
RediSearch, a real-time secondary index with full-text search capabilities for Redis, is one of the most mature and feature-rich Redis modules. It is also becoming even more popular every day—in the past few months RediSearch Docker pulls have jumped 500%! That soaring popularity has led customers to come up with a wide variety of interesting use cases ranging from real-time inventory management to ephemeral search.
To extend that momentum, we’re now introducing the public preview of RediSearch 2.0, designed to improve the developer experience and be the most scalable version of Redisearch. RediSearch 2.0 supports Redis’ Active-Active geo-distribution technology, is scalable without downtime, and includes Redis on Flash support (currently in private preview). To meet those goals without negatively impacting performance, we created a brand new architecture for RediSearch 2.0—and it worked: RediSearch 2.0 is 2.4x faster than RediSearch 1.6.
Inside RediSearch 2.0’s new architecture
Having a rich query-and-aggregation engine in your Redis database enables a wide variety of new use cases that extend well beyond caching. RediSearch lets you use Redis as your primary database in situations where you need to access data using complex queries. Even better, it preserves Redis’ world-class speed, reliability, and scalability, and doesn’t require you to add complexity to the code to let you update and index data.
For RediSearch 2.0 we re-architected the way indices are kept in sync with the data. Instead of having to write data through the index (using the FT.ADD command), RediSearch now follows the data written in hashes and synchronously indexes it. This re-architecture comes with several changes in the API, which we discussed in a previous post when RediSearch 2.0 Hit Its First Milestone.
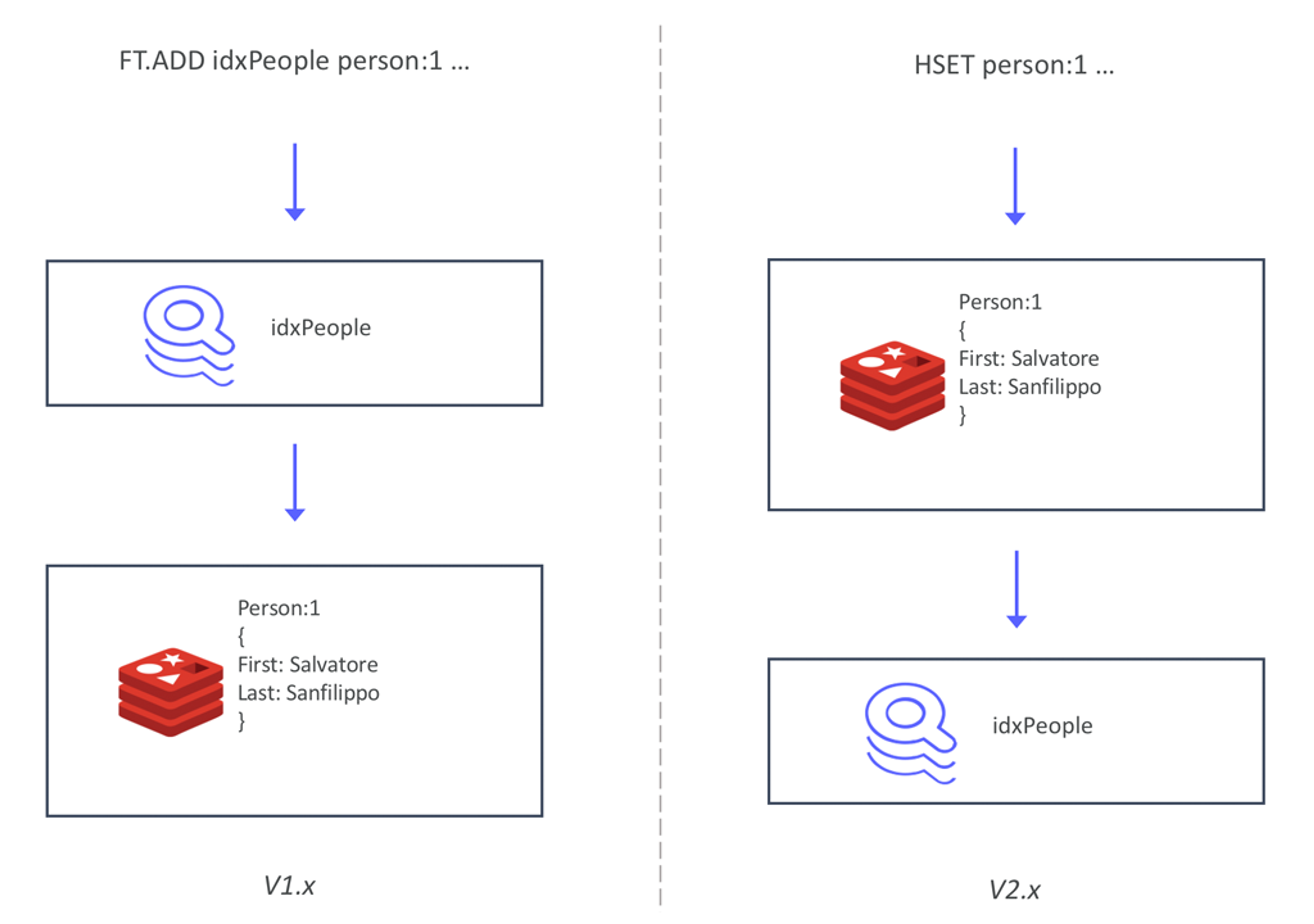
This new architecture brings two main benefits. First, it’s now easier than ever to create a secondary index on top of your existing data. You can just add RediSearch to your existing Redis database, create an index, and start querying it, without having to migrate your data or use new commands for adding data to the index. This drastically lowers the learning curve for new RediSearch users and lets you create indexes on your existing Redis databases—without even having to restart them.
In addition to implementing a new way to index data, we also took the index out of the keyspace. This enables Redis Enterprise’s Active-Active technology, which is based on conflict-free replicated data types (CRDTs). Merging two inverted indices conflict-free is difficult, but Redis already has a proven CRDTs implementation of Hashes. So the second big benefit of this new architecture is making RediSearch 2.0 even more scalable. Because RediSearch now follows Hashes and the index was moved out of the keyspace, you can now run RediSearch in an Active-Active geo-distributed database.
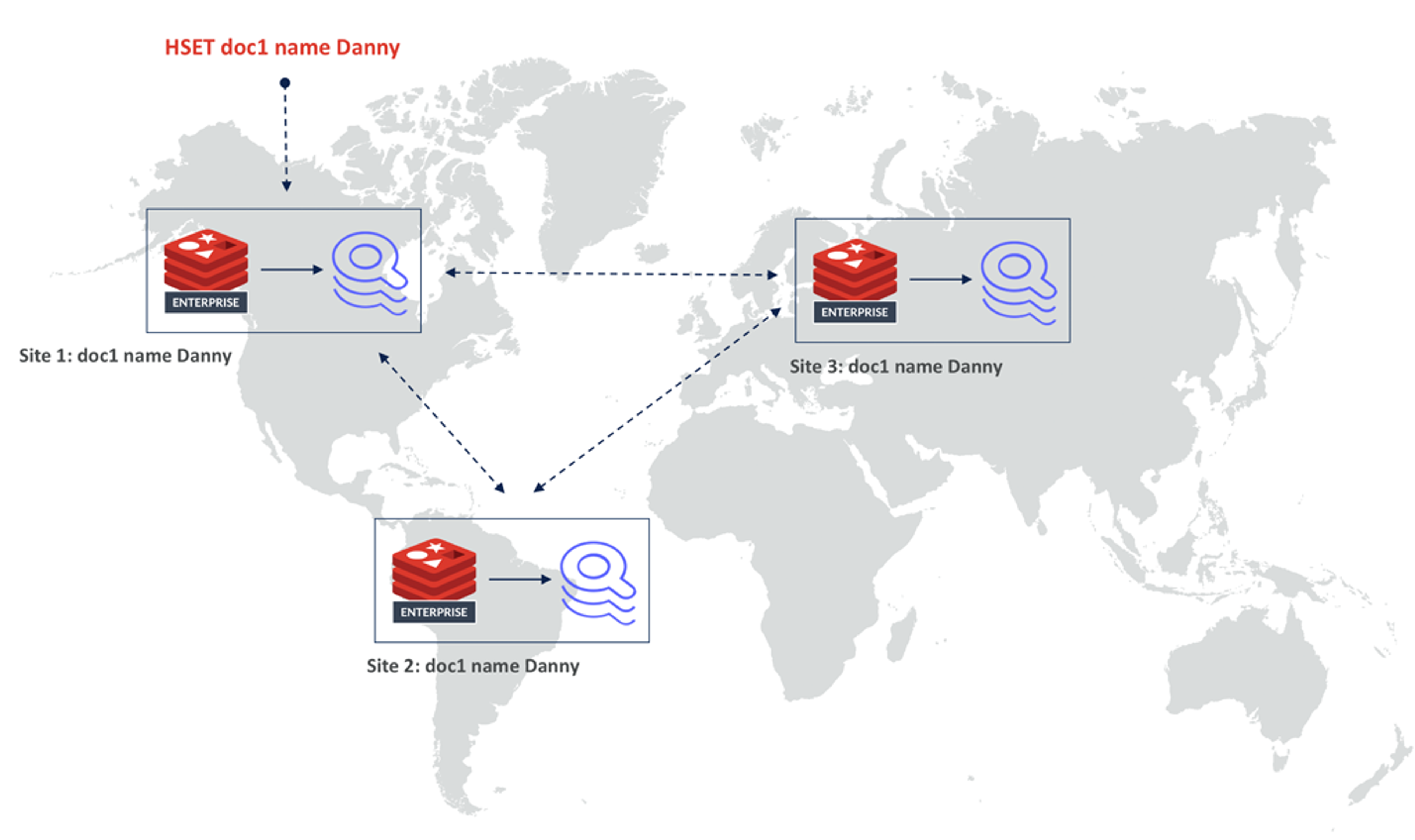
Active-Active technology seamlessly resolves conflicts between documents, and RediSearch updates local indices accordingly.
A document will be replicated to all databases in the replication set in a strongly eventual consistent manner. In each replica, RediSearch will simply follow all the updates on the Hashes, which means all indices are strongly eventual consistent as well.
OSS cluster support for open source Redis
We didn’t want to limit increasing the scalability capabilities to only Redis Enterprise users, so we added support for scaling a single index over multiple shards with the open source Redis cluster API. Previously, a single RediSearch index, and its documents, had to reside on a single shard. This meant that dataset size and throughput for OSS Redis was bound to what a single Redis process could handle. Redis Enterprise offered the ability to distribute documents in a clustered database and aggregate the results at query time. This fan-out and aggregation is handled by a component called the “coordinator” that is now also publicly available under the Redis Source Available License so it will work with open source Redis clusters as well as Redis Enterprise. The result is the most scalable version of RediSearch yet.
Show me the numbers!
To assess RediSearch 2.0’s ingestion performance, we extended our full-text search benchmark (FTSB) suite with the publicly available NYC Taxi dataset. This dataset is used across the industry due to its rich set of data types (text, tag, geographic, and numeric), and a large number of documents.
This benchmark focuses on write performance, using trip-record data of rides in yellow cabs in New York City. Specifically for this benchmark we used the January 2015 dataset, which loads more than 12 million documents with an average size of 500 bytes per document. For the full benchmark specification please refer to the FTSB on GitHub.
All benchmark variations were run on Amazon Web Services instances, provisioned through our benchmark-testing infrastructure. The tests were executed on a 3-node cluster with 15 shards, with RediSearch Enterprise versions 1.6 and 2.0. Both the benchmarking client and the 3 nodes comprising the database with RediSearch enabled were running on separate c5.9xlarge instances.
Given that RediSearch 2.0 comes with the ability to follow changes in Hashes in Redis and automatically index them, we’ve added variants for the FT.ADD and HSET commands. To make upgrades easier, we remapped the now deprecated FT.ADD command to the HSET commands in RediSearch 2.0. The two charts below display overall ingestion rate and latency for both RediSearch 1.6 and RediSearch 2.0, while retaining sub-millisecond latencies.
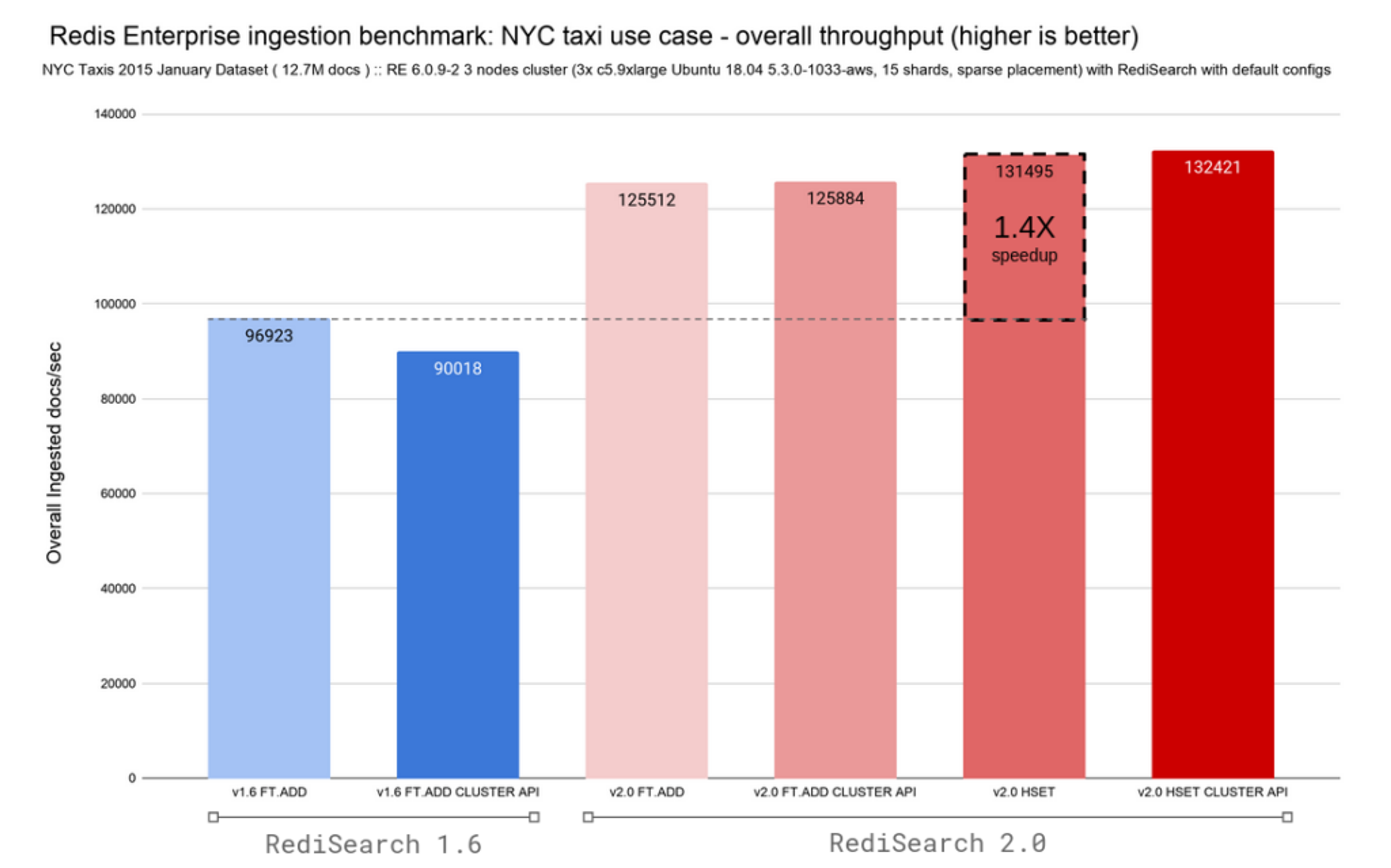
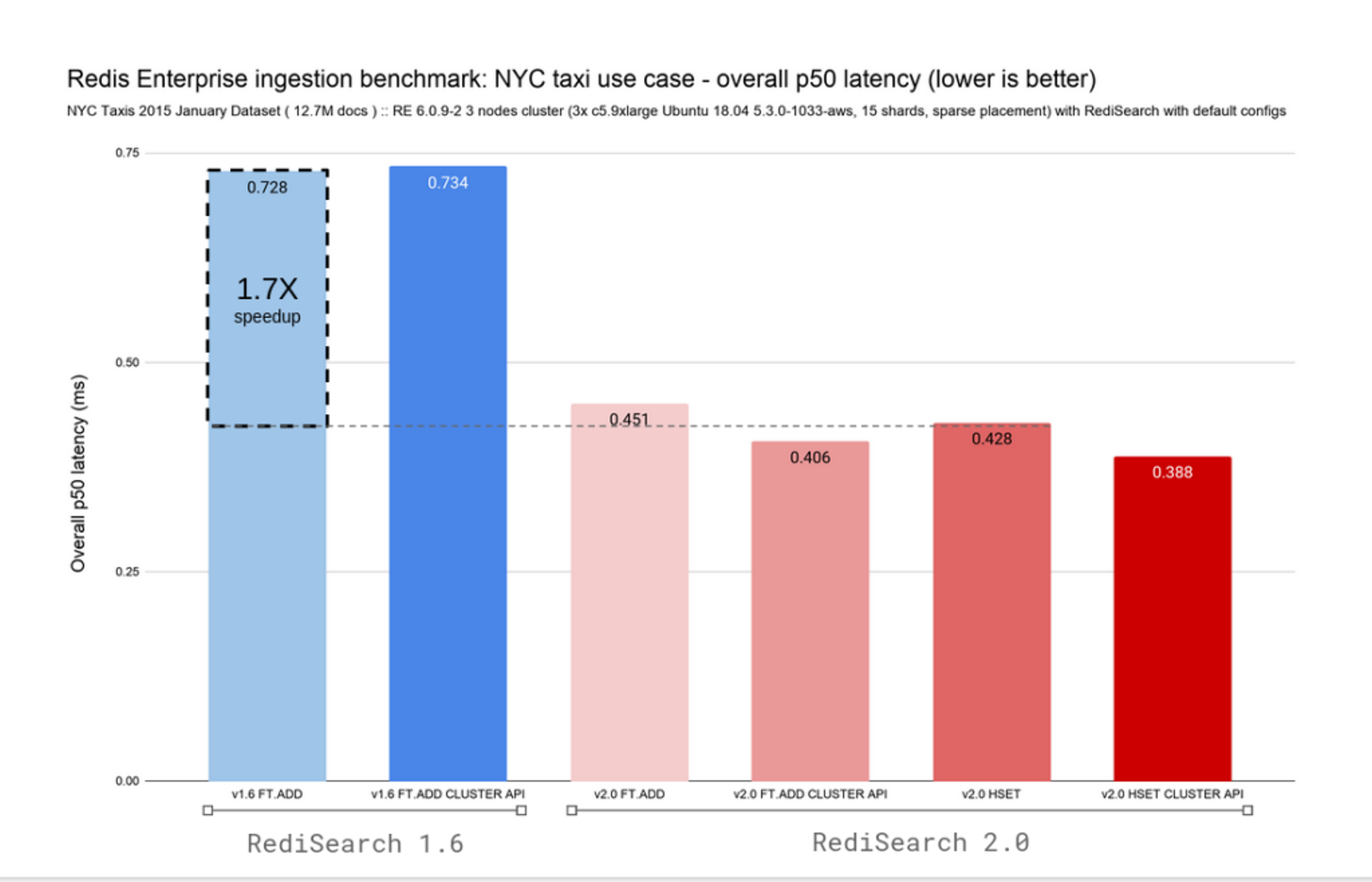
RediSearch has always been fast, but with this architectural change we’ve moved from indexing 96K documents per second to 132K docs/sec at an overall p50 ingestion latency of 0.4ms, drastically improving write scaling.
Not only will you benefit from the boost in the throughput, but each ingestion also becomes faster. Apart from the overall ingestion improvement due to the changes in architecture, you can now also rely on the OSS Redis Cluster API capabilities to linearly scale the ingestion of your search database.
Combining throughput and latency improvements, RediSearch 2.0 delivers up to a 2.4X speedup compared to the RediSearch 1.6.
What’s next for RediSearch 2.0
To sum up, RediSearch 2.0 is the fastest and most scalable version for all Redis users that we have ever released. In addition, RediSearch 2.0’s new architecture improves the developer experience of creating indices for existing data within Redis in a seamless manner and removes the need to migrate your Redis data to another RediSearch-enabled database. This new architecture allows RediSearch to follow and auto-index other data structures, such as Streams or Strings. In upcoming releases, it will let you work with additional data structures such as the nested data structure in RedisJSON.
We plan to keep on adding more features to further enhance the developer experience. Coming next, look for a new command that allows you to profile your search queries to better understand where performance bottlenecks occur during query execution.
Ready to get started? Check out Tug Grall’s blog on … Getting Started with RediSearch 2.0! Then follow the steps in this tutorial on GitHub or create a free database in Redis Enterprise Cloud Essentials. (Note that the public preview of RediSearch 2.0 is available in two Redis Enterprise Cloud Essentials regions: Mumbai and Oregon.)
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.