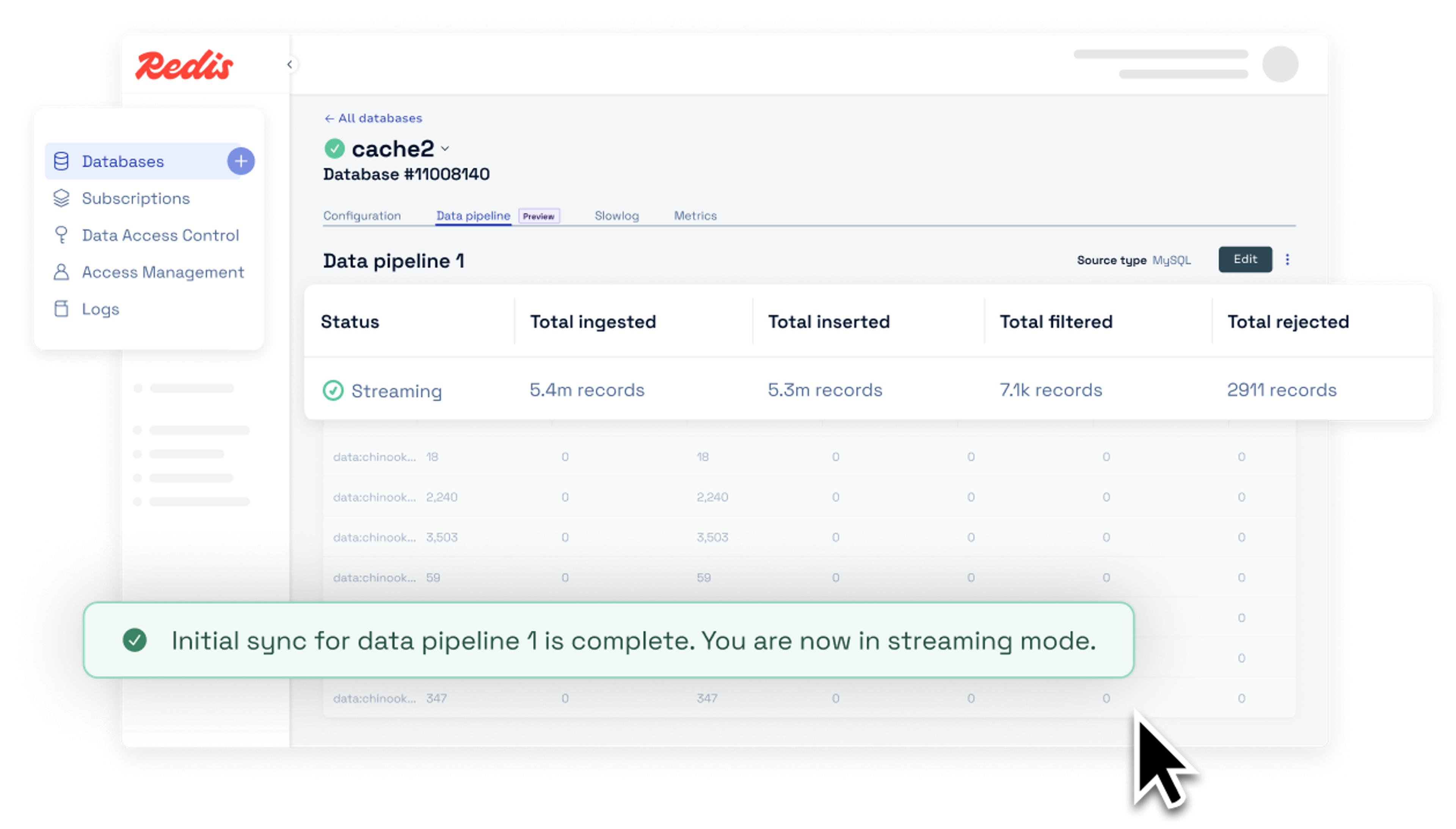
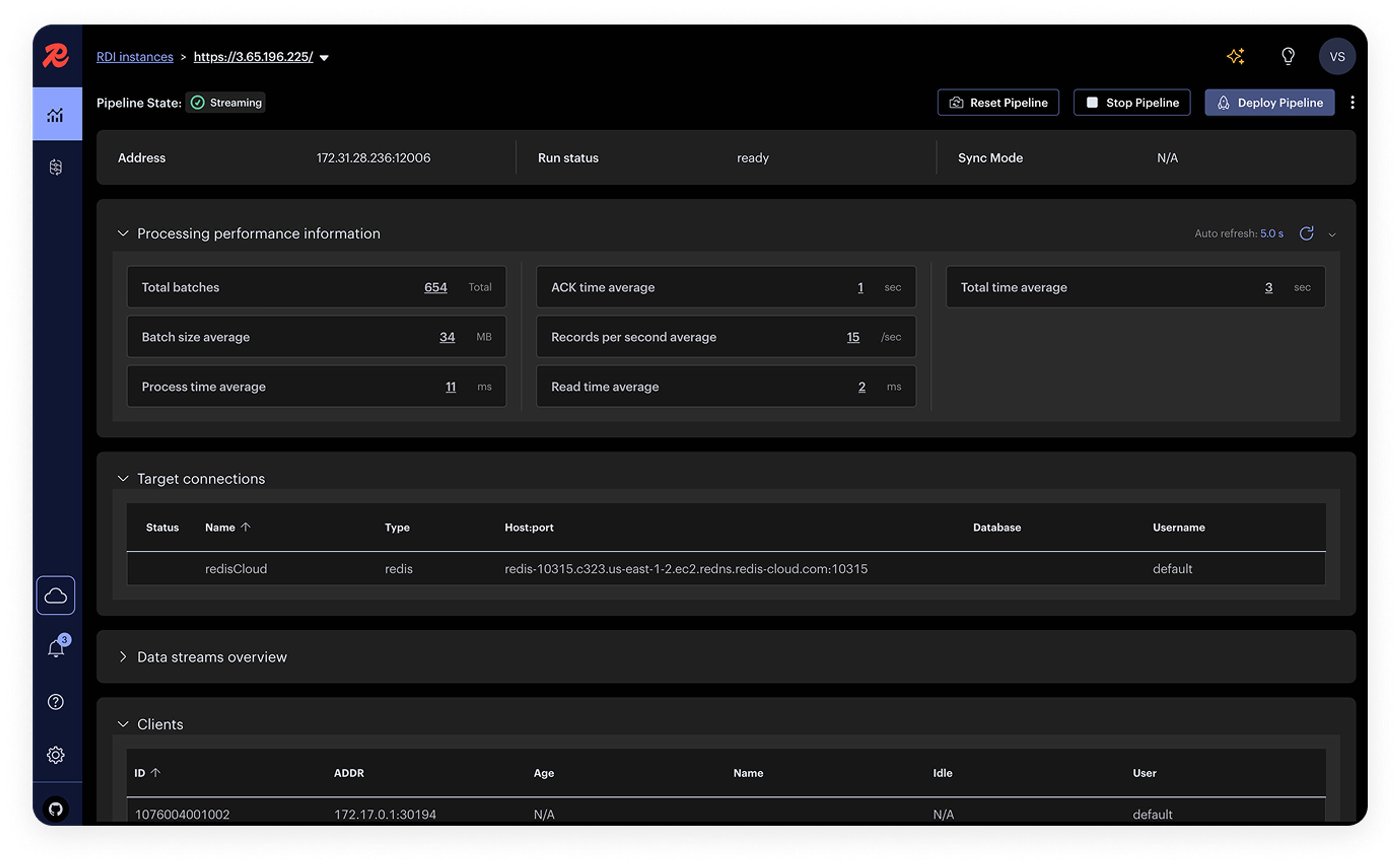
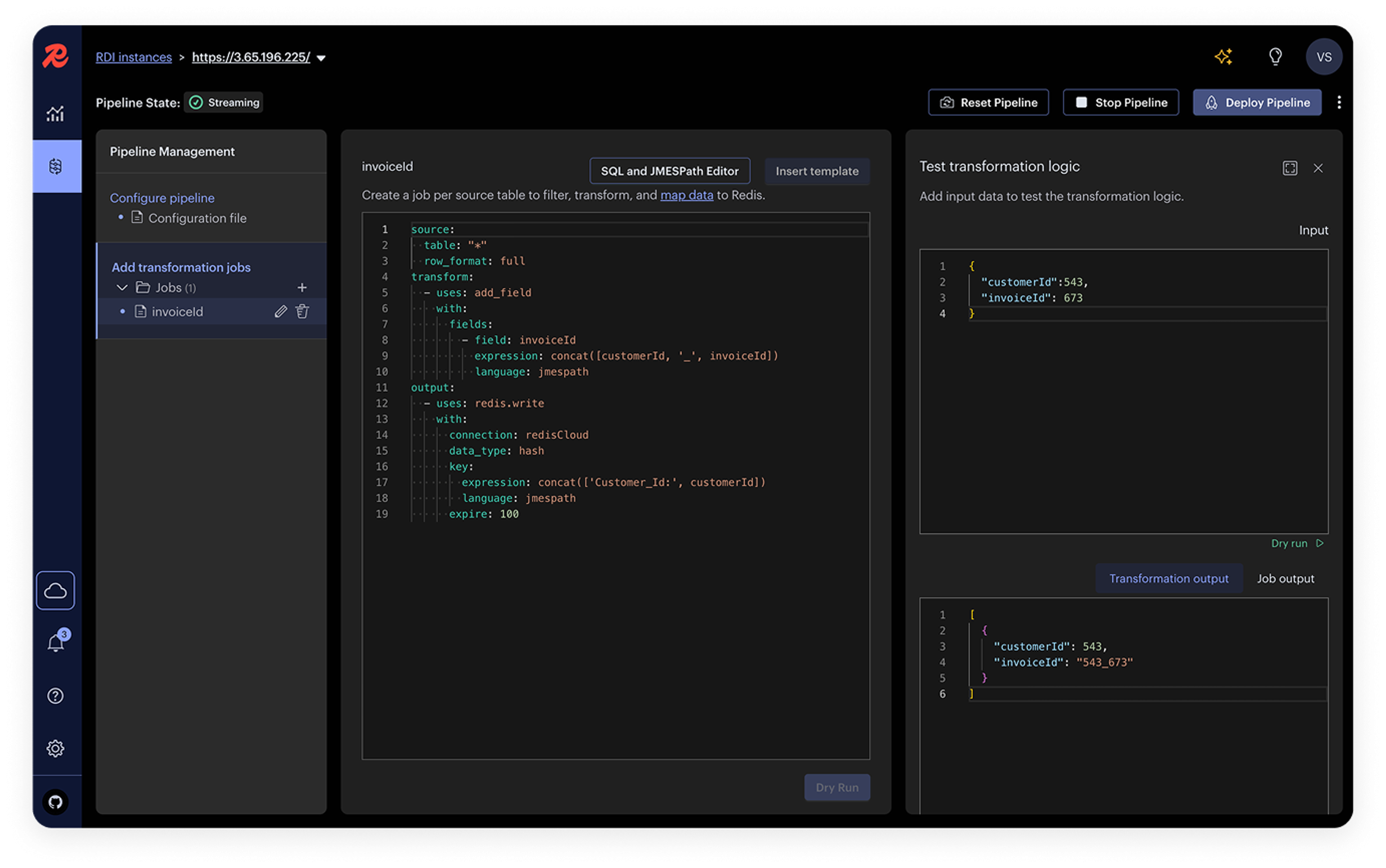



“We don’t want any operational headache between the systems. It should all be reliable and work flawlessly; that’s what we’re counting on. So far, Redis is giving us the tools and peace of mind we were looking for so that we can spend more time focusing on our customers."
Rural lifestyle retailerSenior architect







