Blog
Hybrid search benefits: Why your RAG system needs both keyword & vector search

Pure vector search is great until someone searches for 'PostgreSQL performance' and you miss the document titled 'Optimizing Postgres queries.' Pure keyword search is great until someone asks 'How do I make my database faster?' and you miss everything that doesn't contain those exact words. Hybrid search helps address both problems.
You'll get improved retrieval accuracy, more precise context selection, and reliable performance across query types. Hybrid search works well for technical docs, legal/medical retrieval requiring exact terminology, and RAG systems where you need both semantic understanding and keyword precision.
In this article, we'll explore how hybrid search combines BM25 and vector retrieval, when to use it in your RAG architecture, and how to implement it in production.
What is hybrid search really?
Hybrid search combines BM25 and vector search to catch what either approach misses alone. When you search for "database performance optimization," two parallel retrievals happen:
- Sparse retrieval (BM25): Ranks documents using term frequency and inverse document frequency. Excels at exact term matching but won't find "scaling web applications" when you search for "horizontal scaling strategies."
- Dense retrieval (vector search): Transforms queries into high-dimensional embeddings capturing semantic meaning. Unlike BM25, it understands that "scaling" and "horizontal scaling" are conceptually related.
Both paths return their top candidates, then a fusion algorithm, usually Reciprocal Rank Fusion (RRF), merges them into a single ranked list. RRF uses ranks rather than raw scores, making it robust when combining BM25's unbounded relevance scores with vector similarity's normalized 0-1 range. Research shows convex combination methods can outperform RRF in some settings, so test both approaches with your data.
Systems like Redis support hybrid search natively. Redis (an in-memory database known for sub-millisecond performance) combines vector search with metadata filtering so you can optimize for your specific precision and latency requirements.
Where hybrid search lives in RAG architecture
Hybrid search sits between query processing and LLM generation in your RAG pipeline. RAG retrieves relevant documents at query time and feeds them into the model as context. Hybrid search makes that retrieval better through dual-path processing.
The complete data flow:
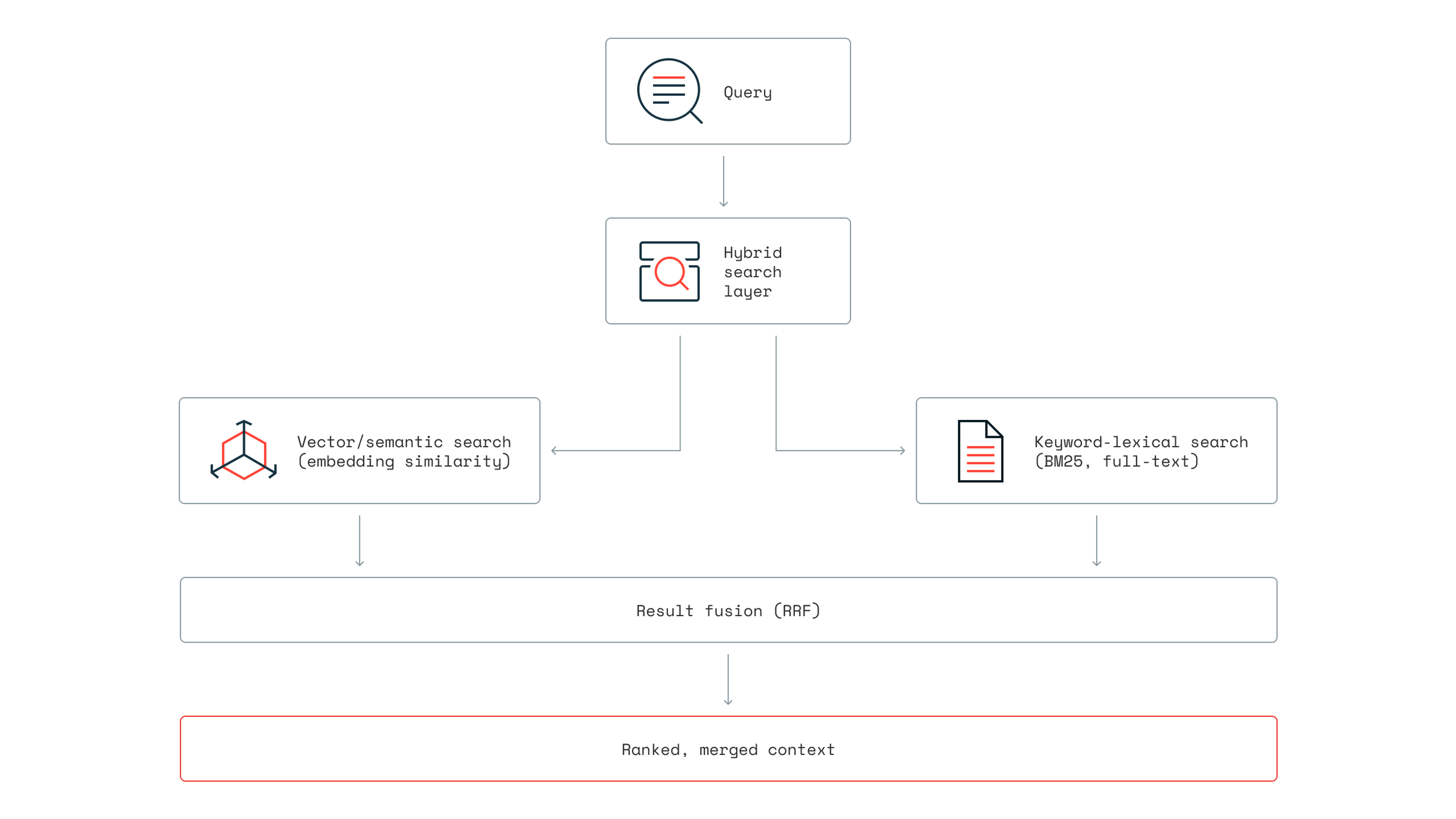
Your framework likely already supports this. Hybrid search combines results from both semantic search (embedding similarity) and keyword search, with most major frameworks offering native support through custom retrievers.
Redis provides flexible orchestration for complex search patterns through its unified vector and keyword search infrastructure, allowing engineers to combine multiple retrieval techniques for sophisticated production workflows requiring custom fusion algorithms and multi-source retrieval. Most frameworks support metadata-enhanced filtering. Redis lets you filter data with metadata before performing the top-k similarity search, enabling temporal filtering, source authority weighting, and domain-specific constraints.
Why hybrid search matters for AI cost & speed
Improved retrieval precision can reduce LLM token costs substantially, often by tens of percent, though actual savings depend on your corpus characteristics, query patterns, and baseline retrieval precision.
The mechanism is straightforward: better retrieval precision means fewer irrelevant documents in context, which means lower token count per query, which means reduced LLM API costs. Every document you don't send to the LLM saves money.
Better context quality
Hybrid search improves what enters your limited context window by prioritizing both semantically relevant and exactly matched content. Language models have finite context windows, and retrieval quality directly impacts generation quality.
Pure semantic search excels at understanding user intent but struggles with:
- Technical terminology, acronyms, and abbreviations
- Numerical data and product identifiers
- Domain-specific jargon requiring exact matches
Keyword search handles these well but misses conceptual relationships. The combination provides complementary strengths: semantic search handles complex user intent and conceptual similarity, while keyword queries ensure important exact-match terms aren't missed.
Accuracy improvements you can measure
Microsoft's testing on production customer indexes found hybrid search achieves 48.4 average relevance scores vs. 40.6 for keyword-only and 43.8 for vector-only approaches. Gains vary based on corpus characteristics and query complexity, but the pattern holds across most retrieval scenarios.
Performance at scale
Production hybrid search systems need to handle high throughput while maintaining accuracy. Key metrics to evaluate include insertion rate (how fast you can index new documents), query latency (time to return results), and recall at high precision thresholds (whether you're actually finding the most relevant results).
For reference, Redis sustains 66,000 vector insertions per second for indexing configurations achieving ≥95% precision with sub-millisecond latency. Benchmarking shows Redis is faster for vector database workloads compared to other tested vector databases at recall ≥0.98: the high recall rates production AI apps need.
How to know when hybrid search is right for you
Not every app needs hybrid search. Here's how to decide.
| Use Case | Pure Vector Search | Hybrid Search |
|---|---|---|
| AI chatbots focused on user intent | ✓ | x |
| Recommendation systems (conceptual similarity) | ✓ | x |
| Natural language queries | ✓ | x |
| Users describing concepts without specific terms | ✓ | x |
| Knowledge bases with mixed query types | x | ✓ |
| Document classification with controlled vocabulary | x | ✓ |
| Technical docs with standardized terminology | x | ✓ |
When in doubt, start with hybrid search. You can always simplify later if your query patterns don't require exact matching.
The infrastructure trade-off
Hybrid search uses dual indexing: a BM25 index for lexical relevance and a vector index for semantic understanding, queried in parallel and merged through a fusion layer.
Redis simplifies this by storing vectors and metadata together within hashes or JSON documents for indexing and querying. This supports hybrid search, reducing the need to manage separate vector database + keyword search systems and lowering operational complexity.
Redis offers three vector index types: FLAT for exact nearest neighbor search with 100% recall on smaller datasets, HNSW for approximate search with configurable speed/accuracy trade-offs, and SVS-VAMANA for memory-efficient large-scale deployments. Choose based on your dataset size, latency requirements, and accuracy tolerance.
Hybrid search in agentic AI & multi-step retrieval
Hybrid search becomes even more important in agentic systems where AI agents make autonomous retrieval decisions across multiple tool calls. Effective agent systems employ hybrid models for context management; some context is loaded up front, while search primitives allow agents to retrieve information just-in-time.
Agent memory & autonomous retrieval
Hybrid retrieval systems use agent-based decision routing for multi-step workflows, combining knowledge graphs, vector stores, and LLM decision-making to automate complex retrieval workflows. The agent's decision determines which function retrieves context and generates answers.
Redis addresses this through unified storage. Your vectors, metadata, and operational data live in the same system with semantic caching reducing costs through Redis LangCache (the fully-managed semantic caching service) or RedisVL for self-managed options. Semantic caching supports RAG apps, chatbots, and long-term agent memory through sub-millisecond latency without compromising UX.
Framework integration for production
When building agentic systems with hybrid search, look for frameworks supporting durable execution, streaming, and state persistence across conversation turns.
Redis provides official GitHub examples for LangGraph along with ecosystem integrations for Amazon Bedrock, NVIDIA NIM, Microsoft Semantic Kernel, and various embedding providers. Most major frameworks offer pre-built agent architectures with support for durable execution, streaming, and persistence.
The goal is reducing boilerplate so you can focus on retrieval logic rather than infrastructure plumbing.
Common hybrid search pitfalls
Hybrid search isn't plug-and-play. Failures are usually caused by operational mismatches, not flaws in the retrieval methods themselves. Here's what trips up most teams.
Mismatched tokenization
Your BM25 index and embedding model need compatible and intentional preprocessing, or you'll get inconsistent results. If BM25 sees "PostgreSQL" as one token but your embedding model chunks it differently, the same document can rank highly in one path and poorly in the other. This is especially common with technical terms, hyphenated words, and domain-specific abbreviations.
The fix: use consistent preprocessing for both indexes. If you're using Redis, storing vectors and metadata together in the same data structure helps keep tokenization aligned across both retrieval paths.
Over-relying on vector search for exact-match queries
Vector search is powerful, but it's not magic. When someone searches for "error code 0x80070005," they want documents containing that exact string. Vector embeddings might surface conceptually related content about Windows permissions errors, but miss the specific error code entirely.
The fix: analyze your query logs. If a significant share (often 20-30%) of queries contain product codes, error messages, or specific identifiers, weight your hybrid search toward keyword matching for those query types. Some teams implement query classification to route different query types to different weighting configurations.
Testing retrieval and generation together
When your RAG system returns bad answers, the instinct is to blame the LLM. But retrieval problems and generation problems need different fixes. If you're only evaluating final output quality, you can't tell whether the issue is bad context (retrieval) or bad synthesis (generation).
The fix: measure retrieval quality independently. Track metrics like recall@k and mean reciprocal rank before documents hit your LLM. Redis Insight provides visibility into query performance so you can isolate retrieval issues from generation issues.
Ignoring the cold start problem
Hybrid search works best when both indexes have comprehensive coverage. But if you're building incrementally, you might have rich keyword coverage for legacy content and sparse vector coverage for new content, or vice versa. This creates inconsistent result quality depending on what users search for.
The fix: prioritize backfilling whichever index is lagging. Redis supports batch vector indexing at 66,000+ insertions per second, so catching up on vector coverage for existing content doesn't have to be a weeks-long project.
Making hybrid search work for your stack
If you're building RAG systems or agentic AI, hybrid search belongs in your architecture from the start. The dual-path approach catches what either method misses alone, and the retrieval quality improvements justify the dual indexing complexity, especially when your platform handles both search types natively.
Redis makes implementation straightforward with sub-millisecond latency on vector operations. You get vector search with three indexing algorithms (FLAT, HNSW, and SVS-VAMANA), hybrid search through metadata filtering, and semantic caching through Redis LangCache or RedisVL. Your vectors live alongside operational data, validated at scale up to 1 billion vectors.
Try Redis free to benchmark hybrid search with your actual workload, or talk to our team about optimizing your AI infrastructure for production.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.