Tutorial
How to use Redis for Query Caching
February 25, 202610 minute read


TL;DR:To implement query caching with Redis, use the cache-aside pattern: hash your query parameters to form a cache key, check Redis first, return cached data on a hit, or query the primary database on a miss and store the result in Redis with a TTL. This reduces database load and speeds up read-heavy workloads like product search in e-commerce apps.
#What you'll learn
- What query caching is and when to use it
- What the cache-aside pattern is and how it differs from cache prefetching
- How to implement cache-aside with Redis and a primary database
- How to structure a microservices e-commerce app with Redis caching
- Best practices for cache expiration and invalidation
#What is query caching?
Have you ever been in a situation where your database queries are slowing down? Query caching is the technique you need to speed database queries by using different caching methods while keeping costs down! Imagine that you built an e-commerce application. It started small but is growing fast. By now, you have an extensive product catalog and millions of customers.
That's good for business, but a hardship for technology. Your queries to primary database (MongoDB/ Postgressql) are beginning to slow down, even though you already attempted to optimize them. Even though you can squeak out a little extra performance, it isn't enough to satisfy your customers.
#Why should you use Redis for query caching?
Redis is an in-memory datastore, best known for caching. Redis allows you to reduce the load on a primary database while speeding up database reads.
With any e-commerce application, there is one specific type of query that is most often requested. If you guessed that it's the product search query, you're correct!
To improve product search in an e-commerce application, you can implement one of following caching patterns:
- Cache prefetching: An entire product catalog can be pre-cached in Redis, and the application can perform any product query on Redis similar to the primary database.
- Cache-aside pattern: Redis is filled on demand, based on whatever search parameters are requested by the frontend.
TIPIf you use Redis Cloud, cache aside is easier due to its support for JSON and search. You also get additional features such as real-time performance, High scalability, resiliency, and fault tolerance. You can also call upon high-availability features such as Active-Active geo-redundancy.
#What is the cache-aside pattern?
The cache-aside pattern (also called lazy loading) is a caching strategy where the application is responsible for reading and writing to both the cache and the database. Unlike a read-through cache where the cache itself manages database lookups, cache-aside gives the application full control over when data enters the cache.
The goal of this design pattern is to set up optimal caching (load-as-you-go) for better read operations. The cache is populated on demand: when data is requested and not found in the cache (a cache miss), the application fetches it from the database and stores it in Redis. When the same data is requested again and found in the cache (a cache hit), it's returned directly from Redis without touching the database.
This tutorial focuses on the cache-aside pattern. Let's look at how it works with Redis for both a cache miss and a cache hit.
#How does cache-aside work on a cache miss?
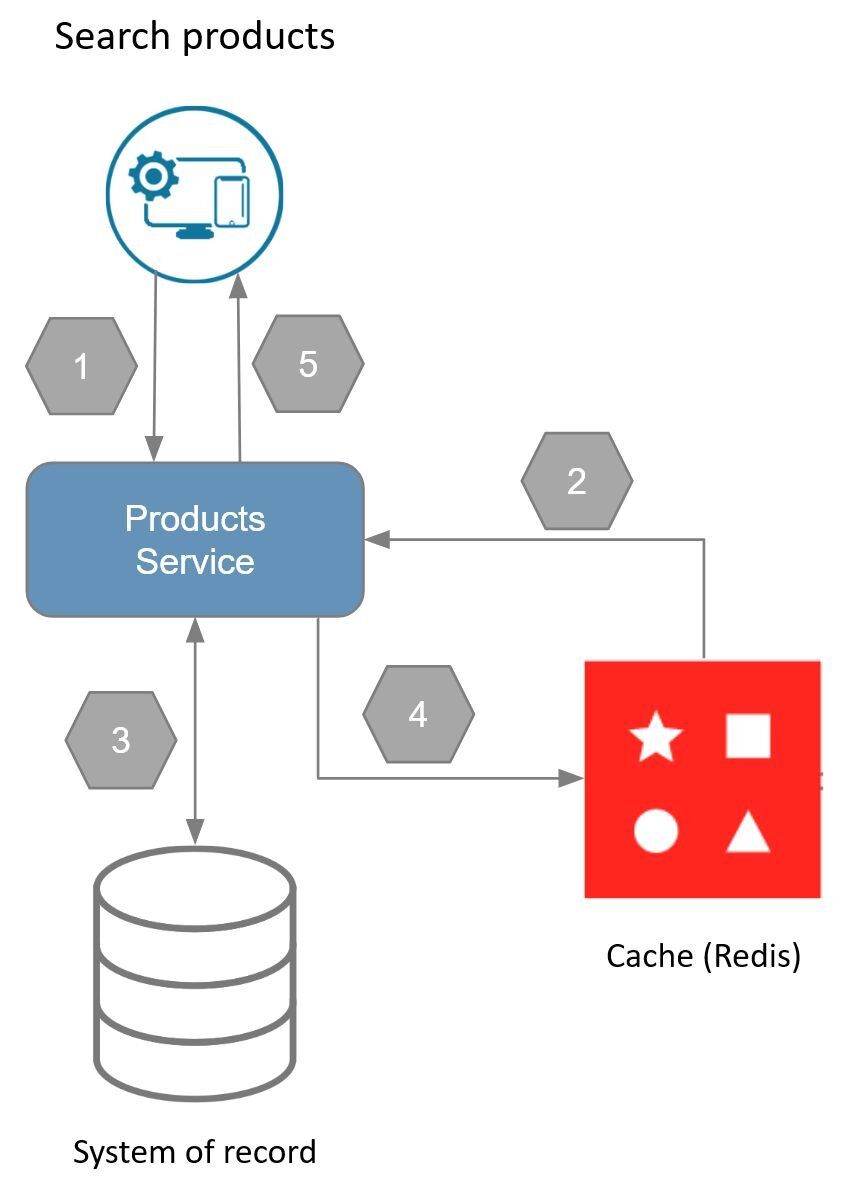
This diagram illustrates the steps taken in the cache-aside pattern when there is a cache miss. To understand how this works, consider the following process:
- An application requests data from the backend.
- The backend checks to find out if the data is available in Redis.
- Data is not found (a cache miss), so the data is fetched from the database.
- The data returned from the database is subsequently stored in Redis.
- The data is then returned to the application.
#How does cache-aside work on a cache hit?
Now that you have seen what a cache miss looks like, let's cover a cache hit. Here is the same diagram, but with the cache hit steps highlighted in green.
- An application requests data from the backend.
- The backend checks to find out if the data is available in Redis.
- The data is then returned to the application.
#When should you use the cache-aside pattern?
The cache-aside pattern is useful when you need to:
- Query data frequently: When you have a large volume of reads (as is the case in an e-commerce application), the cache-aside pattern gives you an immediate performance gain for subsequent data requests.
- Fill the cache on demand: The cache-aside pattern fills the cache as data is requested rather than pre-caching, thus saving on space and cost. This is useful when it isn't clear what data will need to be cached.
- Be cost-conscious: Since cache size is directly related to the cost of cache storage in the cloud, the smaller the size, the less you pay.
TIPIf you use Redis Cloud and a database that uses a JDBC driver, you can take advantage of Redis Smart Cache, which lets you add caching to an application without changing the code. Click here to learn more!
#What does the microservices architecture look like?
The e-commerce microservices application discussed in the rest of this tutorial uses the following architecture:
products service: handles querying products from the database and returning them to the frontendorders service: handles validating and creating ordersorder history service: handles querying a customer's order historypayments service: handles processing orders for paymentdigital identity service: handles storing digital identity and calculating identity scoreapi gateway: unifies services under a single endpointmongodb/ postgresql: serves as the primary database, storing orders, order history, products, etc.redis: serves as the stream processor and caching database
INFOYou don't need to use MongoDB/ Postgresql as your primary database in the demo application; you can use other prisma supported databases as well. This is just an example.
#What does the e-commerce frontend look like?
The e-commerce microservices application consists of a frontend, built using Next.js with TailwindCSS. The application backend uses Node.js. The data is stored in Redis and MongoDB/ Postgressql using Prisma. Below you will find screenshots of the frontend of the e-commerce app:
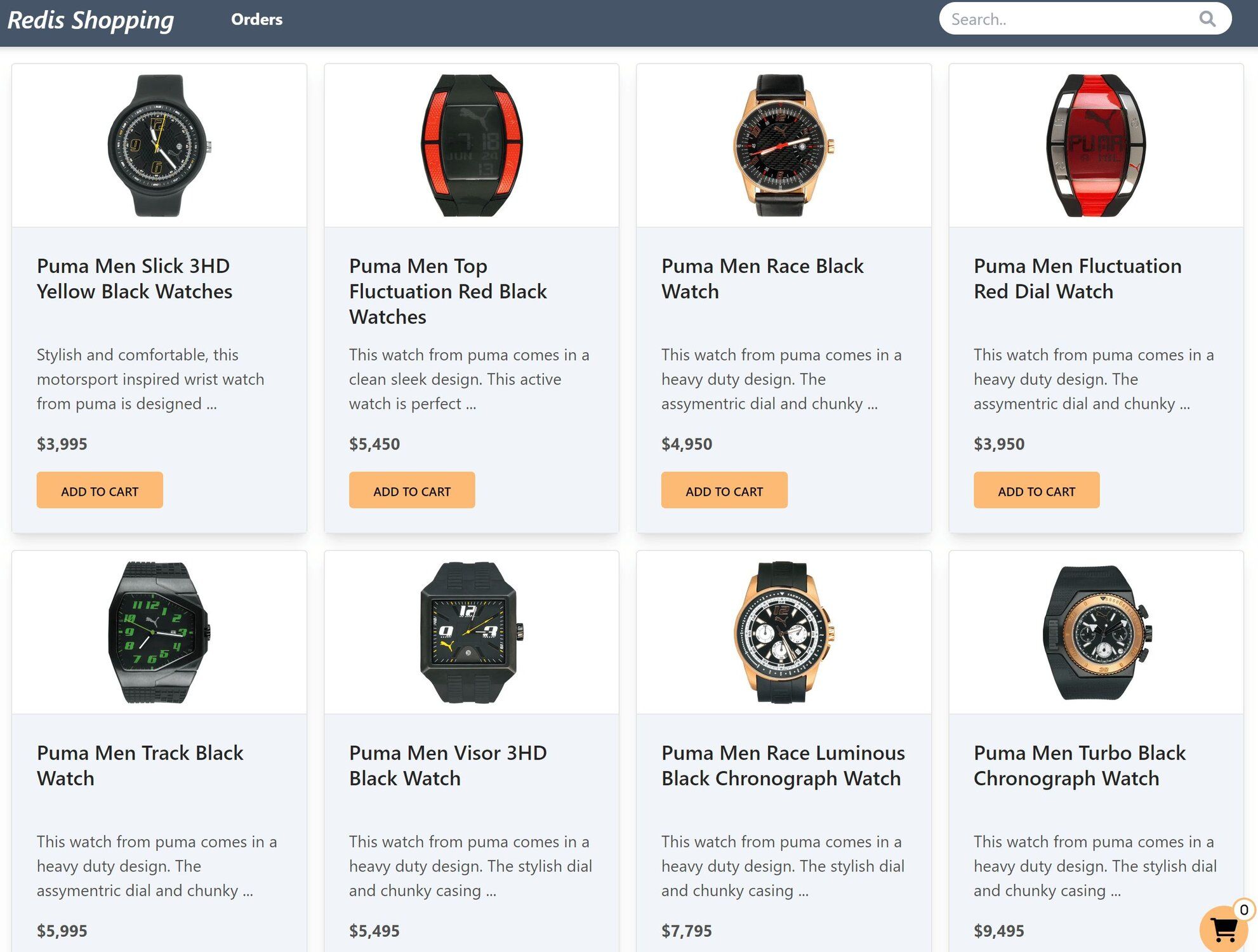
Dashboard: Shows the list of products with search functionality
Shopping Cart: Add products to the cart, then check out using the "Buy Now" button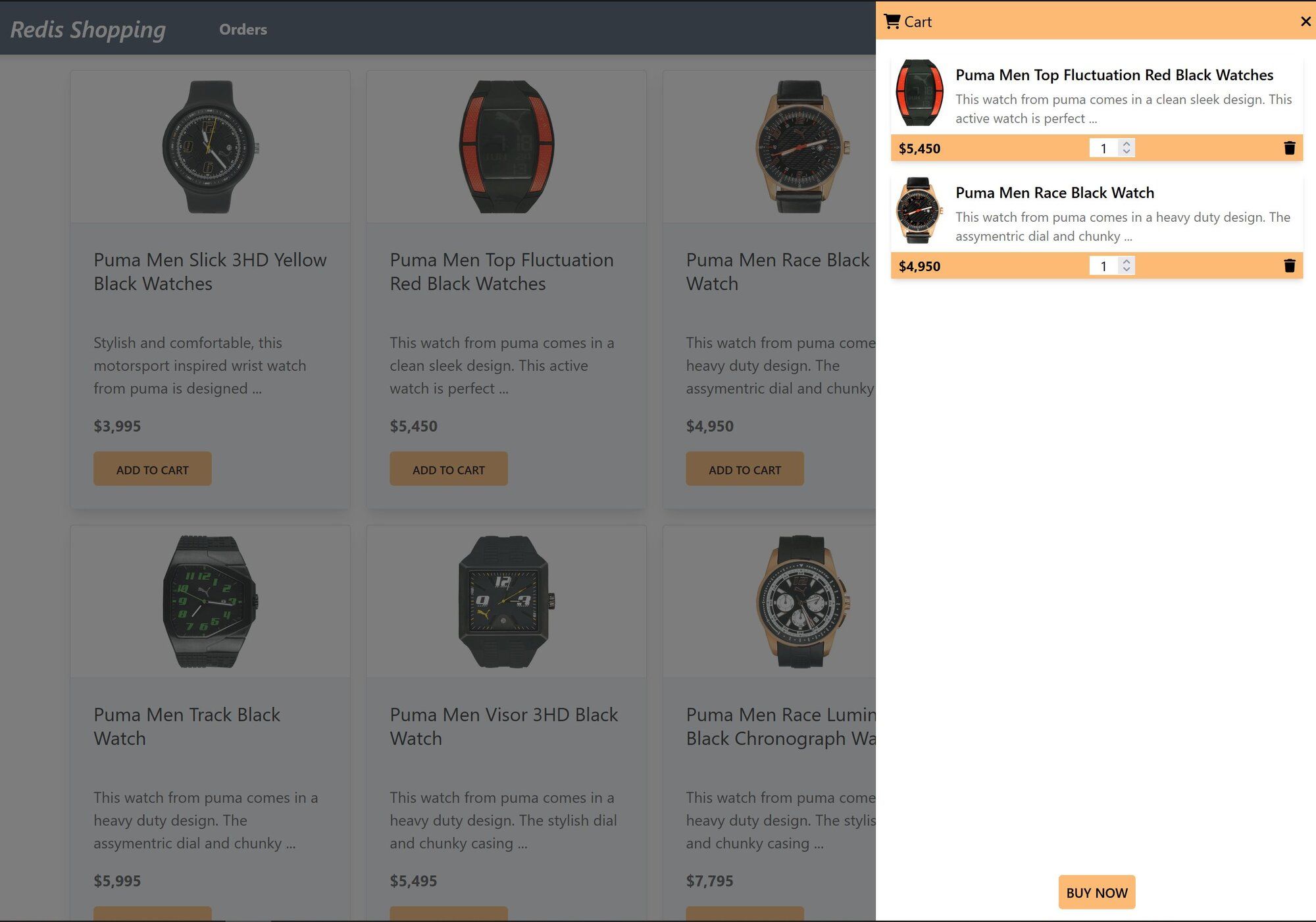
NOTEBelow is a command to the clone the source code for the application used in this tutorialgit clone --branch v4.2.0 https://github.com/redis-developer/redis-microservices-ecommerce-solutions
#How do you implement caching in a microservices application?
In our sample application, the products service publishes an API for filtering products. Here's what a call to the API looks like:
#What does the product filter API look like?
#What does the response look like on a cache miss?
#What does the response look like on a cache hit?
#How do you implement cache-aside with Redis?
The following code shows the function used to search for products in primary database:
You simply make a call to primary database (MongoDB/ Postgressql) to find products based on a filter on the product's
displayName property. You can set up multiple columns for better fuzzy searching, but we simplified it for the purposes of this tutorial.Using primary database directly without Redis works for a while, but eventually it slows down. That's why you might use Redis, to speed things up. The cache-aside pattern helps you balance performance with cost.
The basic decision tree for cache-aside is as follows.
When the frontend requests products:
- Form a hash with the contents of the request (i.e., the search parameters).
- Check Redis to see if a value exists for the hash.
- Is there a cache hit? If data is found for the hash, it is returned; the process stops here.
- Is there a cache miss? When data is not found, it is read out of primary database and subsequently stored in Redis prior to being returned.
Here's the code used to implement the decision tree:
TIPYou need to decide what expiry or time to live (TTL) works best for your particular use case.
#Next steps
You now know how to use Redis for query caching with one of the most common caching patterns (cache-aside). It's possible to incrementally adopt Redis wherever needed with different strategies and patterns. Here are some ways to continue building on what you've learned:
- Add API gateway caching: Combine query caching with API gateway caching to cache responses at the gateway level and reduce load on individual microservices.
- Try cache prefetching: For data that you know will be needed, cache prefetching can pre-load your Redis cache so that first requests are also fast.
- Explore other microservices patterns: Learn how Redis supports CQRS and interservice communication in distributed architectures.
#Additional resources
- Redis YouTube channel
- Clients like Node Redis and Redis om Node help you to use Redis in Node.js apps.
- Redis Insight: To view your Redis data or to play with raw Redis commands in the workbench
- Try Redis Cloud for free