Data denormalization
Learn about denormalization strategies
The data in the source database is often normalized. This means that columns can't have composite values (such as arrays) and relationships between entities are expressed as mappings of primary keys to foreign keys between different tables. Normalized data models reduce redundancy and improve data integrity for write queries but this comes at the expense of speed. A Redis cache, on the other hand, is focused on making read queries fast, so RDI provides data denormalization to help with this.
The supported denormalization techniques are joining
one-to-one relationships (using merge) and
joining one-to-many relationships (using nesting),
both described below.
redis.lookup
transformation is not a supported way to denormalize data that RDI ingests. RDI
can't guarantee that a key written by one job is present or up to date when another
job looks it up, so lookups against pipeline-populated data can miss or return stale
values. Use the techniques on this page instead. See
Reading Redis data with redis.lookup
for details.Joining one-to-one relationships
You can join one-to-one relationships by making more than one job to write to the same Redis key.
First, you must configure the parent entity to use merge as the on_update strategy.
# jobs/customers.yaml
source:
table: customers
output:
- uses: redis.write
with:
data_type: json
on_update: merge
Then, you can configure the child entity to write to the same Redis key as the parent entity. You can do this by using the key attribute in the with block of the job, as shown in this example:
# jobs/addresses.yaml
source:
table: addresses
transform:
- uses: add_field
with:
field: customer_address
language: jmespath
# You can use the following JMESPath expression to create a JSON object and combine the address fields into a single object.
expression: |
{
"street": street,
"city": city,
"state": state,
"zip": zip
}
output:
- uses: redis.write
with:
data_type: json
# We specify the key to write to the same key as the parent entity.
key:
expression: concat(['customers:id:', customer_id])
language: jmespath
on_update: merge
mapping:
# You can specify one or more fields to write to the parent entity.
- customer_address: customer_address
The joined data will look like this in Redis:
{
"id": "1",
"first_name": "John",
"last_name": "Doe",
"customer_address": {
"street": "123 Main St",
"city": "Anytown",
"state": "CA",
"zip": "12345"
}
}
merge as the on_update strategy for all jobs targeting the same key, the entire parent record in Redis will be overwritten whenever any related record in the source database is updated. This will result in the loss of values written by other jobs.When using this approach, you must ensure that the key expression in the child job matches the key expression in the parent job. If you use a different key expression, the child data will not be written to the same Redis key as the parent data.
In the example above, the addresses job uses the default key pattern to write to the same Redis key as the customers job. You can find more information about the default key pattern here.
You can also use custom keys for the parent entity, as long as you use the same key for all jobs that write to the same Redis key.
Joining one-to-many relationships
To join one-to-many relationships, you can use the Nesting strategy.
With this, the parent object (the "one") is represented as a JSON document with the children (the "many") nested inside it as a JSON map attribute. The diagram below shows a nesting with the child objects in a map called InvoiceLineItems:
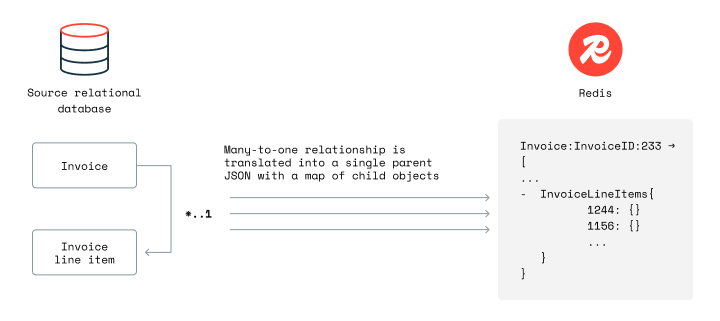
To configure normalization, you must first configure the parent entity to use JSON as the target data type. Add data_type: json to the parent job as shown in the example below:
# jobs/invoice.yaml
source:
schema: public
table: Invoice
output:
- uses: redis.write
with:
# Setting the data type to json ensures that the parent object will be created in a way that supports nesting.
data_type: json
# Important: do not set a custom key for the parent entity.
# When nesting the child object under the parent, the parent key is automatically calculated based on
# the parent table name and the parent key field and if a custom key is set, it will cause a mismatch
# between the key used to write the parent and the key used to write the child.
After you have configured the parent entity, you can then configure the child entities to be nested under it, based on their relation type. To do this, use the nest block, as shown in this example:
# jobs/invoice_line.yaml
source:
schema: public
table: InvoiceLine
output:
- uses: redis.write
with:
nest: # cannot co-exist with other parameters such as 'key'
parent:
# schema: public
table: Invoice
nesting_key: InvoiceLineId # the unique key in the composite structure under which the child data will be stored
parent_key: InvoiceId
child_key: InvoiceId # optional, if different from parent_key
path: $.InvoiceLineItems # path must start from document root ($)
structure: map # only map supported for now
on_update: merge # only merge supported for now
data_type: json # only json supported for now
The job has a with section under output that includes the nest block.
The job must include the following attributes in the nest block:
parent: This specifies the config of the parent entities. You only need to supply the parenttablename. Note that this attribute refers to a Redis key that will be added to the target database, not to a table you can access from the pipeline. See Using nesting below for the format of the key that is generated.nesting_key: The unique key of each child entry in the JSON map that will be created under the path.parent_key: The field in the parent entity that stores the unique ID (foreign key) of the parent entity. This can't be a composite key.child_key: The field in the child entity that stores the unique ID (foreign key) to the parent entity. You only need to add this attribute if the name of the child's foreign key field is different from the parent's. This can't be a composite key.path: The JSONPath for the map where you want to store the child entities. The path must start with the$character, which denotes the document root.structure: (Optional) The type of JSON nesting structure for the child entities. Currently, only a JSON map is supported so if you supply this attribute then the value must bemap.
Using nesting
There are several important things to note when you use nesting:
-
When you specify
nestin the job, you must also set thedata_typeattribute tojsonand theon_updateattribute tomergein the surroundingoutputblock. -
Key expressions are not supported for the
nestoutput blocks. The parent key is always calculated using the following template:<nest.parent.table>:<nest.parent_key>:<nest.parent_key.value | nest.child_key.value>For example:
Invoice:InvoiceId:1 -
If you specify
expirein thenestoutput block then this will set the expiration on the parent object. -
You can only use one level of nesting.
-
If you are using PostgreSQL then you must make the following change for all child tables that you want to nest:
ALTER TABLE <TABLE_NAME> REPLICA IDENTITY FULL;This configuration affects the information written to the write-ahead log (WAL) and whether it is available for RDI to capture. By default, PostgreSQL only records modified fields in the log, which means that it might omit the
parent_key. This can cause incorrect updates to the Redis key in the destination database. See the Debezium PostgreSQL Connector Documentation for more information about this. -
Prior to RDI v1.12.1, there is a known limitation if you change the foreign key of a child object. In that scenario, the child object will be added to the new parent, but the old parent will not be updated.