Blog
Active-active architecture: How a different system configuration can unlock new levels of reliability

An active-active architecture is a system configuration in which multiple identical nodes are simultaneously active and serve requests concurrently. Instead of relying on a single, primary node, all nodes in an active-active architecture run in parallel, sharing the workload and boosting reliability.
Active-active architecture configurations are one of the core ways enterprises meet scalability needs. Users increasingly need applications that can remain performant no matter where the user is connecting from and no matter the level of traffic the application is facing.
An active-active architecture also provides built-in redundancy. If one node fails, the remaining nodes continue to serve traffic, ensuring the application remains available without disruption. This design ensures that enterprises don’t have to be perfect, and that nodes can fail without users actually feeling the consequences.
To build and sustain this design, active-active setups typically require load balancing to distribute incoming requests across all active nodes and data replication to keep each node’s data in sync. Providers like Redis and MongoDB can simplify this sometimes complex setup, making it easier to implement and maintain.
What is active-active architecture?
In a traditional system, known as active-passive or standby, only one node handles requests, and the secondary node waits to take over if the primary one fails. In contrast, an active-active architecture features multiple identical nodes that operate simultaneously, providing built-in redundancy if one node fails.
Restaurants provide a good analogy. If a restaurant had an active-passive system, one waiter would be working at a time, serving the entire restaurant, and the second waiter would be idle until the first waiter took a break. If a restaurant had an active-active system, multiple waiters would work simultaneously, serving the entire restaurant at once. If one waiter needed a break, the others would take on some of the workload without any disruption.
An active-passive system, even when it’s functioning, is essentially brittle. One failure is significant to the operations of the system as a whole. An active-active system is resilient because individual failures mean little to the rest of the system, because the design allows the system to bend without breaking.
The fundamental components of an active-active architecture include:
- Nodes: Servers, data centers, and other points in the network.
- Redundancy: If one node fails, the other nodes can keep the system operational.
- Replication: Each node’s data is kept in sync.
- Load balancing: Distribution of incoming requests across all active nodes.
All together, these components and this configuration ensure a highly available, scalable, and fault-tolerant system.
Ecommerce platforms handling high volumes of traffic, banks that need high availability, and telecommunication networks that can’t afford interrupted service are all likely to deploy active-active architectures. Small businesses with limited IT budgets and legacy infrastructure in government or healthcare organizations are more likely to use active-passive architectures.
Active-active vs. active-passive architectures
Active-active and active-passive architectures are both common and valid high-availability strategies, but they differ in how they manage traffic and the tradeoffs they require.
Active-passive architectures are the traditional approach. One primary node handles all traffic, and passive replicas remain on standby, replicating data and waiting to take over if and when the primary node fails.
Active-active architectures employ multiple nodes that all actively handle traffic simultaneously, especially write traffic. This configuration increases throughput and availability, but can also introduce data consistency and coordination issues between nodes, tradeoffs that make this approach a little more complex than the traditional one.
The key differences include:
- Traffic handling: Active-passive systems route all requests to a single node, and active-active systems distribute load across multiple nodes.
- Resource utilization: Passive nodes in active-passive setups are idle during normal operation, and active-active systems make full use of all nodes.
- Failover and downtime: Active-passive systems rely on failover mechanisms that can introduce brief downtime, and active-active systems reduce downtime via built-in redundancy.
- Performance at scale: Active-active architectures handle higher throughput and offer lower latency under load than active-passive systems. And because active-active architectures can have multiple nodes accepting reads and writes closest to your users, they can also scale better geographically. That said, this can introduce complexity when reconciling concurrent writes.
As with most infrastructure and architecture design decisions, there isn’t a clear, universally applicable choice. Different scenarios benefit from different choices.
Generally speaking, use active-passive when:
- Data volumes are relatively small
- Consistency is critical
- Occasional downtime is acceptable
- Most users reside in the same geographic area
Use active-active when:
- Applications need to serve more than 1000 daily active users
- Growth in queries per second is expected to grow
- Users are distributed across multiple regions
- Low latency, high availability, and distribution at scale are all key goals
- Eventual consistency and coordination complexity are tolerable
The nuance lies in the transition point in between: Many organizations can make active-passive architectures work, but many of those should still build active-active architectures now if they expect to grow.
Why implement active-active architecture?
Active-active architectures tend to require more implementation effort than active-passive architectures, but the extra consideration is well worth it when systems need to be highly available and performant.
The core benefits include: Continuous availability, built-in fault tolerance, horizontal scalability, reduced latency, optimized resource utilization, and improved performance.
Active-active architectures provide continuous availability, because there is no single point of failure. With multiple nodes serving requests in parallel, an active-active architecture ensures the system remains operational even if one or more nodes fail. As a result, users experience uninterrupted service because other nodes seamlessly take over when one fails.
Active-active architectures provide built-in fault tolerance. Redundancy is the primary design philosophy and core benefit of this configuration. If a node crashes or a data center experiences an outage, the workload is instantly redistributed to the remaining nodes. This built-in fault tolerance means fewer emergency incidents, and a wide range of failures, including hardware, network, and software bugs, don’t become customer-facing incidents.
Active-active architectures provide horizontal scalability. Active-active architectures allow applications to scale out easily. As applications grow, requiring them to handle more traffic or a growing user base, organizations can add extra nodes, and the load balancer can spread requests to them. Without this design, organizations would have to scale one server vertically.
Active-active architectures provide reduced latency. As applications scale across multiple regions, active-active architectures ensure users can be served by the geographically closest or fastest-responding node, which cuts down on network latency. By routing requests to the nearest active node, services can maintain higher response times, lower latency, and even real-time data access.
Active-active architectures provide optimized resource utilization. In an active-active architecture, all nodes are active, meaning none are sitting idle, merely waiting for failure. This is a much more cost-effective way to use hardware. Even though running multiple active instances incurs some cost, the payoff of preventing downtime costs tends to outweigh it.
Active-active architectures provide improved performance. Active-active architectures use parallel processing across multiple nodes to provide resilience, while also enhancing overall throughput and responsiveness. Each node handles a portion of the total requests flowing through the system, so response times can improve as requests are distributed across multiple nodes instead of being funneled to a single node.
These benefits apply to a wide range of industries, but in some industries, they’re imperative. Consider, for example:
- Financial services, where even a few seconds of downtime can have significant financial repercussions.
- Ecommerce, where platforms need to handle huge volumes of web traffic, searches, and transactions continuously.
- Telecommunications, where providers must maintain continuous network services across geographically dispersed areas.
- Healthcare services, where electronic health record (EHR) systems must be available at all times.
- Online gaming, where platforms need to distribute game sessions and player interactions across multiple active servers while serving millions of concurrent players around the world.
Whenever a company is dealing with real-time data, high transaction volumes, or critical uptime and reliability requirements, active-active architecture can provide major benefits.
Components of active-active architecture
Implementing an active-active architecture involves assembling a few core components, including load balancers, data replication, and failover detection, but it also requires designing the architecture so that all these components work together in concert.
Load balancers distribute client requests across all active nodes, ensuring that traffic is routed efficiently and that no single node becomes overwhelmed. If one node is unavailable, the load balancer is what automatically directs the load to other nodes. Load balancers provide intelligent routing policies that organizations can fine-tune to minimize latency based on different priorities.
Database replication is the process that ensures data is kept consistent (or eventually consistent) across all active nodes. As data changes on one node, changes are propagated to the databases on the other nodes. Replication can be synchronous or asynchronous. The former is when transactions on one node trigger simultaneous applications to other nodes. The latter is when the primary node only pushes changes to other nodes after returning success to the client.
Failover detection occurs when a node fails, and the system detects and mitigates the failure, minimizing its consequences. In an active-active architecture, failover doesn’t happen the way it does in other systems because the rapid detection of failure ensures that the built-in redundancy can take over when the failure occurs. The best systems constantly monitor each node’s health via heartbeat signals between nodes, periodic health-check pings, and test queries to each node.
How does active-active architecture work?
The components above work in concert when an active-active architecture can synchronize data between nodes, resolve data conflicts, maintain peer replication mechanisms, and manage traffic across automated failovers.
The heart of an active-active architecture’s functionality is data replication and synchronization. Whenever a node processes a write to the database, that change is replicated to other active nodes, so they all end up with the same data. In practice, this means each node’s database will have a replication agent or mechanism that streams changes to the others.
Some active-active systems allow concurrent writes on multiple nodes, which has several advantages but poses the possibility of two nodes updating the same data simultaneously, which can cause conflicting updates or data collisions. There are several approaches to address this, including vector clocks, which identify concurrency by tagging node updates and comparing clocks across nodes, and Conflict-Free Replicated Data Types (CRDTs), which enable multiple copies to be updated without requiring immediate coordination, ensuring that these replicas will eventually converge to the same state.
Redis, for example, implements CRDTs using a global database that spans multiple clusters, creating a conflict-free replicated database (CRDB). A CRDB enables seamless conflict resolution, local latency for read and write operations, and business continuity even when some geo-replicated regions are unavailable. Each CRDB instance also maintains separate vector clocks for each dataset, which are updated after any update operation at the instance level or when another update operation for the same object arrives from another CRDB instance.
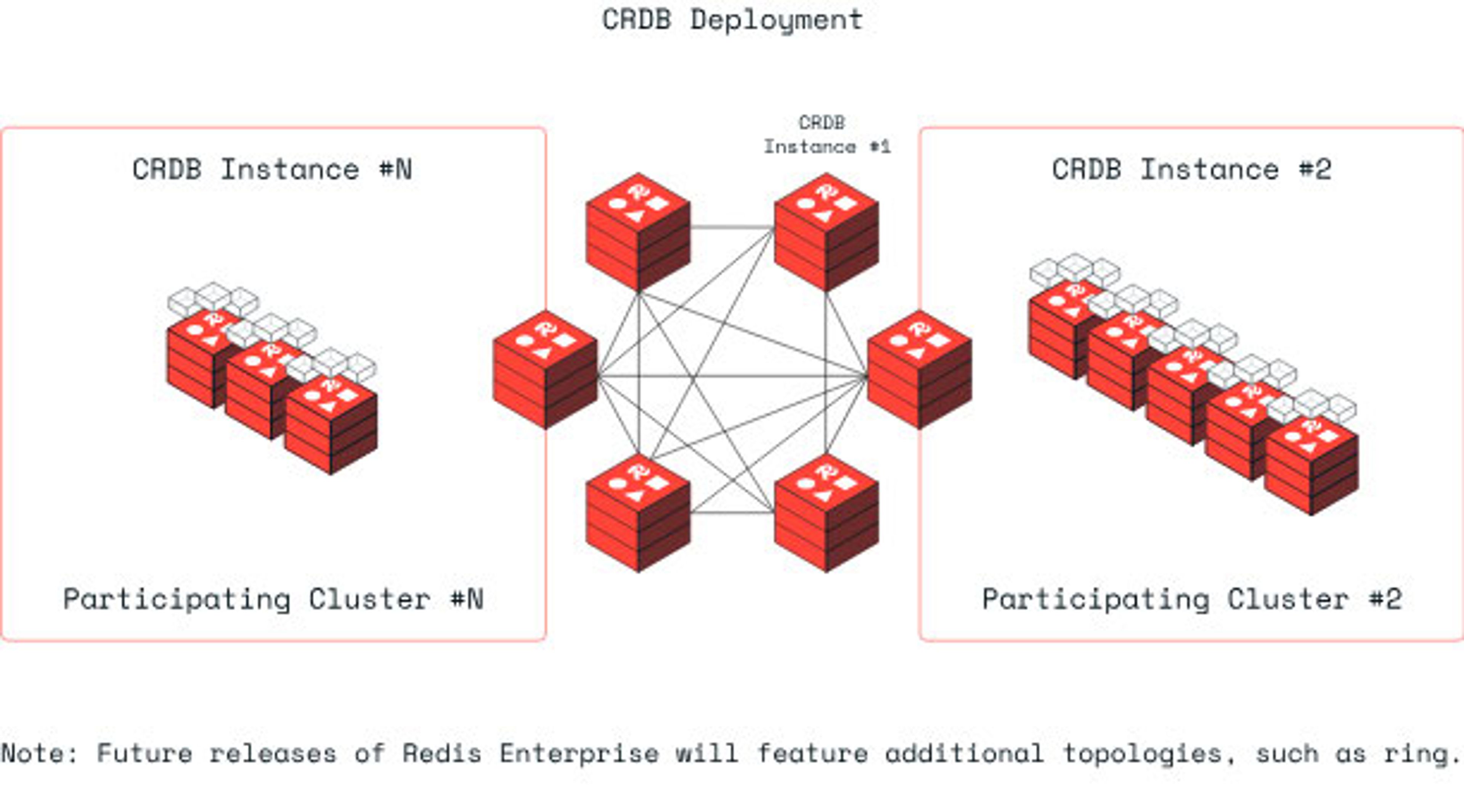
Active-active architectures use peer-to-peer replication, which uses each node as both a source and recipient of replication. There are several ways to accomplish this, including mesh replication, where every node directly replicates to every other node, and intermediate brokers, which use middleman services to support replication between nodes.
Tying this all together is the traffic management functionality that automates failover and ensures the workload from failed nodes is taken on by the still active nodes. The right traffic management feature ensures the load is continuously balanced, such that if one node is removed, the remaining nodes each take on a bit more of the traffic. The architecture routes around an outage rather than going down due to it.
Challenges and considerations in active-active architectures
The advantages of deploying an active-active architecture are substantial, but implementation can be complex, which introduces a challenge organizations need to address proactively.
The three most common challenges in active-active architectures include:
- Data consistency and conflict resolution: How can you ensure all nodes have a consistent view of data when updates can occur anywhere? You need to decide on a consistency model – either strong consistency or eventual consistency.
- Replication latency and synchronization: Asynchronous replication inevitably means some amount of replication latency – how will you manage that? Generally, teams either use sticky sessions to send users back to the same node or fast replication and effective client retry logic.
- Monitoring and maintaining health across geographically distributed systems: How will you monitor the health and performance of all nodes across all the different regions and time zones your application serves? Teams need a comprehensive monitoring system that aggregates metrics and status from all nodes, tracks replication queues, and performs regular health checks.
Redis Enterprise clusters, for example, provide mode watchdogs that monitor all the processes running on a given node.
These pitfalls are often easier to handle when you plan for them ahead of time. If you implement without awareness of these issues or fail to follow best practices, you can end up doing costly rework.
Implementing active-active architecture: Best practices
Implementing active-active architecture can be complex, but the work is made much simpler (and the results more effective) by diligently following the right steps and best practices.
The foundation is infrastructure and topology planning. Start by designing your system layout, which includes determining the number of nodes and their placement, as well as determining how you will isolate failures. This also requires building a reliable, high-bandwidth network to connect the nodes and regions. Each node should have enough capacity to handle the full load (or a large portion of it) in the event that the other nodes fail.
The next step is to select suitable database technologies and cloud services that support the infrastructure you’ve designed. As a substep, evaluate your application’s consistency needs and select the replication mode (synchronous, asynchronous, or hybrid) that best suits your use case. Your choice of database technologies will largely depend on the level of consistency you need. Redis, for example, supports CRDTs in Redis Enterprise, which allows for CRDBs.
This step will also include choosing and using the right cloud services and tools. AWS, Azure, and GCP, for example, all provide managed services that simplify active-active setups (such as Amazon Aurora Global Database). Similarly, many of these providers also offer load balancing tools, such as GCP Cloud Load Balancing. In general, focus on selecting tools that both meet your needs and support broad platform compatibility and open standards.
Once you have an infrastructure design and database technologies to support it, you need to implement robust monitoring and alerting systems to help you maintain and manage what you’ve built. Each node should emit health metrics, replication statistics, and application-level metrics. Ideally, you have a monitoring system in place that can aggregate this data to give you a unified view and alerts for any critical indicators.
To complete your setup, you also need to develop effective disaster recovery and failover strategies. Even though active-active steps have failover built in, you still need to plan for disaster scenarios beyond node failure. If an entire region goes offline, for example, how can you recover? Many standard best practices come into play here, such as documenting recovery procedures, storing data backups and snapshots in multiple locations, and building recovery points. Throughout, test these policies to ensure they work and run the way you want them to.
What to look for in an active-active solution
There are active-active solutions that make this work easier to implement, simpler to manage, and more effective. To find the right one for you, look under the hood to find features that manage the complexity for you, and free you to use the reliability and scalability to grow.
Among the features you should consider, prioritize:
- Advanced CRDTs: Supports data consistency and seamless synchronization across multiple regions. Redis, for example, provides CRDBs, conflict-free databases that span multiple software clusters.
- Automated failover: Minimizes downtime and ensures continuous data availability. Redis Enterprise is a self-managed, real-time data platform offers five-nines (5-9s) high availability, including automatic failover, backup, and recovery.
- Seamless cross-region synchronization: Maintains data consistency across geographically distributed deployments.
- Intuitive monitoring tools: Provides clear insights for easier management of distributed systems. Redis Insight, for example, makes it easy for developers to debug and visualize database issues using an AI-powered assistant, advanced CLI, and GUI.
- Robust scalability features: Supports scalability options so that your infrastructure can handle growing and changing workloads. Redis, for example, can scale horizontally with Redis Clusters.
- Broad cloud platform compatibility: Flexibility to integrate with major cloud services, such as AWS, Azure, and GCP, so that you can avoid vendor lock-in.
As you search, make sure that the providers you’re looking into have case studies that prove their claims. Flowdesk, for example, needed to facilitate sub-second access to order books that store financial data worldwide, and chose Redis to support a high-availability, low-maintenance database to integrate with its Google Cloud ecosystem.
“Other than making the initial connections to the database, we don’t have to do anything on the infrastructure side to manage the Redis Enterprise environment,” Julien Tocci, Head of Infrastructure at Flowdesk, explains. “This allows us to focus on business needs rather than managing a database. Redis Cloud auto-scaling works as intended, so we can always count on it as we hyperscale our client base.”
This hands-off experience even applied as Flowdesk migrated customers across regions. “We’ve been migrating customers from the Japan region to the Active-Active subscription, which spans all three regions,” Tocci says. “As we expand our multi-region clusters, Active-Active Redis is a perfect match for what we need.”
Strengthen your active-active architecture with Redis
Active-active architecture can significantly enhance your infrastructure's resilience, availability, and performance, but it requires careful implementation to avoid complexity costs. Done right, active-active architecture can enable continuous availability, reduce latency, and improve fault tolerance, allowing applications that need reliability and scalability to perform at the levels users expect and businesses need.
Redis Enterprise is purpose-built for active-active deployments, ensuring consistently responsive and highly available applications even under demanding workloads. Ready to elevate your infrastructure with active-active architecture? Try Redis for free today or schedule a personalized demo.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.