Blog
Optimizing Redis’ Default Compiler Flags
Redis and Intel teamed up to find out whether applying more aggressive optimization options would improve overall Redis baseline performance. Our conclusion: Yes! By changing the compiler behavior, we measured a 5.13% boost overall and more in some cases.
Redis assumes the default GCC compiler on supported operating system distributions for reasons of portability and ease of use. The build compiler flags, present since the early stages of the project, remained quite conservative across the years, with -O2 as the default optimization level. These flags have worked well. They provide consistent results and good performance without significantly increasing the compilation time or code size of Redis server binaries. Nobody wants to spend a lot of time on compilation!
However, could we do a bit better? We are optimization specialists. We always ask this question!
In this post, we describe our analysis of the impact on Redis performance by changing compiler versions (GCC 9.4, GCC 11, and Clang-14) and compiler flag optimizations. We evaluated the performance impact of compilers and flags using performance automation, as we discussed in Introducing the Redis/Intel Benchmarks Specification for Performance Testing, Profiling, and Analysis. As a result of this work, we updated the default Redis compiler flags because they ensure better performance.
A review of compilers and compiler flags
Let’s compare two popular open source compilers, GNU Compiler (GCC) and Clang/LLVM.
GCC
GCC is a classic optimizing compiler. It is well-known as a C/C++ compiler but also has front ends for other languages, including Fortran, Objective-C, and Java. GCC is a key component of the GNU toolchain, and it plays an important role in Linux kernel development, along with make, glibc, gdb, and so on.
GCC is the default compiler of many Unix-like operating systems, including most Linux distributions. As an open-source product, GCC is developed by many people and organizations, and Intel is among them.
For our experiment, we chose two GCC versions:
- GCC 9.4.0: the default version in Ubuntu 20.04
- GCC 11: the latest available major version on Ubuntu 20.04 at the time of testing
Clang
Clang/LLVM, or simply the Clang compiler, is a combination of the Clang front-end and LLVM backend. Clang translates source code to LLVM byte code, and the LLVM framework performs the code generation and optimizations. Clang is GCC compatible and positioned as fast compiling, low-memory using, and extremely user-friendly with expressive diagnostics. Currently, Clang is the default compiler for Google Chrome, FreeBSD, and Apple macOS.
Much of the power of Clang is in the LLVM community, as many IT companies and individual developers are involved in it. In particular, Intel developers are active community contributors. The Intel ICX compiler is based on an LLVM backend, and Intel contributes enhancements to LLVM back to the community.
For our performance testing, we chose the latest available major version at the moment of experiment, Clang 14.
Compiler flags
Compilers have hundreds of configuration settings and flags that developers can toggle to control how the compiler runs and the code it generates. These affect performance optimizations, code size, error checking, and the diagnostic information emitted. While it’s common to copy and paste the default settings, adjusting them can make a difference. A big difference.
-O2 is a basic performance optimization that increases both performance and compile time. -O2 optimizes work with strings (-foptimize-strlen), includes simple loop optimizations (for example, -floops-align and -ffinite-loops), and partial inlining (-fpartial-inlining). This optimization level includes vectorization with a very-cheap cost model for loops and basic block on trees (very-cheap allows vectorization if the vector code can entirely replace the scalar code that is being vectorized). More information about cost models and other optimization flags inside -O2 can be found in the compiler’s optimization flags list.
-O2 has been the default optimization level for Redis source code. We use -O2 as our baseline, traditionally. In the project, we compared it with more aggressive optimization options.
-O3 is a more aggressive compiler optimization flag. It includes all the -O2 optimization behaviors as well as additional loop optimizations, such as loop unrolling (-floop-unroll-and-jam). It also splits loops if one part is always true and the other false (-fsplit-loops). In -O3, the very-cheap cost model is replaced by a more accurate, dynamic cost model with additional runtime checks. With this change, the whole application can be faster because the compiler defines which parts of code are slow (e.g. slow scalar loops) and optimizes it, so parts that were good become better.
These -O3 flags are not limited to just these options. For a full list, see the Compiler Options That Control Optimization.
There are a few things to keep in mind:
- With the -O3 flag, the compiler performs a set of transformations that should lead to performance increase, but it is not 100% guaranteed. The results depend on the specific code and input data. (Doesn’t everything?)
- -O3 is the default compilation level for building some of Redis’s dependency projects.
The -flto flag stands for link time optimization (LTO). This optimization is performed by the compiler at the point where it links application code. Without this option, each file is optimized separately and then linked together. With LTO, files are concatenated first, and optimizations are applied second; that can improve optimization quality.
This option can be really helpful when application files have a lot of connections to each other. For example, let’s say you define a function in a file. You may or may not use that function in other files. The compiler’s linker uses this knowledge as it builds the executable. The used functions are inlined (which makes the application run faster); unused functions are excluded from the resulting binary file.
LTO helps to eliminate dead code and conditions that are always TRUE or FALSE (“Is chocolate good? Duh!”). Global variables used in code are also inlined when you use the LTO compile option.
All such changes positively affect the execution time of the built binary file. Or in English: We make Redis run faster.
Experiment methodology
We conducted our experiments using the performance automation framework, which included 50 test cases. We aimed to achieve good coverage across Redis usage models and to ensure that we do not adversely affect the performance of important use cases.
Using the automation framework, the joint team at Redis and Intel created multiple build variants to represent the combinations of compilers (gcc v9.4, gcc v11, and clang v14) and compiler flags to evaluate. In addition to Redis, we also experimented with modifying compilers and flags for Redis dependencies (for example, jemalloc and lua) by using the REDIS_FLAGS or just FLAGS options during the build stage. In total, these variations gave us 24 different binaries or build variants.
To estimate the effectiveness of each build variant, we run all 50 test cases with the Redis server, built by a particular build variant (e.g Clang 14 + “O3”). For these tests, we calculated the geometric mean (or just geomean) on repeated runs for three times (everyone loves reproducible results!) and calculated the average value of three runs. This one final number, described in operations per second (ops/sec), indicates the performance of a build configuration. Providing these steps for each pair compiler and options, we got a set of numbers to compare. We show the percentage of the difference between them and the baseline below.
We performed these tests on four Intel Xeon Platinum 8360Y processor-based servers.

Figure 1: Hardware set
Our findings… and what they mean
Figure 2 provides a summary of our experimental results. As a baseline, we compiled Redis using GCC 9.4 with default optimization flags. We judged success based on ops/sec on average across all runs and in geomen by 50 test cases, given as redis-server built by that or another build variant. More operations per second are better, suggesting that a Redis server is faster.
Overall, GCC 9.4 O3 + flto provided the best performance of 5.19% (with dependencies included) and 5.13% (without dependencies) geomean speedup versus the baseline.
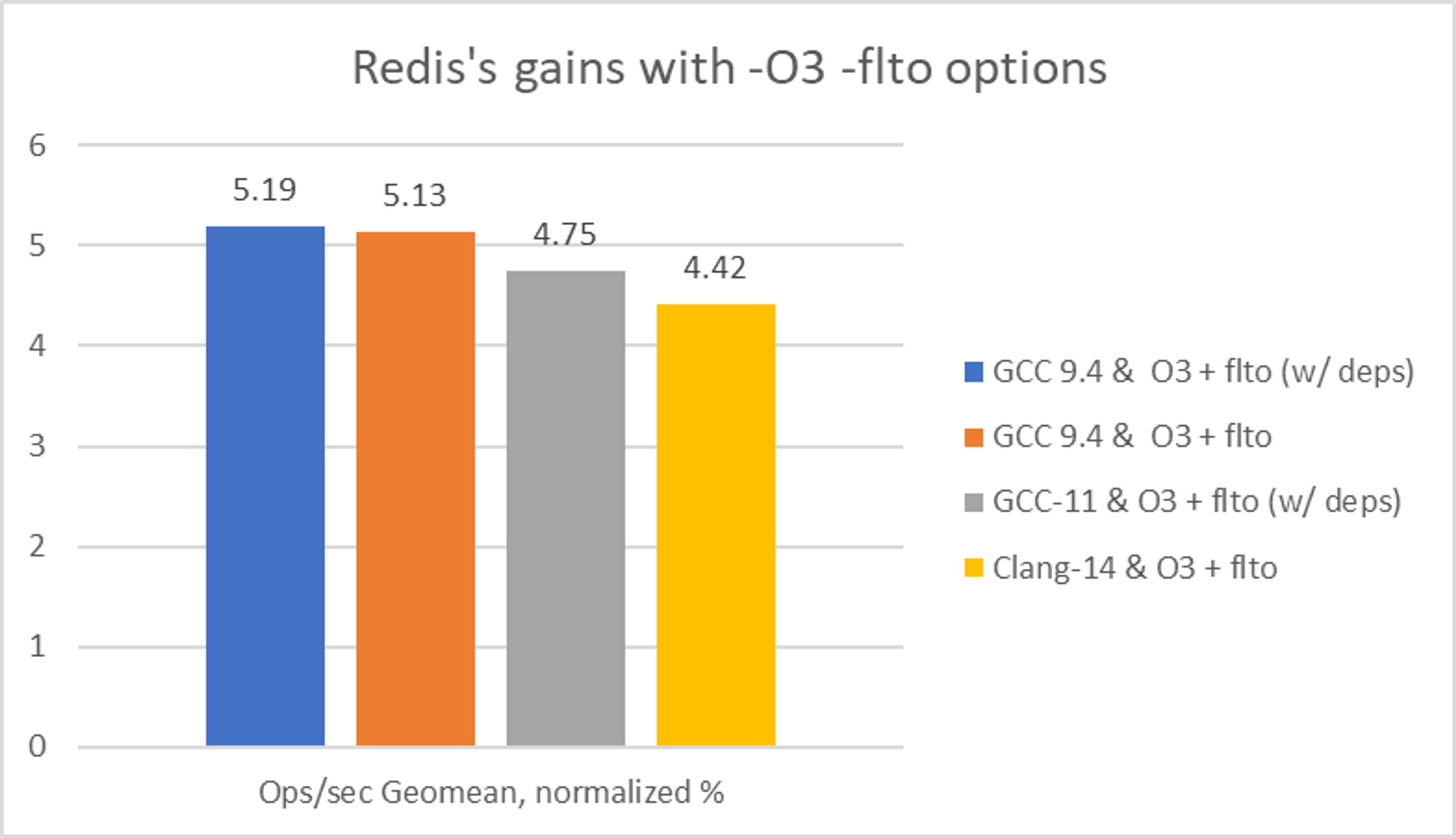
Figure 2: Geomean of 50 use cases normalized to baseline (GCC 9.4 with default optimization flags)
The impact of the compiler and flags was much more pronounced in some use cases (see figure 3). For instance, with GCC 9.4 -O3 -flto, there is no performance degradation versus the baseline, and four tests improved by more than 10%.
The results vary quite a bit, in other words – which shows that changing the Redis optimization flags can make a significant performance difference.
In other configurations, some tests showed worse performance than the baseline. Yet some were boosted more than 20% over the baseline. This is because the O3 flag enables a number of aggressive optimization techniques to improve efficiency. The result is that the compiler can reorder instructions and make other changes to the code. While these optimizations can often be beneficial, they can also cause the code to run more slowly in some cases, particularly if they introduce additional overhead or they make the code less cache-friendly.
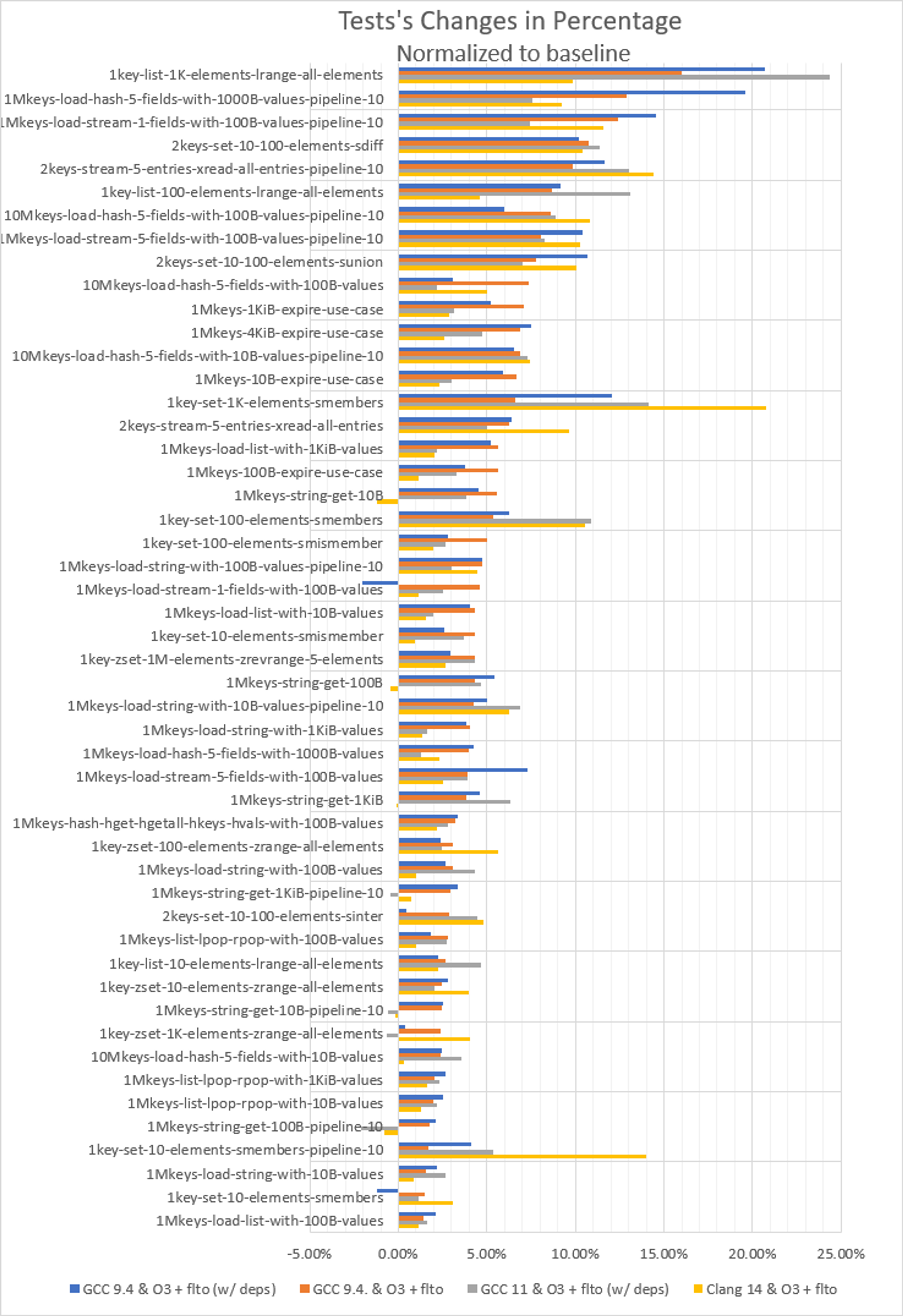
Figure 3. Tests’ changes percentage distribution across 50 use cases normalized to baseline (GCC 9.4 with default optimization flags). For each test, we captured the minimum result observed across three test runs.
In short, changing those flags makes a difference in the execution speed of OSS Redis.
Based on the results of this experiment, the Redis core team approved our proposal to update the default flags to -O3 -flto (PR 11207). This configuration showed a 5.13% boost in geomean across all measured use cases and zero tests with decreased performance.
Our conclusions and our plans
Our work on tuning the compiler does not end here. We have additional opportunities to make Redis run (even) faster. For example:
- Profile guided optimizations (PGO): With PGO, the compiler collects runtime profiles from different executions. The runtime profiles include information such as statistics about branches taken versus not taken; loop counts; code block frequency of execution; and so on. Using this runtime information allows the compiler to generate better code for the common runtime use cases.
- Security: Recent compiler versions have flags that generate more secure code. We expect to conduct experiments about the best way to incorporate these For example:
- Control-flow Enforcement Technology (CET) protection defends your program from certain attacks that exploit vulnerabilities
- Address Sanitizer can prevent exploits based on out-of-bounds, control flow, and other malicious exploits.
- Intel Compiler: Intel is using the lessons we’ve gathered from these experiments and feeding them to the Intel Compiler development teams. Also, a few improvements were implemented in Redis to support ICC compilation (e.g. PR 10708 and PR 10675), and we are working together with Redis on continuous improvement.
Want to see how all of this shows up in the software? Try Redis for free to explore its myriad benefits.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.