
When US-EAST-1 goes haywire, everyone feels it. Dashboards light up. Queues back up. Engineers open incident channels and brace for a long night.
For many teams, the problem isn’t just the outage itself. It’s what happens after: Failovers that take longer than expected, caches that go out of sync, and data that doesn’t look quite right.
That was the story for teams running Amazon ElastiCache during the most recent regional disruption. A service built for speed and scale struggled to stay consistent when the region it depended on went offline.
Outages like that expose the difference between managed availability and true resilience. Some systems recover. Others never go down in the first place.
What high availability really means
Every vendor talks about uptime, but uptime alone doesn’t tell the whole story. What matters is how quickly a system can fail over, how much data it preserves during that process, and how much intervention is required to get back to normal.
In many cache and database systems, failover still happens in tens of seconds or minutes. Those recovery windows might look small on paper but can disrupt real-time apps, queues, and user sessions across entire regions.
Redis Cloud was built to change that. Its failovers complete in single-digit seconds, even under heavy load. The difference comes from automation and intelligent routing through the Redis Cloud proxy, which seamlessly manages shard transitions behind the scenes. In most cases, clients don’t need to reconnect at all.
If an entire region becomes unavailable, client connections need to shift to the next available region. (More on that in a bit.) But for everyday operations such as planned maintenance, shard replacement, or shard failover, apps keep running without interruption or code changes.
Availability, in this context, means continuity. Redis Cloud is designed not just to resume quickly but to keep serving requests the entire time.
Durability and data integrity under pressure
High availability keeps your application online. Durability ensures your data survives whatever caused the failover in the first place.
Redis Cloud uses Append-Only File (AOF) persistence and RDB snapshotting to maintain durability during failure and recovery. AOF records every write operation as it happens, creating a continuous log that can be replayed instantly when an instance restarts. Combined with in-memory replication, this approach minimizes the risk of lost data even if a node fails entirely.
ElastiCache, by contrast, relies only on RDB snapshot-based durability. Snapshots occur at intervals, typically once per hour, which can leave up to 60 minutes of writes unprotected. During a regional disruption or hardware failure, that gap can translate into stale or missing data when systems come back online.
Some workloads can tolerate this. If Redis is used only as a read-through cache for data stored elsewhere, persistence may not be essential for correctness. But it still matters for speed. Without persistence, a restarted cache must repopulate from its source, creating a surge of traffic that can overwhelm downstream databases and extend recovery times. With AOF and RDB, Redis Cloud restarts warm, serving requests immediately and allowing dependent systems to stabilize faster.
Many modern Redis deployments also store ephemeral, real-time data such as sessions, queues, state, and buffers that do not exist anywhere else. In those cases, durability makes Redis dependable for maintaining application continuity.
For those apps, and others that handle real-time data, data gaps aren’t acceptable. High availability and data durability have to work together.
The architecture behind real HA
Redis Cloud delivers high availability in multiple layers, starting with automated local failover that keeps apps running through shard-level disruptions. Redis Cloud manages this process transparently, rerouting traffic within a region in single-digit seconds without requiring client reconnection. For most workloads, this level of HA already exceeds what ElastiCache provides.
Side-by-side comparison of Redis and node-based ElastiCache for standard HA:
| Redis Cloud High availability | ElastiCache High availability |
|---|---|
| Automatic local failover handled by the Redis Cloud proxy | Failover via DNS update; client must reconnect |
| Single-digit-second failover under load | 10s of seconds to minutes, depending on DNS TTL, propagation and health checks |
| No disruption during failover | Failover depends on connection timeout and retry logic (2-6 second disruption) |
| AOF and RDB persistence available for durability | Snapshot-only persistence (possible data loss between backups) |
For mission-critical applications that demand continuous operation across regions, Redis Cloud also offers Active-Active replication. This configuration uses Conflict-free Replicated Data Types (CRDTs) to keep multiple writable regions synchronized at all times. Even if an entire region becomes unavailable, the others continue processing writes with full consistency while connectivity is restored.
Active-Active provides the highest level of HA Redis Cloud can offer, but it isn’t required for every workload. It involves additional network coordination and inter-region data transfer, which are factors to consider when designing for global continuity.
By contrast, ElastiCache Global Datastore uses an Active-Passive approach: One writable primary and up to two read-only replicas. Failover requires manually promoting a replica, reestablishing DNS routes, and manually repopulating and reattaching the region on recovery, each step adding delay and risk.
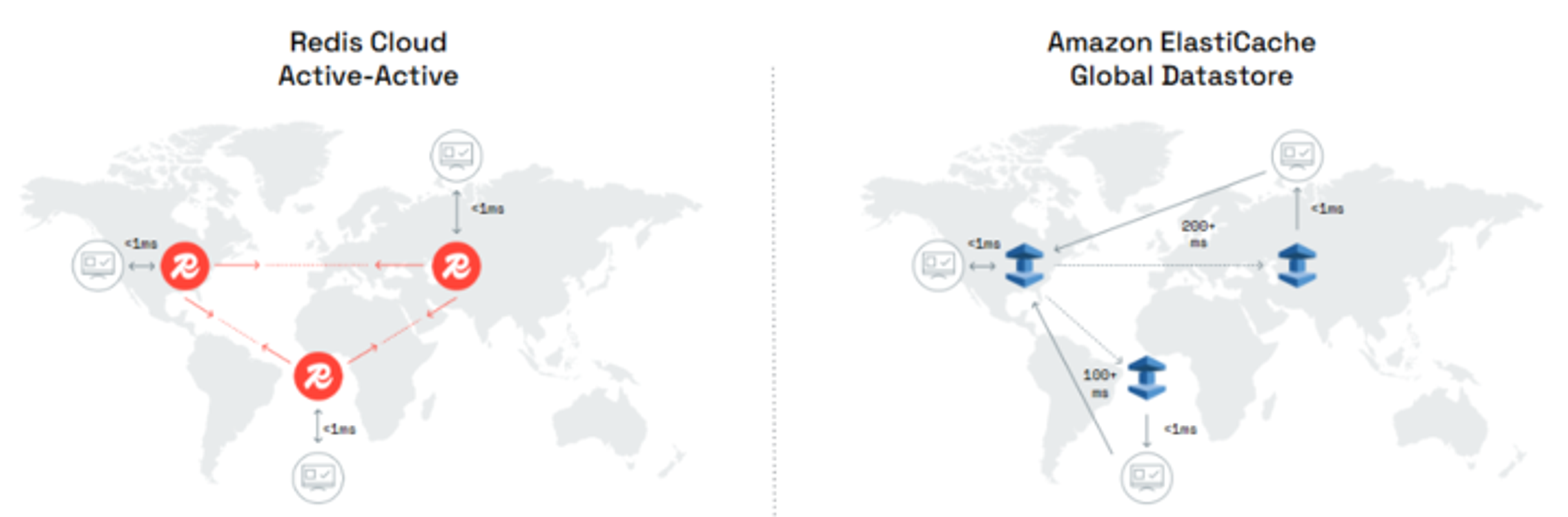
Active-Active systems keep every region available, so operations continue without failover. Active-Passive systems depend on a single writable primary. When it fails, replicas must be promoted.
Side-by-side comparison of Redis Active-Active and ElastiCache global datastore:
| Redis Cloud Active-Active | ElastiCache Global Datastore |
|---|---|
| Local latency on reads and writes | Higher write latency |
| Write to local region | Write to master only |
| Instant “failover” (all nodes always active) | Manual failover |
| Automatic re-sync after regional recovery | Manual rebuild or re-association required for recovered regions |
| Five-nines (99.999%) uptime SLA | Four-nines (99.99%) uptime SLA |
| Strong eventual consistency | Eventual consistency |
| Read your own writes | Stale reads |
| Built-in conflict resolution | No defined conflict resolution |
| Up to 10 regions | Up to 3 regions |
Consistency and split-brain protection
Redis Cloud’s Active-Active architecture is built on CRDTs, which give it natural split-brain resilience.
In a temporary network partition between regions:
- Each region continues to accept reads and writes locally.
- All writes are recorded as CRDT operations with metadata tracking.
- When connectivity is restored, Redis Cloud automatically merges changes deterministically, making sure all replicas converge to the same consistent state.
- There’s no data loss and no manual conflict resolution.
This design means that even if two regions operate independently for a period, they can reconcile safely once the partition heals. Apps don’t need custom reconciliation logic or manual clean-up.
ElastiCache Global Datastore, by contrast, doesn’t use CRDTs or bi-directional replication. It’s a single-writer, asynchronous replication model: one primary region handles writes, while secondary regions are read-only. If the primary region becomes unreachable, it allows a secondary region to be manually promoted to become the new primary. The original primary is effectively abandoned; it remains isolated and any writes that occurred during the partition are lost. Replication doesn’t resume automatically, and the old primary must be manually recovered and re-added to a new global datastore configuration.
So, while Redis Cloud treats partitions as temporary states that self-heal, Global Datastore treats them as failures that require human intervention.
Always available, by design
When US-EAST-1 goes haywire, caching might seem like the least of your problems. But it quickly becomes clear how much everything depends on it. Authentication tokens, cached database queries, message queues, user sessions, and API responses often live in cache layers for speed and scale.
When ElastiCache stalls, those dependencies start to surface. Services that look healthy on their own begin to slow or fail because the data they rely on isn’t being refreshed.
Failing over to another region doesn’t solve it, because ElastiCache replicas remain read-only until manually promoted, and any data written to the isolated primary after the partition is permanently lost.
To get caching back, teams have to promote a secondary, update DNS records, reconfigure connection strings, restart affected apps, and verify data consistency before resuming normal operations. Any writes that occurred in the isolated US-EAST-1 region are lost.
When US-EAST-1 finally comes back online, there’s another decision to make: rebuild ElastiCache in its original location or keep operating from the failover region. Re-establishing replication and confirming data consistency adds another long list of tasks to the recovery effort. For a moderately complex application with dozens of microservices, this can mean hours of coordinated recovery work across multiple teams.
With Redis Cloud, the same event is handled automatically. If shards or nodes fail, the failure is detected and reroutes traffic to a newly promoted primary in seconds. If the entire region is offline, Active-Active databases in other regions continue serving reads and writes without interruption. When the region recovers, Redis automatically synchronizes changes across all regions using CRDT-based replication, ensuring data integrity without manual steps.
When a region goes dark, you already have enough problems to recover from. Redis Cloud makes sure caching isn’t one of them.
Next steps
Ready to migrate from ElastiCache? See our guide on three proven migration strategies.
Read more about multi-cloud deployments to protect against cloud outages and lock-in: Redis vs. Valkey for multi-cloud deployments
Or book a meeting and talk to a Redis expert about your high availability requirements.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.