
Everybody knows you should always use protection, or things can get pretty ugly fast. In the Cloud world, this translates to our in-memory datastore’s fault resilience, which effectively determines if and how it will withstand and recover from failure scenarios.
While for some applications, the loss of some or all data is an acceptable mode of operation, for most applications data persistence and high availability are hard requirements. We’ve touched on this in previous posts, but given its importance, we want to share more about maintaining the high availability (HA) of in-memory datastores in Cloud environments.
With technologies, such as Redis, it is possible to use out-of-the-box tools to support such goals. These ingrained abilities provide a good starting point, but are usually not quite enough, especially when employed in Cloud environments.
Redis, for example, comes equipped with built-in replication, but can still experience undesirable stability and performance effects when used over a congested network. Redis’ Sentinal tackles the HA challenge but has yet to stabilize and mature as well as be integrated with most client libraries.
Redis’ integrated data persistence mechanisms (namely snapshots and Append Only Files) are very dependable but may carry a serious performance penalty when used with cloud storage. Unlike Redis, Memcached offers no HA functionality by itself. Two approaches prevail when augmenting it to achieve high-availability: repcached or client-side replication. There are, however, downsides to each of these approaches, rendering them inapplicable for certain application requirements.
Repcached’s major handicaps are its inability to scale and its exclusive availability for Memcached v1.2.x, and client-side writes’ multiplicity can become a major performance damper. In order to have a real-world production-grade setup deployed on cloud compute resources you need to season it with extra availability auspices.
Replication & Auto-Failover
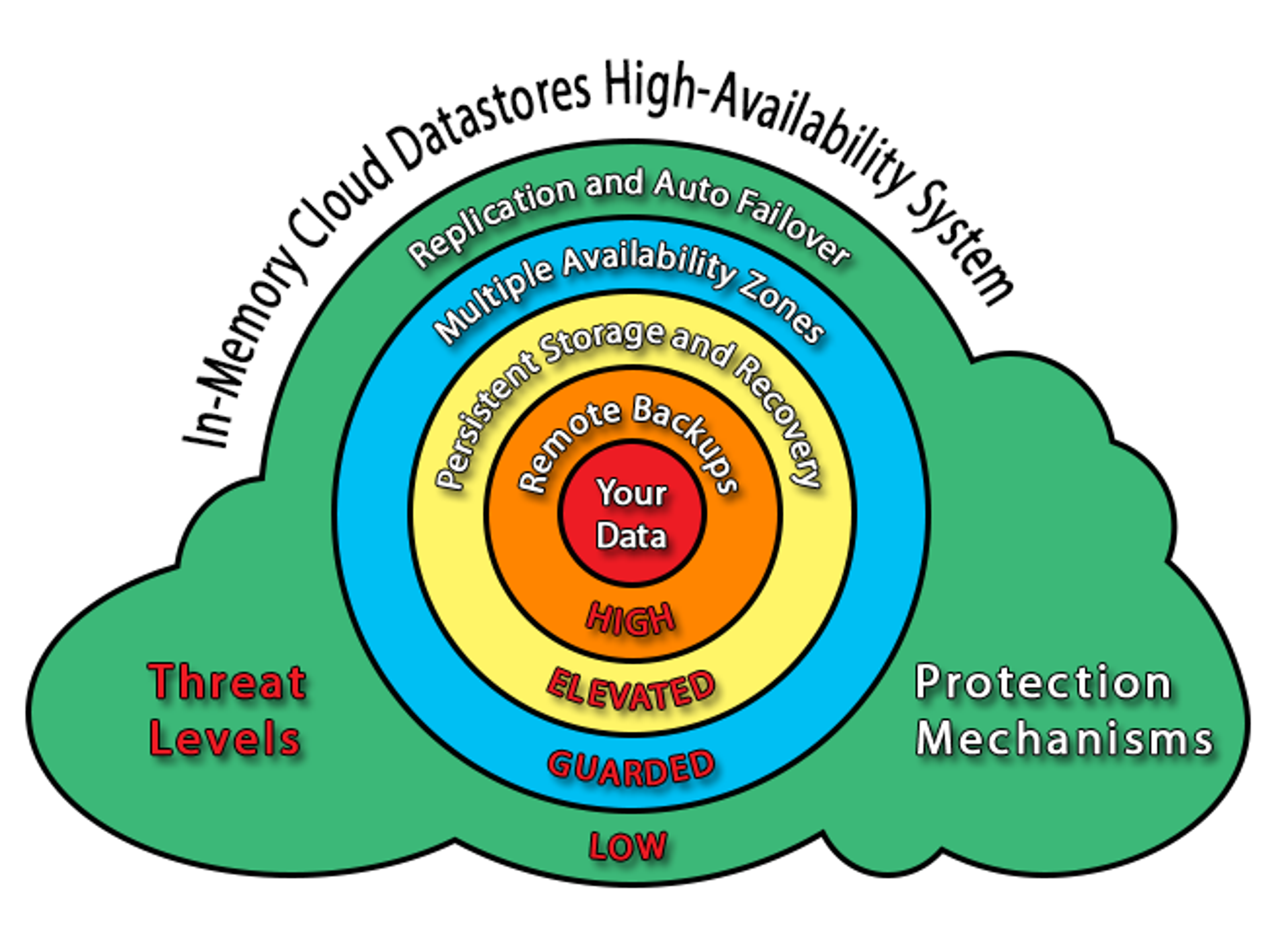
Our Redis & Memcached Cloud services take into account multiple failure scenarios and provide availability mechanisms to handle them all. The simplest form of threat to availability that we eliminate is the failure of a single node (i.e. cloud server instance).
The low-level blocks in the overall cloud environment, nodes can and do fail on a regular basis. We protect our databases from such failures by replicating them on two or more nodes, so that when a node dies there is at least one replica available on a different node. Our service automatically detects such failures, transparently promotes a replica for use and provisions a replacement to the failed node.
For our regular plans we offer choice between two modes of replication: in-memory and to-disk. When using in-memory replication, replicas of the database are kept loaded and ready for immediate use in the main memory of the standby nodes. Failing over to an in-memory replica is nearly instantaneous, and in most cases the application does not discern any noticeable effects during or after the switch.
We recommend using in-memory replication for critical applications, but RAM resources are significantly more expensive than disk space. Therefore, we also support using disk-based replication at no extra cost. We achieve disk-based replication by storing the database on the local storage of the active node and copying it to the local storage of an idle backup node. When failover is triggered by the service, the backup node loads the disk-stored database and takes the place of the now-inactive replica. Of course, both response and access times to storage are inherently higher by orders of magnitude than those required to access the memory, so failover duration is higher as the probability of unsynchronized data loss.
Multiple Availability Zones
Some of the plans we offer can survive an entire availability zone’s failure and still continue normal operation with only a minimal amount of disruption. These instances, created using Multi-AZ plans, have their replicas kept in different availability zones. If an entire zone fails, our automatic fail over mechanism switches to serve the data from the remaining replica. Due to performance considerations, disk-based replication is not offered for our Multi-AZ plans and only in-memory replication is supported.
Data Persistence & Auto-Recovery
Another, rarer but still probable, failure scenario is one in which both replicas are affected. In such cases, mere replication won’t help because there no survivors left. We deal with such events by using native data persistence mechanisms, namely Append Only Files and snapshots, on top of persistent cloud storage services such as AWS’s EBS. We use a cluster recovery tool to rebuild damaged setups and bootstrap datasets from storage when such spectacular failures occur.
Backups
Last on the list of possible failures is the doomsday scenario in which a significant portion of the cloud – such as an entire datacenter (a.k.a. zone) or even multiple datacenters (a.k.a. data region) – disintegrates into thin air. Such outages were experienced no less than 4 times last year by the market’s leading cloud provider, AWS.
These meltdowns are impossible to countermeasure (at least within the affected region of the cloud), but our service protects your databases from them by maintaining automated daily and on-demand backups to remote storage (i.e. an S3 or FTP server). These enable our cluster recovery tool to restore the contents of your ravaged databases after it completes the recovery and setup of infrastructure resources.
Extreme Sharding
Based on their plan and needs, datasets that are hosted in our service are sharded behind the scenes to enable near-infinite scalability.
A welcome byproduct of this design is a positive gain in the overall availability of the database:
- The risk of the entire dataset failing is reduced due to the distribution of shards across multiple nodes.
- When a node fails and takes down a shard with it, potential data loss is minimized because of the relatively smaller address space and dataset of the shard.
- Overall recovery time of the database, even in the most extreme cases, is shorter in comparison to an unsharded database, since the sharded database is recovered by multiple nodes in parallel.
Conclusion
Ensuring the availability of in-memory datastores in the turbulent environment of modern compute clouds is no small task. Setting up a resilient configuration that can recover from failures to maintain the application’s ongoing operation is anything but a once-off effort and requires constant monitoring and maintenance.
While the Do-It-Yourself approach may suit some, our service provides (among other benefits) high availability with the click of a button for those who want to use an in-memory datastore rather than manage it.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.