
Today we’re going to dive quite a bit deeper and make something useful with Node.js, RediSearch and the client library we started in Part II.
While RediSearch is a great full-text search engine, it’s much more than that and has extensive power as a secondary index for Redis. Considering this, let’s get a dataset that contains some more field-based data. I’ll be using the TMDB (the movie database) dataset. You can download this dataset from the Kaggle TMDB page. The data is formatted in CSV over two files and has a few features we’re not going to use yet, so we’ll need to build an ingestion script.
To follow along, it would be best to get the chapter-3 branch of the GitHub repo.
Understanding the Dataset Structure
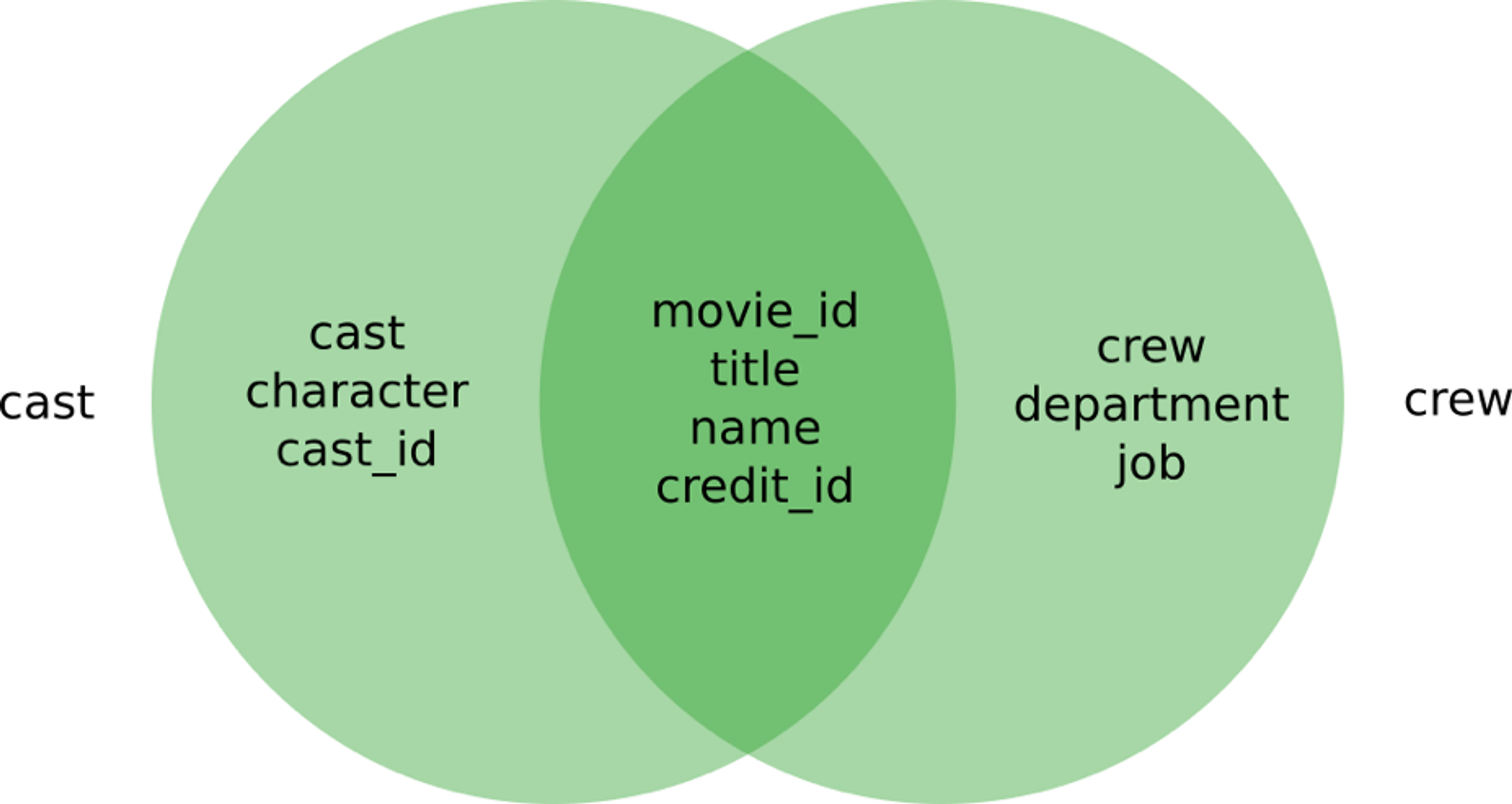
The first file is tmdb_5000_credits.csv, which contains the cast and crew information. Though cast and crew rows are modeled a bit differently, they do share some features. Initially, it’s not a very usable CSV file since two columns (cast, crew) contain JSON.
movie_id (column) This correlates with a movie row in the other file.
title (column) The title of the movie identified with the movie_id
cast (column with JSON)
- character The name of the character
- cast_id An identifier of the character across multiple movies
- name The name of the actor or actress
- credit_id A unique identifier of this credit
crew (column with JSON)
- department The department or category of this role
- job The name of the role on set
- name The name of the crew member
- credit_id A unique identifier of this credit
Another problem with the CSV is that it’s quite huge for a file of its type: 40mb (for comparison, the total works of Shakespeare is just 5.5mb). While Node.js can handle files of this size, it’s certainly not all that efficient. To ingest this data optimally, we’ll be using csv-parse, a streaming parser. This means that as the CSV file is read in, it is also parsed and events are emitted. Streamed parsing is a fitting addition to the already high-performing RediSearch.
Each row in the CSV represents a single movie, with about 4,800 movies in the file. Each movie, as you might imagine, has a dozens to hundreds of cast and crew members. All in all, you can expect to index about 235,838 cast and crew members — each represented by nine fields.
The other file in the TMDB dataset is the movie data. This is quite a bit more straightforward. Each movie is a row with a few columns that contain JSON data. We can ignore those JSON data columns for this part in the series. Here is how the fields are represented:
movie_id (column) A unique ID for each movie
budget (column) The total film budget
original_language (column) ISO 639–1 version of the original language
original_title (column) The original title of the film
overview (column) A few sentences about the film
popularity (column) The film’s popularity ranking
release_date (column) The film’s release date (in YYYY-MM-DD format)
revenue (column) The amount of money it earned (USD)
runtime (column) The film’s runtime (in minutes)
status (column) The film’s release status (“released” or “unreleased”)
Ignored columns: genres, production_companies, keywords, production_countries, spoken_languages
Importing Data from TMDB
Now that we’ve explored both the fields and how to create an index, let’s move forward with creating our actual indexes and putting data into them.
Thankfully, most of the data in these files is fairly clean, but that doesn’t mean we don’t need to make adjustments. In the cast/crew file, we have the challenge of cast and crew entries having slightly different sets of data. In the data, each row represents a movie and the cast column has all the cast members while the crew column has all the crew members. So, when we’re representing this in the schema, we’re effectively creating a union of the fields (since there is overlap). cast and crew are numeric fields that are set to “1” for each kind of credit—think of it like a flag.
For the movie database, we’re going to convert release_date to a number. We’ll simply parse the date into a Javascript timestamp and store it in a numeric field. Finally, we’ll ignore a number of fields — we’ll just compare columns’ keys to an array of columns in order to skip (ignoreFields).
From a project structure, we may end up doing more with our fieldDefinitions later on, so we’ll store both schema in a Node.js module. This is purely optional but is a clean pattern that reduces the likelihood of having to duplicate your code later on.
For importing both movies and crew, we’ll be using an Async queue and the above-mentioned streaming CSV parser. These two modules work similarly and well together, but have some different terminology in their syntax. First, the CSV parser will read a chunk of data ( parser.on(‘readable’,…) ) and then continue to read a full-row in at a time ( while(record = parser.read()){ … } ). Each row is manipulated and readied for RediSearch (csvRecord(record)). In this function, a few rows are formatted while some are ignored, and finally the item is pushed into the queue ( q.push(…) ).
Async is a very useful Javascript library that provides a huge number of metaphors for handling asynchronous behavior. The queue implementation is pretty fun — items are pushed into a queue and are processed at a given concurrency by a single worker function defined at instantiation. The worker function has two arguments : the item to be processed and a callback. Once the callback has ran, the next is available for processing (up to the given concurrency). There is a great animation that explains it:
The other feature of queue that we’ll be using is the drain function. This function executes when there are no items left in the queue, e.g. the queue was in a working state but is no longer processing anything. It’s important to understand that a queue is never “finished,” it just becomes idle. Given that we’ll be using a streaming parser, it’s possible that RediSearch is ingesting faster than the CSV parser, resulting in an empty Async queue (triggering drain). To address this potential problem, each record is added to the queue and when it is successfully indexed, two individual counters are incremented (total and processed, respectively) and the CSV parser sets a parsed variable from “false” to “true.” So when drain is called, we check to see if parsed is true and if the value of processed matches total. If both of these conditions are true, we know that all the values have been parsed from the CSV and that everything has been added to our RediSearch index. After you’ve successfully added an item to the index, you invoke the callback for the worker function and the queue manages the rest.
As mentioned earlier, the credits CSV is more complex, with each row in the table representing multiple cast/crew members. To manage this complexity, I’ll be using a batch. We’ll be using the same overall structure with the CSV parser and Async queue, but each row will contain multiple calls to RediSearch via the batch (one for each cast or crew member). Instead of pushing a plain object into the queue, we’ll actually push a RediSearch batch. In the worker function we’ll call exec on it and then the callback. While in the movies CSV we’ll have a single Redis (RediSearch) command per movie, in the credits CSV we’ll have a single batch (made up of dozens of individual features) for each movie.
The two imports are different enough to warrant separate import scripts. To import the movies, you’ll run the script like this:
And the credits will be imported like this:
A killer feature of RediSearch is that as soon as your data is indexed, it’s available for query. True real-time stuff!
Searching the Data
Now that we’ve ingested all this data, let’s write some scripts to get it back out of RediSearch. Despite the data being quite different between the cast/crew and the movie datasets, we can write a single, short script to do the searching.
This little script will allow you to pass in a search string from the command line (–search=”your search string”) and also designate the database you’re searching through (–searchtype movies or –searchtype castcrew). The other command line arguments are the connection JSON file (–connection path-to-your-connection-file.json) and optional arguments to set the offset and number of results ( –offset and –resultsize, respectively).
After we instantiate the module by passing in the argv.searchtype, we’ll just need to use the search method to send the search query and options as an object to RediSearch. Our library from the last section takes care of building the arguments that will be passed through to the FT.SEARCH command.
In the callback, we get a very standard looking error-first callback. The second argument has the results of our search, pre-parsed and formatted in a useful way — each document has it’s own object with two properties: doc and docId. The docId contains the unique identifier and document as an object.
All we need to do is JSON.stringify the results (so console.log won’t display [Object object]) and then quit the client.
You can try it out by running the following command:
This should return an entry about the movie Lone Star (anyone seen it? No, I didn’t think so). Now, let’s look in the cast/crew index for anything with the same move_id:
This will give you the first ten items of the cast and crew for Lone Star. Looks straight forward except for the search string — why do you have to repeat 26748 twice? In this case it’s because the movie_id field in the database is numeric and numerics can only be limited by a range.
Grabbing a Document
Getting a document from RediSearch is even easier. Basically, we instantiate everything the same way as we did with the search script, but we don’t need to supply any options and instead of a search string we’re getting a docId.
We just need to pass the docId to the getDoc method (abstracting the FT.GET command) along with a callback and we’re in business! The show function is the same as in the search.
This will work equally well for both cast/crew or movie documents:
Dropping the Index
If you try to import a CSV file twice you’ll get an error similar to this:
This is because you can’t just create an index over a pre-existing one. There is a script included to quickly drop one of your indexes. You can run it like this:
Status and Next Steps
In this installment, we’ve covered how to parse large CSV files and import them into RediSearch efficiently with a couple of scripts tailored to their different structures. Then we built a script to run search queries over this data, grab individual documents and drop an index. We’ve now learned most of the steps to managing the lifecycle of a dataset.
In our next installment, we’ll build out a few more features in our library to better abstract searching and add in a few more options. Then we’ll start building a web UI to search through our data. Stay tuned to the Redis blog!
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.