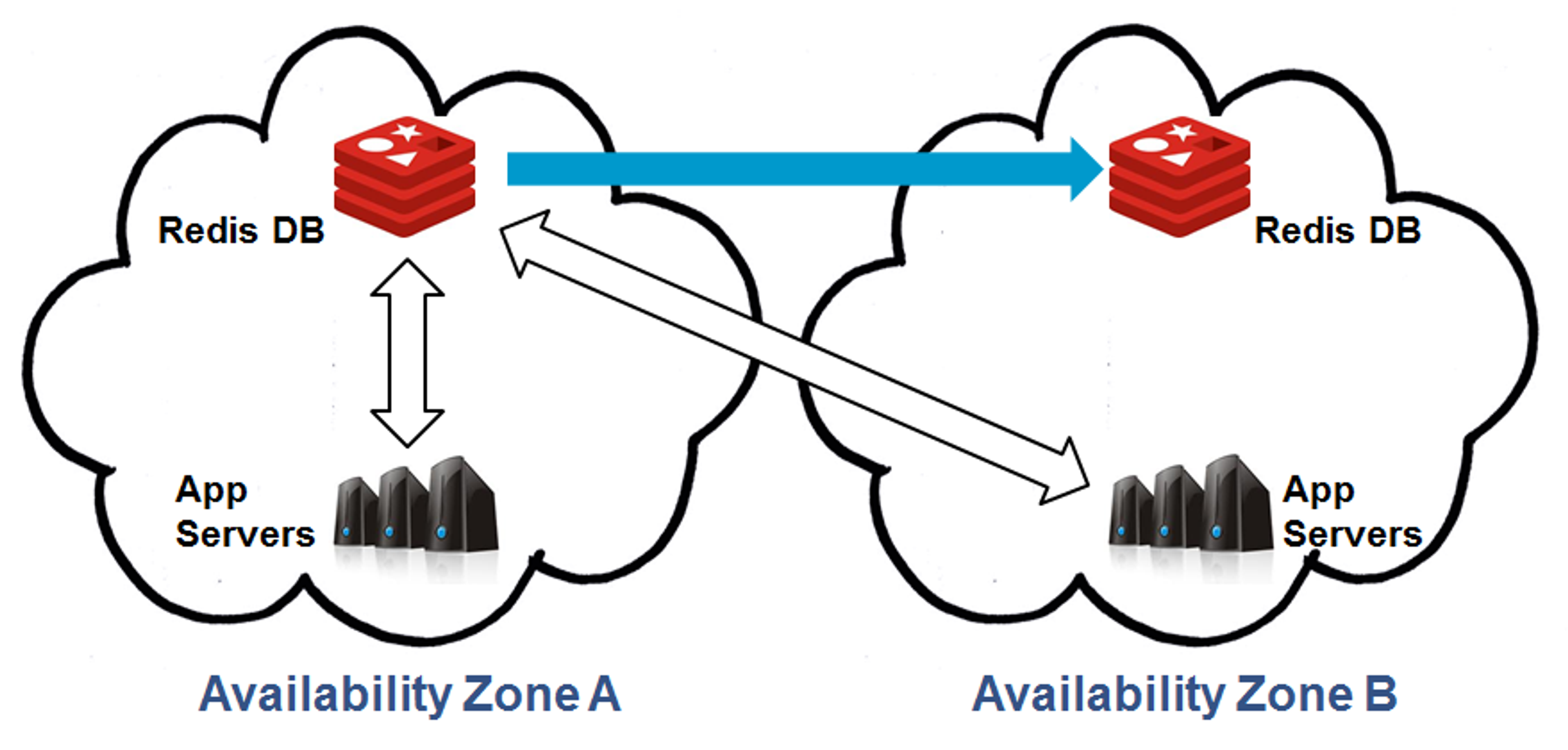
As can be seen, in normal state, the application’s instances either run from Zone A or from both A and B. The datastore, however, is only present in Zone A and is used to serve the application instances in both zones. That means that the datastore may become unavailable if Zone A fails, leaving the surviving application instances in Zone B without their data. In our Multi-AZ solution, the datastore is replicated from Zone A to Zone B, as shown here:
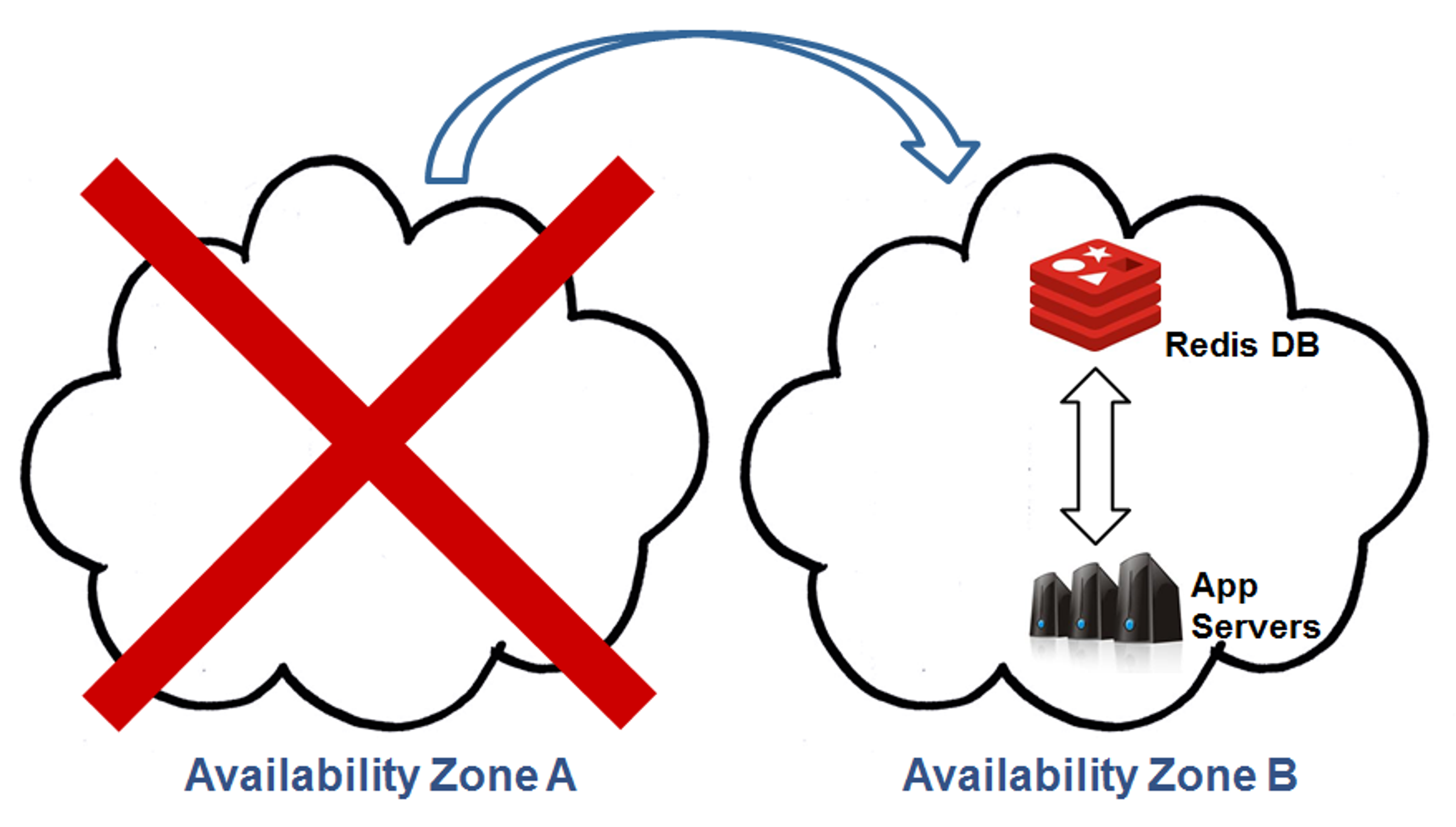
With our Multi-AZ replication, the active datastore remains in zone A. Zone B’s replica is only updated with changes and kept in standby mode as long as there are no zone failures. If and when Zone A fails, Zone B’s standby replica is automatically prompted to active state and the application is failed over to it, like so: This allows the application’s operation to continue uninterrupted despite a major failure event. The failover to Zone B’s datastore replica is entirely managed and carried out externally to your application so no code/configuration changes are needed, and by updating the datastore’s DNS records even its URL remains unchanged. The failed-over-to environment in Zone B will continue to serve the application’s traffic with only minimal and temporary, if any, performance degradation from renewing the connections to the datastore. At some later point in time, Zone A is likely to be recovered by the cloud infrastructure provider. According to our Multi-AZ solution, once Zone A is again available for use, it will be rebuilt to restore the Multi-AZ deployment in anticipation for the next failure. Typically, the application servers will be first to be spun up in the recovered zone, and will connect to the now-active datastore replica in Zone B. Similarly, no modifications are needed at the client side since the datastore retains its URL:
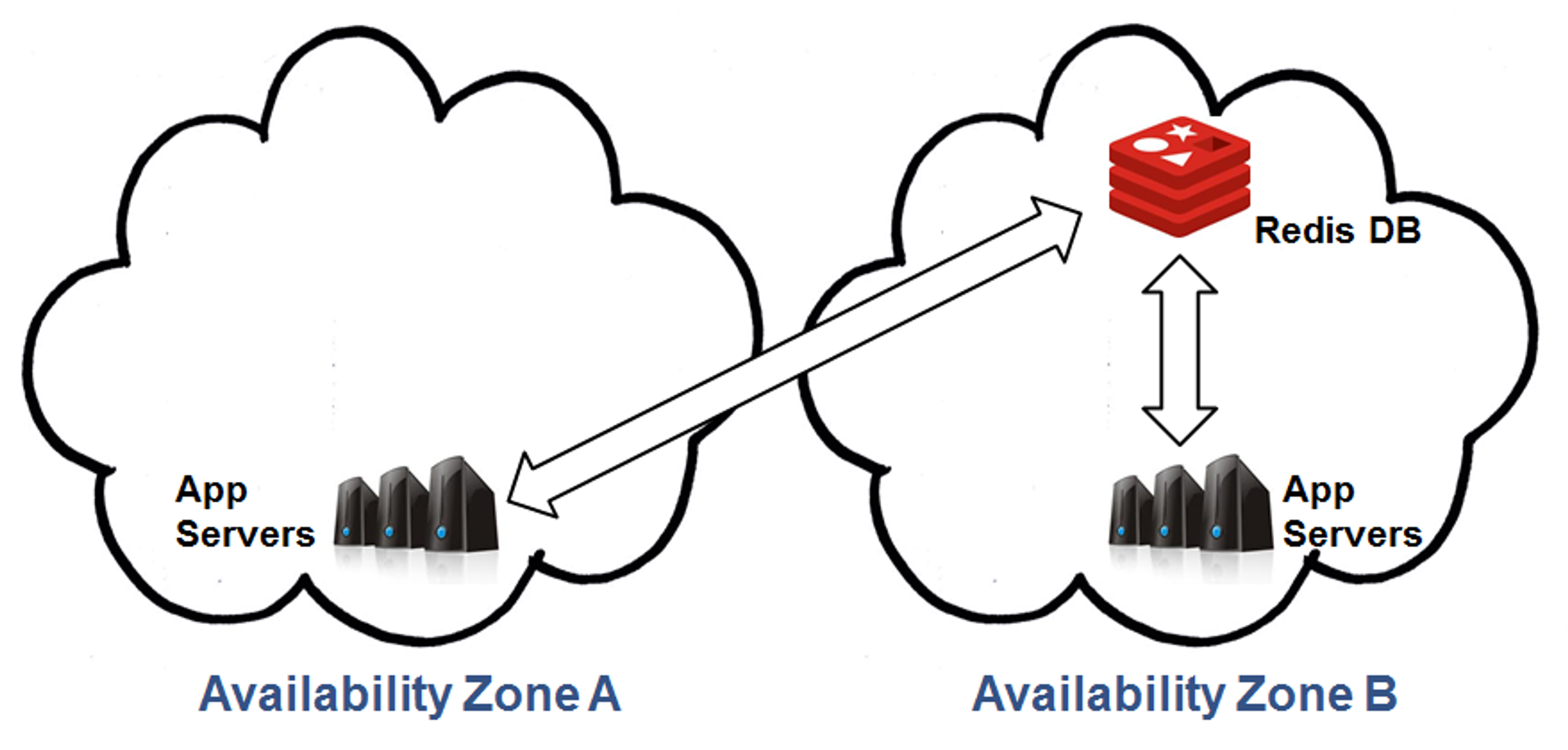
A little while later, the datastore’s new standby replica in Zone A will finish its synchronization from the active replica and the replication stream flow from Zone B to A will begin. At this stage, setup will have fully returned to its Multi-AZ, zone-failure-resilient state as depicted here:
Following are some of the challenges that the Garantia Data team had to tackle when we prepared our service to support multiple availability zones for Redis & Memcached:
- Distinguishing between run-of-the-mill network splits and real zone failures – as the former is much more common across zones, we developed a specialized gossip mechanism to correctly identify the situation and act appropriately. We also designed our service’s topology to make it easier to avoid splits during an actual zone failure scenario
- Ensuring data consistency during split conditions
- Replicating datastores over congested inter-zone network links
- Keeping gaps between replicated datasets to a minimum
All the goodness of this hard work is now available to you with the same simple setup and ease-of-use as any other of our plans. And it carries the assurance that the next time an availability-zone-crippling disaster hits, your datasets will be safely tucked away out of harm’s way while remaining fully functional. To start using Multiple Availability Zones with your Redis & Memcached Clouds, just select the “Multi-AZ Deployment” checkbox the next time you launch a new Redis DB or Memcached Bucket. Our Multiple Availability Zones plans for datasets are available today at AWS’s us-east data region, and we intend to add plans for more regions, clouds & providers in the coming months.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.