RedisTimeSeries 1.8 release notes
Added a time-weighted average aggregator, gap filling, ability to control bucket timestamps, ability to control alignment for compaction rules, new reducer types, and ability to include the latest (possibly partial) raw bucket samples when retrieving compactions
Requirements
RedisTimeSeries v1.8.19 requires:
- Minimum Redis compatibility version (database): 6.0.16
- Minimum Redis Enterprise Software version (cluster): 6.2.8
v1.8.19 (October 2025)
This is a maintenance release for RedisTimeSeries 1.8.
Update urgency: MODERATE: Program an upgrade of the server, but it's not urgent.
Details:
Bug fixes:
- #1776 Potential crash on
TS.RANGEwithALIGN +,AGGREGATION twaandEMPTY(MOD-11620, MOD-10484).
Improvements:
- Added support for Rocky Linux 9 and RHEL9 ARM.
v1.8.17 (April 2025)
This is a maintenance release for RedisTimeSeries 1.8.
Update urgency: MODERATE: Plan an upgrade of the server, but it's not urgent.
Details:
*Bug fixes:
- #1725
TS.DELcrashes on keys with compactions if the deletion removes the last compaction bucket (MOD-8936) - LibMR#58 Crash when a cluster contains both 1.8 and newer nodes (MOD-8976, MOD-9192)
Improvements:
- #1712 Added support for Azure Linux 3 (MOD-9170)
- #1736 (Redis Enterprise only) Cross-key commands are handled by a random shard rather than the first shard (MOD-9262, MOD-9314)
v1.8.16 (January 2025)
This is a maintenance release for RedisTimeSeries 1.8.
Update urgency: SECURITY: There are security fixes in the release.
Details
-
Security and privacy:
- #1672 (CVE-2024-51480)
TS.QUERYINDEX,TS.MGET,TS.MRANGE,TS.MREVRANGE- potential integer overflow leading to an out-of-bounds write (MOD-7548)
- #1672 (CVE-2024-51480)
-
Improvements:
- #1664 Added support for Ubuntu 22 and macOS 13 and 14
v1.8.13 (March 2024)
This is a maintenance release for RedisTimeSeries 1.8.
Update urgency: LOW: No need to upgrade unless there are new features you want to use.
Details
-
Bug fixes:
- LibMR#51 Crash on SSL initialization failure (MOD-5647)
-
Improvements:
- #1593 More detailed LibMR error messages
v1.8.12 (December 2023)
This is a maintenance release for RedisTimeSeries 1.8.
Update urgency: SECURITY: There are security fixes in the release.
Details:
-
Security and privacy:
- #1506 Don’t expose internal commands (MOD-5643)
-
Bug fixes:
- #1494 Potential crash when using an invalid argument value
-
Improvements:
- #1516 Added support for CBL-Mariner 2
v1.8.11 (July 2023)
This is a maintenance release for RedisTimeSeries 1.8.
Update urgency: MODERATE: Program an upgrade of the server, but it's not urgent.
Details:
-
Bug fixes:
-
Performance enhancements:
- #1476 Significant performance improvement when using multiple label filters (
TS.MGET,TS.MRANGE,TS.MREVRANGE, andTS.QUERYINDEX) (MOD-5338)
- #1476 Significant performance improvement when using multiple label filters (
v1.8.10 (April 2023)
This is a maintenance release for RedisTimeSeries 1.8.
Update urgency: MODERATE: Program an upgrade of the server, but it's not urgent.
Details:
-
Bug fixes:
- #1455
TS.ADD- optional arguments are not replicated (MOD-5110)
- #1455
v1.8.9 (March 2023)
This is a maintenance release for RedisTimeSeries 1.8.
Update urgency: MODERATE: Program an upgrade of the server, but it's not urgent.
Details:
-
Bug fixes:
v1.8.8 (March 2023)
This is a maintenance release for RedisTimeSeries 1.8
Update urgency: MODERATE: Program an upgrade of the server, but it's not urgent.
Details:
-
Bug fixes:
v1.8.5 (January 2023)
This is a maintenance release for RedisTimeSeries 1.8.
Update urgency: HIGH: There is a critical bug that may affect a subset of users. Upgrade!
Details:
-
Bug fixes:
- #1388 Potential crash when upgrading from v1.6 to 1.8 if there are compactions with
minormaxaggregation (MOD-4695)
- #1388 Potential crash when upgrading from v1.6 to 1.8 if there are compactions with
v1.8.4 (December 2022)
This is a maintenance release for RedisTimeSeries 1.8.
Update urgency: HIGH: There is a critical bug that may affect a subset of users. Upgrade!
Details:
-
Bug fixes:
- #1360 Potential crash when upgrading from v1.6 to 1.8 if there are compactions with
minormaxaggregation (MOD-4559) - #1370 Potential crash when using TS.REVRANGE or TS.MREVRANGE with aggregation
- #1347 When adding samples with TS.ADD or TS.MADD using
*as timestamp, the timestamp could differ between master and replica shards
- #1360 Potential crash when upgrading from v1.6 to 1.8 if there are compactions with
-
Improvements:
- #1215 OSS cluster: Support TLS and IPv6; introduce new configuration parameter: OSS_GLOBAL_PASSWORD
v1.8 GA (v1.8.3) (November 2022)
This is the General Availability release of RedisTimeSeries 1.8.
Highlights
RedisTimeSeries 1.8 introduces seven highly requested features, performance improvements, and bug fixes.
What's new in 1.8
-
Optionally retrieving aggregation results for the latest (still open) bucket for compactions
Till version 1.8, when a time series is a compaction, TS.GET, TS.MGET, TS.RANGE, TS.REVRANGE, TS.MRANGE, TS.MREVRANGE did not report the compacted value of the latest bucket. The reason is that the data in the latest bucket of a compaction is still partial. A bucket is ‘closed’ and compacted only upon the arrival of data that ‘opens’ a ‘new latest’ bucket.
There are use cases, however, where the compaction of the latest bucket should be retrieved as well. For example, a user may want to receive the count of events since the start of the decade, and the retention period for raw data is only one month. Till version 1.8, the user would have to run two queries - one on a compaction and one on the latest raw data, and then sum the results. Since version 1.8, by specifying
LATEST, it is possible to retrieve the latest (possibly partial) bucket as well.To report aggregations for the latest bucket, use the new optional
LATESTflag to TS.GET, TS.MGET, TS.RANGE, TS.REVRANGE, TS.MRANGE, and TS.REVRANGE. -
Optionally retrieving aggregation results for empty buckets
The commands TS.RANGE, TS.REVRANGE, TS.MRANGE, and TS.MREVRANGE have an optional
[AGGREGATION aggregator bucketDuration]parameter. When this parameter is specified, raw reports are aggregated per bucket.Till version 1.8, results were not reported for empty buckets. With
EMPTY, it is now possible to report aggregations for empty buckets as well.The two primary reasons for wanting to retrieve values for empty buckets:
-
It is easier to align results from similar queries over multiple time series
-
It is easier to use the retrieved results with some external tools (e.g., charting tools)
For the
sumandcountaggregators, the value 0 is reported for empty buckets.For the
min,max,range,avg,first,std.p, andstd.saggregators, the value NaN (not a number) is reported.For the
lastaggregator and the newtwaaggregator, theEMPTYflag is used for gap filling (see below).To report aggregations for empty buckets, use the new optional
EMPTYflag in TS.RANGE, TS.REVRANGE, TS.MRANGE, and TS.MREVRANGE.Regardless of the values of
fromTimestampandtoTimestamp, no data is reported for empty buckets that end before the earliest sample or begin after the latest sample in the time series. -
-
A new aggregator: time-weighted average
When a time series holds discrete samples of a continuous signal (e.g., temperature), using
avgto estimate the average value over a given timeframe would produce a good estimate only when the signal is sampled at constant intervals. If, however, samples are available at non-constant intervals (e.g., when some samples are missing), thetwaaggregator produces a more accurate estimate by averaging samples over time instead of simply averaging the samples.
This is an extreme example: the signal in the diagram above has 4 samples in its ‘high’ value and 13 samples in its ‘low’ value. However, the period in each of those states is about the same. It is easy to see that the simple average (avg) of all the 17 samples does not represent the signal’s average over time.
Time-weighted average (
twa) adds weight to each sample. The weight is proportional to the time interval that the sample represents. In the diagram, the time-weighted average over the whole period assigns appropriate weight to each sample, so the result represents the signal’s average value over the whole period much more accurately. -
Gap filling: optionally interpolate or repeat last value for empty buckets
Gap filling is performed when using
EMPTYtogether with eitherlastortwaaggregator.Using
EMPTYwith thetwaaggregator allows us to estimate the average of a continuous signal even for buckets where no samples were collected (gap-filling).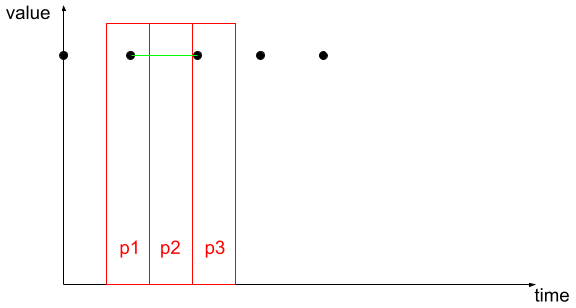
Consider we want to use TS.RANGE to calculate the average value of each bucket (p1, p2, p3 in the diagram above). Using avg, the value reported for bucket p2 would be NaN, as this bucket contains no samples. If we use
EMPTYwithtwa, on the other hand, the average value for bucket p2 would be calculated based on the linear interpolation of the value left of p2 and the value right of p2.When sampling a continuous signal, we can use this ‘gap-filling’ capability to calculate the average value of the signal over equal-width buckets without concern about bucket alignment or missing samples.
Using
EMPTYwith the last aggregator allows filling empty buckets by repeating the value of the previous sample. This is useful, for example, when values in the time series represent stock prices and the price has not been changed during a bucket’s timeframe. -
Ability to control how bucket timestamps are reported
Till version 1.8, TS.RANGE, TS.REVRANGE, TS.MRANGE, and TS.MREVRANGE returned the start time of each reported bucket as its timestamp.
Changing this behavior and reporting each bucket’s start time, end time, or mid-time is now possible. This is required in many use cases. For example, when drawing bars in trading applications, annotating each bar with the end timestamp of the bucket it represents is very common.
The way bucket timestamps are reported can be specified with the new optional
BUCKETTIMESTAMPparameter of TS.RANGE, TS.REVRANGE, TS.MRANGE, and TS.MREVRANGE.-orlow: the bucket's start time (default)+orhigh: the bucket's end time~ormid: the bucket's mid-time (rounded down if not an integer) -
Ability to control alignment for compaction rules
Till version 1.8, compaction rules could not be aligned. One could specify a compaction rule with 24-hour buckets, and as a result, each bucket would aggregate events from midnight till the next midnight. The first bucket always started at the epoch and all other buckets were aligned accordingly.
But what if we want to aggregate daily events from 06:00 to 06:00 the next day? We can now specify alignment for compaction rules.
Alignment can be specified with the new optional
alignTimestampparameter of TS.CREATERULE and the COMPACTION_POLICY configuration parameter. SpecifyingalignTimestampensures that there is a bucket that starts exactly atalignTimestampand all other buckets are aligned accordingly.alignTimestampis expressed in milliseconds. The default value is 0 (aligned with the epoch). -
New reducers
Till version 1.8, only the
sum,min, andmaxcould be used as reducer types.It is now possible, for example, to calculate the maximal temperature per timeframe for each sensor and then report the average temperature (avg reducer) over groups of sensors (grouped by a given label's value).
This can be specified with the new reducer types (TS.MRANGE and TS.MREVRANGE:
avg,range,count,std.p,std.s,var.p, andvar.s.